 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolution Fine-Tuning: Learning to Discover Across 371 Optimization Tasks
Jun 27, 2026Would experience designing faster GPU kernels also help close in on a long-standing open mathematical conjecture? Large Language Models (LLMs) integrated into evolutionary search have recently produced state-of-the-art solutions on optimization tasks, including open mathematical conjectures, GPU kernel design, scientific law discovery, and combinatorial puzzles. To achieve this, prior work applied search scaffolds to one target task at a time, so every new problem is approached from scratch and the experience accumulated during search is discarded once the model finishes its attempt. This leaves the capability of iteratively evolving a solution (e.g., knowing which part to mutate and how, deciding when to backtrack) entirely in the scaffold rather than in the model itself. Whether the model itself could acquire this capability and reuse it across different tasks has been largely unexamined. To address this, we introduce Evolution Fine-Tuning (EFT), a mid-training paradigm that teaches LLMs to evolve solutions across tasks by converting evolutionary search trajectories into supervision. We construct Finch Collection, a 156K-trajectory dataset spanning 10 domains and 371 optimization tasks, and fine-tune open-source LLMs from 2B to 9B parameters. Empirically, EFT confers cross-task generalization: across 22 held-out tasks, our models surpass their base counterparts by 10.22% on average. Furthermore, when paired with test-time RL, our model matches state-of-the-art performance on two circle-packing tasks and outperforms its base-model counterpart on the Erdős minimum-overlap problem. EFT thus serves as a "practice phase" for general-purpose discovery agents that do not solve new problems from scratch.
Zone of Proximal Policy Optimization: Teacher in Prompts, Not Gradients
Jun 16, 2026Knowledge distillation transfers a teacher's competence to a small student but is brittle in the small-student regime: forcing the student to imitate logits from a much larger teacher concentrates it on the teacher's sharpest modes, hurting generalization on benchmark families beyond the training corpus. Reinforcement learning (RL) avoids logit imitation by training on the student's own rollouts. However, on questions where every rollout fails-yielding zero advantage and being silently discarded-injecting a stronger teacher's response into the policy gradient breaks the on-policy assumption and induces drift. We introduce Zone of Proximal Policy Optimization (ZPPO), inspired by Vygotsky's zone of proximal development, which keeps the teacher inside the prompt rather than the policy gradient. On hard questions, ZPPO constructs two reformulated prompts: a Binary Candidate-included Question (BCQ) pairs one correct teacher response with one incorrect student response as anonymized candidates the student must discriminate, and a Negative Candidate-included Question (NCQ) aggregates the student's wrong rollouts into a single prompt to surface their shared failure modes. A prompt replay buffer recirculates each hard question until it either graduates-the student's mean rollout accuracy on it reaches half- or is FIFO-evicted under finite capacity, amplifying BCQ and NCQ inside the student's current zone of proximal development. On the Qwen3.5 family at four student scales (0.8B-9B) with a 27B teacher, post-trained as vision-language models and evaluated on a 31-benchmark suite (16 VLM, 10 LLM, 5 Video), ZPPO outperforms off/on-policy distillation and GRPO, with the largest gains at the smallest scale.
TIDE: Proactive Multi-Problem Discovery via Template-Guided Iteration
Jun 03, 2026Agents are widely deployed as assistants over documents, tools, and code. However, they typically act only on explicit user requests, which surface only the problems the user has noticed, while many other important problems coexist, hidden in plain sight, within the broader user context, with their total number unknown in advance. We frame this as the task of discovering multiple hidden problems from context, in which coexisting problems should be uncovered, grounded in supporting evidence, and paired with concrete actions. To this end, we introduce TIDE, a template-guided iterative framework with two complementary mechanisms. Specifically, motivated by the observation that single-pass prediction anchors on the most salient cases and yields generic claims, we propose iterative discovery, which surfaces a small batch of candidates per round while conditioning on what has already been found, so subsequent rounds extend coverage; and thought templates, reusable schemas distilled from previously solved cases that specify what contextual signals to attend to and how to connect them, anchoring each prediction in a recognizable problem class. We validate TIDE on two realistic settings, personal workspaces and software repositories, across four model backbones, showing substantial gains over single-shot and parallel multi-agent baselines on task coverage, identification, and resolution.
OmniRetrieval: Unified Retrieval across Heterogeneous Knowledge Sources
May 28, 2026Real-world information needs require access to structurally diverse knowledge sources, from unstructured text and relational tables to knowledge graphs and property graphs. Existing retrievers, however, operate over one source at a time under a fixed query language, leaving the broader landscape of available knowledge fragmented behind incompatible interfaces. A natural attempt at unification would collapse these sources into a shared space, but this erases the structural affordances (such as schemas, ontologies, compositional operators) that give each source its expressive power. Effective retrieval over diverse knowledge, therefore, requires not homogenization but an overarching layer that meets each source on its own terms. To achieve this, we present OmniRetrieval, a framework that takes any natural-language query, identifies appropriate knowledge sources, and dispatches source-native queries to their native execution engines. Across an extensive benchmark spanning 13 datasets and 309 distinct knowledge bases over text, relational, and graph-structured sources, OmniRetrieval exceeds single-source baselines, demonstrating that it can serve as a general-purpose interface to the heterogeneous sources while preserving the structural distinctions that make each source valuable.
