 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProof Flow: Preliminary Study on Generative Flow Network Language Model Tuning for Formal Reasoning
Paper and Code



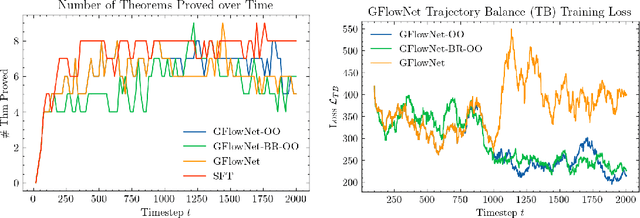
Reasoning is a fundamental substrate for solving novel and complex problems. Deliberate efforts in learning and developing frameworks around System 2 reasoning have made great strides, yet problems of sufficient complexity remain largely out of reach for open models. To address this gap, we examine the potential of Generative Flow Networks as a fine-tuning method for LLMs to unlock advanced reasoning capabilities. In this paper, we present a proof of concept in the domain of formal reasoning, specifically in the Neural Theorem Proving (NTP) setting, where proofs specified in a formal language such as Lean can be deterministically and objectively verified. Unlike classical reward-maximization reinforcement learning, which frequently over-exploits high-reward actions and fails to effectively explore the state space, GFlowNets have emerged as a promising approach for sampling compositional objects, improving generalization, and enabling models to maintain diverse hypotheses. Our early results demonstrate GFlowNet fine-tuning's potential for enhancing model performance in a search setting, which is especially relevant given the paradigm shift towards inference time compute scaling and "thinking slowly."