 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Paraphrasing: Perturbation on Layers Improves Knowledge Injection in Language Models
Nov 01, 2024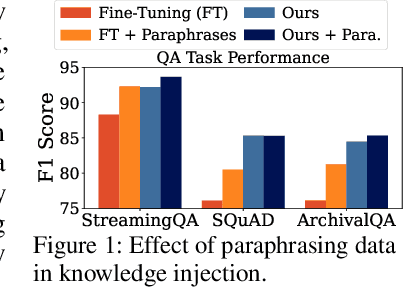

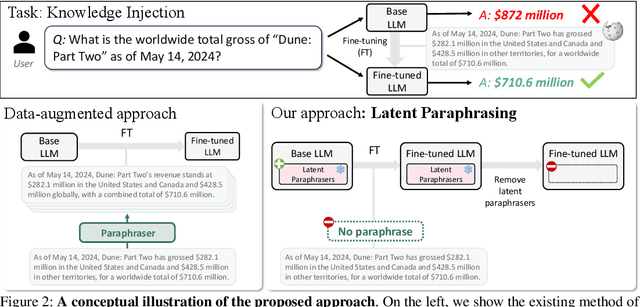
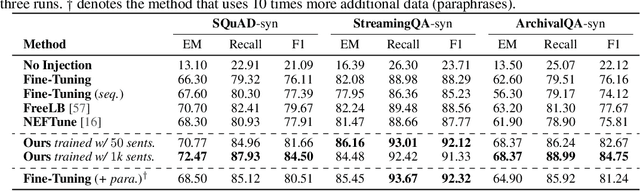
As Large Language Models (LLMs) are increasingly deployed in specialized domains with continuously evolving knowledge, the need for timely and precise knowledge injection has become essential. Fine-tuning with paraphrased data is a common approach to enhance knowledge injection, yet it faces two significant challenges: high computational costs due to repetitive external model usage and limited sample diversity. To this end, we introduce LaPael, a latent-level paraphrasing method that applies input-dependent noise to early LLM layers. This approach enables diverse and semantically consistent augmentations directly within the model. Furthermore, it eliminates the recurring costs of paraphrase generation for each knowledge update. Our extensive experiments on question-answering benchmarks demonstrate that LaPael improves knowledge injection over standard fine-tuning and existing noise-based approaches. Additionally, combining LaPael with data-level paraphrasing further enhances performance.
A Simple Framework to Accelerate Multilingual Language Model for Monolingual Text Generation
Jan 19, 2024



Recent advancements in large language models have facilitated the execution of complex language tasks, not only in English but also in non-English languages. However, the tokenizers of most language models, such as Llama, trained on English-centric corpora, tend to excessively fragment tokens in non-English languages. This issue is especially pronounced in non-roman alphabetic languages, which are often divided at a character or even Unicode level, leading to slower text generation. To address this, our study introduces a novel framework designed to expedite text generation in these languages. This framework predicts larger linguistic units than those of conventional multilingual tokenizers and is specifically tailored to the target language, thereby reducing the number of decoding steps required. Our empirical results demonstrate that the proposed framework increases the generation speed by a factor of 1.9 compared to standard decoding while maintaining the performance of a pre-trained multilingual model on monolingual tasks.
Predictive Pipelined Decoding: A Compute-Latency Trade-off for Exact LLM Decoding
Jul 12, 2023