Agent Explorative Policy Optimization for Multimodal Agentic Reasoning
May 27, 2026Vision-language models with extended reasoning succeed on complex problems, but many real-world problems require external tools that internal reasoning alone often cannot resolve. Agentic reasoning therefore interleaves two behaviors with a structural asymmetry: thinking (the self-contained default) and tool use (a high-variance auxiliary acting). We refer to this asymmetry as the Thinking-Acting Gap. Under standard RL recipes like GRPO, the gap manifests as two diagnostic symptoms during training: tool use is attempted on only ~30% of rollouts, and when attempted, the tool-using rollouts within a group are all-wrong on ~40% of questions, suppressing the learning signal at the tool calls that needed it. We propose AXPO (Agent eXplorative Policy Optimization): for each all-wrong tool-using subgroup, AXPO fixes the thinking prefix and resamples the tool call and its continuation, paired with uncertainty-based prefix selection. Across nine multimodal benchmarks and three scales of Qwen3-VL-Thinking, SFT+AXPO outperforms SFT+GRPO at average (+1.8pp Pass@1 and +1.8pp Pass@4 at 8B on average) and 8B with SFT+AXPO surpasses the 32B Base on Pass@4 with 4 times fewer parameters.
Memory Transfer Learning: How Memories are Transferred Across Domains in Coding Agents
Apr 15, 2026Memory-based self-evolution has emerged as a promising paradigm for coding agents. However, existing approaches typically restrict memory utilization to homogeneous task domains, failing to leverage the shared infrastructural foundations, such as runtime environments and programming languages, that exist across diverse real-world coding problems. To address this limitation, we investigate \textbf{Memory Transfer Learning} (MTL) by harnessing a unified memory pool from heterogeneous domains. We evaluate performance across 6 coding benchmarks using four memory representations, ranging from concrete traces to abstract insights. Our experiments demonstrate that cross-domain memory improves average performance by 3.7\%, primarily by transferring meta-knowledge, such as validation routines, rather than task-specific code. Importantly, we find that abstraction dictates transferability; high-level insights generalize well, whereas low-level traces often induce negative transfer due to excessive specificity. Furthermore, we show that transfer effectiveness scales with the size of the memory pool, and memory can be transferred even between different models. Our work establishes empirical design principles for expanding memory utilization beyond single-domain silos. Project page: https://memorytransfer.github.io/
THINKSAFE: Self-Generated Safety Alignment for Reasoning Models
Jan 30, 2026Large reasoning models (LRMs) achieve remarkable performance by leveraging reinforcement learning (RL) on reasoning tasks to generate long chain-of-thought (CoT) reasoning. However, this over-optimization often prioritizes compliance, making models vulnerable to harmful prompts. To mitigate this safety degradation, recent approaches rely on external teacher distillation, yet this introduces a distributional discrepancy that degrades native reasoning. We propose ThinkSafe, a self-generated alignment framework that restores safety alignment without external teachers. Our key insight is that while compliance suppresses safety mechanisms, models often retain latent knowledge to identify harm. ThinkSafe unlocks this via lightweight refusal steering, guiding the model to generate in-distribution safety reasoning traces. Fine-tuning on these self-generated responses effectively realigns the model while minimizing distribution shift. Experiments on DeepSeek-R1-Distill and Qwen3 show ThinkSafe significantly improves safety while preserving reasoning proficiency. Notably, it achieves superior safety and comparable reasoning to GRPO, with significantly reduced computational cost. Code, models, and datasets are available at https://github.com/seanie12/ThinkSafe.git.
Rethinking Reward Models for Multi-Domain Test-Time Scaling
Oct 02, 2025The reliability of large language models (LLMs) during test-time scaling is often assessed with \emph{external verifiers} or \emph{reward models} that distinguish correct reasoning from flawed logic. Prior work generally assumes that process reward models (PRMs), which score every intermediate reasoning step, outperform outcome reward models (ORMs) that assess only the final answer. This view is based mainly on evidence from narrow, math-adjacent domains. We present the first unified evaluation of four reward model variants, discriminative ORM and PRM (\DisORM, \DisPRM) and generative ORM and PRM (\GenORM, \GenPRM), across 14 diverse domains. Contrary to conventional wisdom, we find that (i) \DisORM performs on par with \DisPRM, (ii) \GenPRM is not competitive, and (iii) overall, \GenORM is the most robust, yielding significant and consistent gains across every tested domain. We attribute this to PRM-style stepwise scoring, which inherits label noise from LLM auto-labeling and has difficulty evaluating long reasoning trajectories, including those involving self-correcting reasoning. Our theoretical analysis shows that step-wise aggregation compounds errors as reasoning length grows, and our empirical observations confirm this effect. These findings challenge the prevailing assumption that fine-grained supervision is always better and support generative outcome verification for multi-domain deployment. We publicly release our code, datasets, and checkpoints at \href{https://github.com/db-Lee/Multi-RM}{\underline{\small\texttt{https://github.com/db-Lee/Multi-RM}}} to facilitate future research in multi-domain settings.
