 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTS-Debate: Multimodal Collaborative Debate for Zero-Shot Time Series Reasoning
Jan 27, 2026Recent progress at the intersection of large language models (LLMs) and time series (TS) analysis has revealed both promise and fragility. While LLMs can reason over temporal structure given carefully engineered context, they often struggle with numeric fidelity, modality interference, and principled cross-modal integration. We present TS-Debate, a modality-specialized, collaborative multi-agent debate framework for zero-shot time series reasoning. TS-Debate assigns dedicated expert agents to textual context, visual patterns, and numerical signals, preceded by explicit domain knowledge elicitation, and coordinates their interaction via a structured debate protocol. Reviewer agents evaluate agent claims using a verification-conflict-calibration mechanism, supported by lightweight code execution and numerical lookup for programmatic verification. This architecture preserves modality fidelity, exposes conflicting evidence, and mitigates numeric hallucinations without task-specific fine-tuning. Across 20 tasks spanning three public benchmarks, TS-Debate achieves consistent and significant performance improvements over strong baselines, including standard multimodal debate in which all agents observe all inputs.
Rethinking Safety in LLM Fine-tuning: An Optimization Perspective
Aug 17, 2025Fine-tuning language models is commonly believed to inevitably harm their safety, i.e., refusing to respond to harmful user requests, even when using harmless datasets, thus requiring additional safety measures. We challenge this belief through systematic testing, showing that poor optimization choices, rather than inherent trade-offs, often cause safety problems, measured as harmful responses to adversarial prompts. By properly selecting key training hyper-parameters, e.g., learning rate, batch size, and gradient steps, we reduce unsafe model responses from 16\% to approximately 5\%, as measured by keyword matching, while maintaining utility performance. Based on this observation, we propose a simple exponential moving average (EMA) momentum technique in parameter space that preserves safety performance by creating a stable optimization path and retains the original pre-trained model's safety properties. Our experiments on the Llama families across multiple datasets (Dolly, Alpaca, ORCA) demonstrate that safety problems during fine-tuning can largely be avoided without specialized interventions, outperforming existing approaches that require additional safety data while offering practical guidelines for maintaining both model performance and safety during adaptation.
Context-dependent Instruction Tuning for Dialogue Response Generation
Nov 13, 2023



Recent language models have achieved impressive performance in natural language tasks by incorporating instructions with task input during fine-tuning. Since all samples in the same natural language task can be explained with the same task instructions, many instruction datasets only provide a few instructions for the entire task, without considering the input of each example in the task. However, this approach becomes ineffective in complex multi-turn dialogue generation tasks, where the input varies highly with each turn as the dialogue context changes, so that simple task instructions cannot improve the generation performance. To address this limitation, we introduce a context-based instruction fine-tuning framework for each multi-turn dialogue which generates both responses and instructions based on the previous context as input. During the evaluation, the model generates instructions based on the previous context to self-guide the response. The proposed framework produces comparable or even outstanding results compared to the baselines by aligning instructions to the input during fine-tuning with the instructions in quantitative evaluations on dialogue benchmark datasets with reduced computation budget.
Knowledge Graph-Augmented Language Models for Knowledge-Grounded Dialogue Generation
May 30, 2023



Language models have achieved impressive performances on dialogue generation tasks. However, when generating responses for a conversation that requires factual knowledge, they are far from perfect, due to an absence of mechanisms to retrieve, encode, and reflect the knowledge in the generated responses. Some knowledge-grounded dialogue generation methods tackle this problem by leveraging facts from Knowledge Graphs (KGs); however, they do not guarantee that the model utilizes a relevant piece of knowledge from the KG. To overcome this limitation, we propose SUbgraph Retrieval-augmented GEneration (SURGE), a framework for generating context-relevant and knowledge-grounded dialogues with the KG. Specifically, our SURGE framework first retrieves the relevant subgraph from the KG, and then enforces consistency across facts by perturbing their word embeddings conditioned by the retrieved subgraph. Then, we utilize contrastive learning to ensure that the generated texts have high similarity to the retrieved subgraphs. We validate our SURGE framework on OpendialKG and KOMODIS datasets, showing that it generates high-quality dialogues that faithfully reflect the knowledge from KG.
Language Detoxification with Attribute-Discriminative Latent Space
Oct 19, 2022

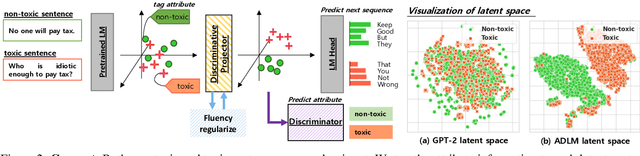
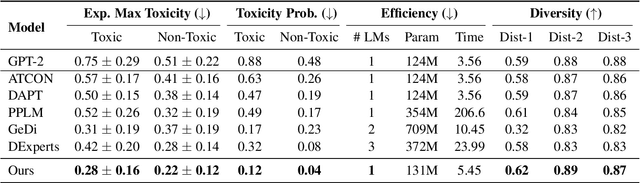
Transformer-based Language Models (LMs) achieve remarkable performances on a variety of NLU tasks, but are also prone to generating toxic texts such as insults, threats, and profanities which limit their adaptations to the real-world applications. To overcome this issue, a few text generation approaches aim to detoxify toxic texts with additional LMs or perturbations. However, previous methods require excessive memory, computations, and time which are serious bottlenecks in their real-world application. To address such limitations, we propose an effective yet efficient method for language detoxification using an attribute-discriminative latent space. Specifically, we project the latent space of an original Transformer LM to a discriminative latent space on which the texts are well-separated by their attributes, with the help of a projection block and a discriminator. This allows the LM to control the text generation to be non-toxic with minimal memory and computation overhead. We validate our model, Attribute-Discriminative Language Model (ADLM) on detoxified language and dialogue generation tasks, on which our method significantly outperforms baselines both in performance and efficiency.