This paper presents "Predictive Pipelined Decoding (PPD)," an approach that speeds up greedy decoding in Large Language Models (LLMs) while maintaining the exact same output as the original decoding. Unlike conventional strategies, PPD employs additional compute resources to parallelize the initiation of subsequent token decoding during the current token decoding. This innovative method reduces decoding latency and reshapes the understanding of trade-offs in LLM decoding strategies. We have developed a theoretical framework that allows us to analyze the trade-off between computation and latency. Using this framework, we can analytically estimate the potential reduction in latency associated with our proposed method, achieved through the assessment of the match rate, represented as p_correct. The results demonstrate that the use of extra computational resources has the potential to accelerate LLM greedy decoding.
Prompted LLMs as Chatbot Modules for Long Open-domain Conversation
May 08, 2023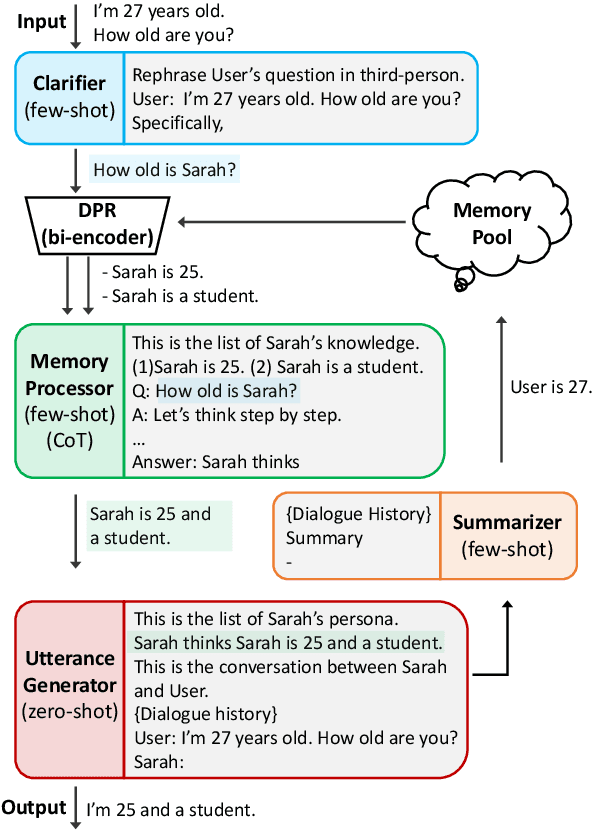
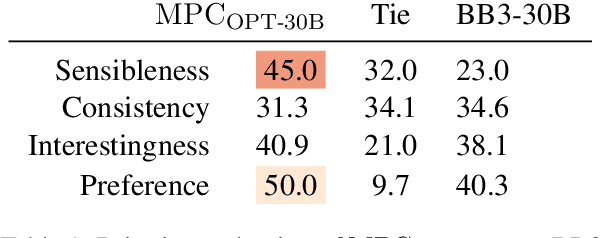
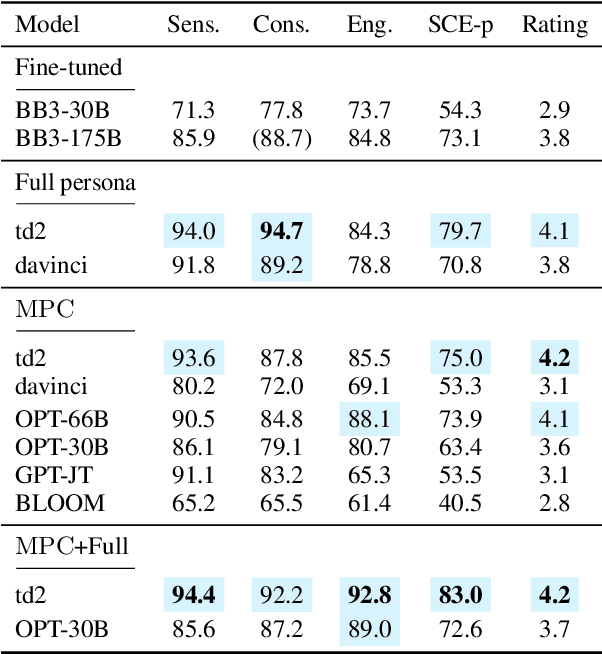
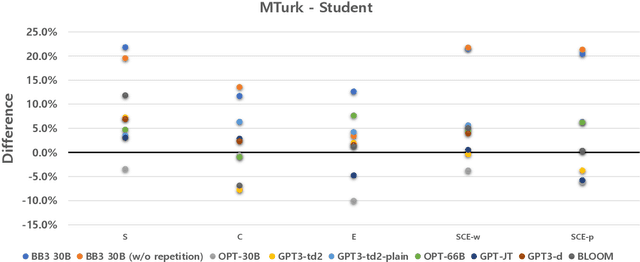
In this paper, we propose MPC (Modular Prompted Chatbot), a new approach for creating high-quality conversational agents without the need for fine-tuning. Our method utilizes pre-trained large language models (LLMs) as individual modules for long-term consistency and flexibility, by using techniques such as few-shot prompting, chain-of-thought (CoT), and external memory. Our human evaluation results show that MPC is on par with fine-tuned chatbot models in open-domain conversations, making it an effective solution for creating consistent and engaging chatbots.