ACON: Optimizing Context Compression for Long-horizon LLM Agents
Oct 01, 2025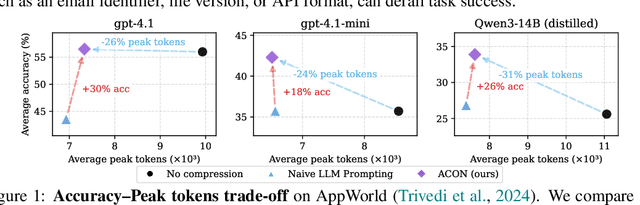
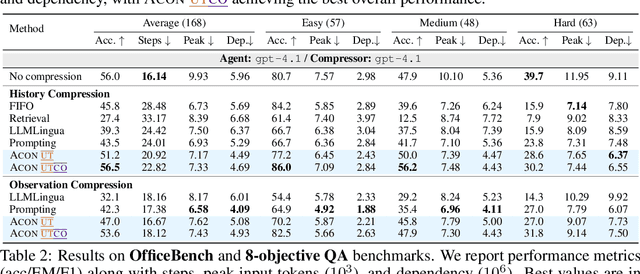
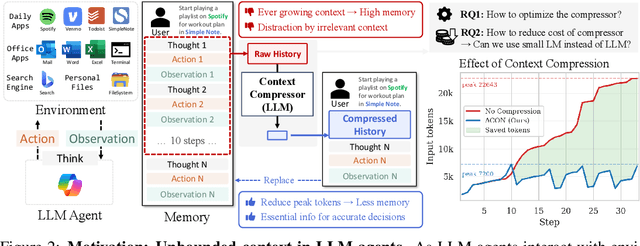
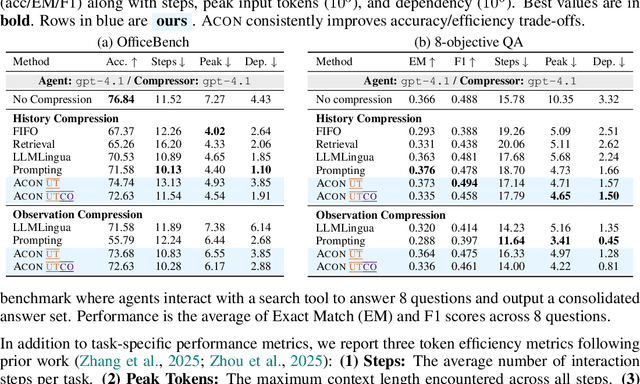
Large language models (LLMs) are increasingly deployed as agents in dynamic, real-world environments, where success requires both reasoning and effective tool use. A central challenge for agentic tasks is the growing context length, as agents must accumulate long histories of actions and observations. This expansion raises costs and reduces efficiency in long-horizon tasks, yet prior work on context compression has mostly focused on single-step tasks or narrow applications. We introduce Agent Context Optimization (ACON), a unified framework that optimally compresses both environment observations and interaction histories into concise yet informative condensations. ACON leverages compression guideline optimization in natural language space: given paired trajectories where full context succeeds but compressed context fails, capable LLMs analyze the causes of failure, and the compression guideline is updated accordingly. Furthermore, we propose distilling the optimized LLM compressor into smaller models to reduce the overhead of the additional module. Experiments on AppWorld, OfficeBench, and Multi-objective QA show that ACON reduces memory usage by 26-54% (peak tokens) while largely preserving task performance, preserves over 95% of accuracy when distilled into smaller compressors, and enhances smaller LMs as long-horizon agents with up to 46% performance improvement.
Distilling LLM Agent into Small Models with Retrieval and Code Tools
May 23, 2025Large language models (LLMs) excel at complex reasoning tasks but remain computationally expensive, limiting their practical deployment. To address this, recent works have focused on distilling reasoning capabilities into smaller language models (sLMs) using chain-of-thought (CoT) traces from teacher LLMs. However, this approach struggles in scenarios requiring rare factual knowledge or precise computation, where sLMs often hallucinate due to limited capability. In this work, we propose Agent Distillation, a framework for transferring not only reasoning capability but full task-solving behavior from LLM-based agents into sLMs with retrieval and code tools. We improve agent distillation along two complementary axes: (1) we introduce a prompting method called first-thought prefix to enhance the quality of teacher-generated trajectories; and (2) we propose a self-consistent action generation for improving test-time robustness of small agents. We evaluate our method on eight reasoning tasks across factual and mathematical domains, covering both in-domain and out-of-domain generalization. Our results show that sLMs as small as 0.5B, 1.5B, 3B parameters can achieve performance competitive with next-tier larger 1.5B, 3B, 7B models fine-tuned using CoT distillation, demonstrating the potential of agent distillation for building practical, tool-using small agents. Our code is available at https://github.com/Nardien/agent-distillation.