 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-Stage Pick-and-Place with a Legged Mobile Manipulator
Sep 04, 2025Quadruped-based mobile manipulation presents significant challenges in robotics due to the diversity of required skills, the extended task horizon, and partial observability. After presenting a multi-stage pick-and-place task as a succinct yet sufficiently rich setup that captures key desiderata for quadruped-based mobile manipulation, we propose an approach that can train a visuo-motor policy entirely in simulation, and achieve nearly 80\% success in the real world. The policy efficiently performs search, approach, grasp, transport, and drop into actions, with emerged behaviors such as re-grasping and task chaining. We conduct an extensive set of real-world experiments with ablation studies highlighting key techniques for efficient training and effective sim-to-real transfer. Additional experiments demonstrate deployment across a variety of indoor and outdoor environments. Demo videos and additional resources are available on the project page: https://horizonrobotics.github.io/gail/SLIM.
Enhancing Diversity in Bayesian Deep Learning via Hyperspherical Energy Minimization of CKA
Oct 31, 2024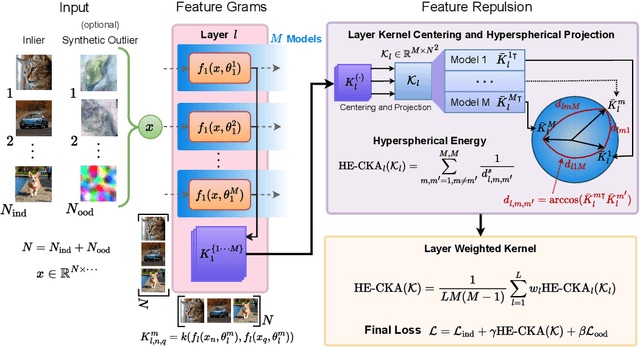
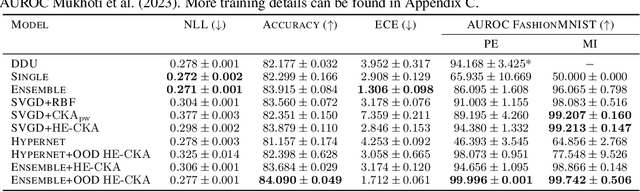
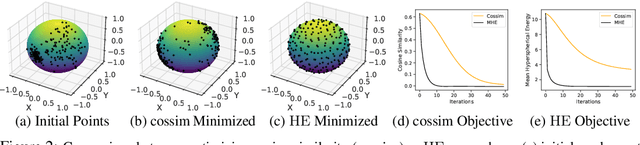
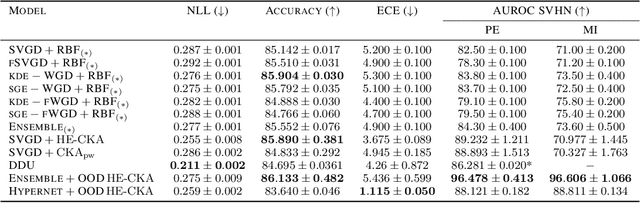
Particle-based Bayesian deep learning often requires a similarity metric to compare two networks. However, naive similarity metrics lack permutation invariance and are inappropriate for comparing networks. Centered Kernel Alignment (CKA) on feature kernels has been proposed to compare deep networks but has not been used as an optimization objective in Bayesian deep learning. In this paper, we explore the use of CKA in Bayesian deep learning to generate diverse ensembles and hypernetworks that output a network posterior. Noting that CKA projects kernels onto a unit hypersphere and that directly optimizing the CKA objective leads to diminishing gradients when two networks are very similar. We propose adopting the approach of hyperspherical energy (HE) on top of CKA kernels to address this drawback and improve training stability. Additionally, by leveraging CKA-based feature kernels, we derive feature repulsive terms applied to synthetically generated outlier examples. Experiments on both diverse ensembles and hypernetworks show that our approach significantly outperforms baselines in terms of uncertainty quantification in both synthetic and realistic outlier detection tasks.
Large Legislative Models: Towards Efficient AI Policymaking in Economic Simulations
Oct 10, 2024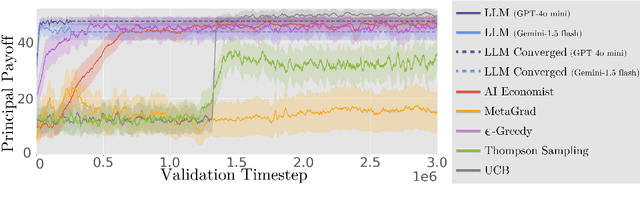
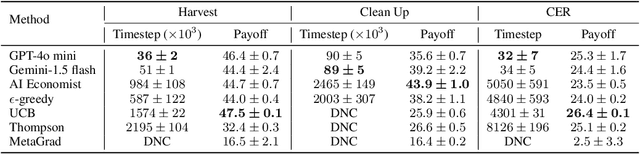
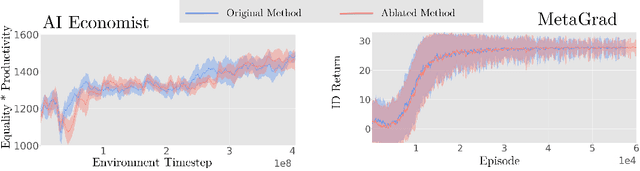
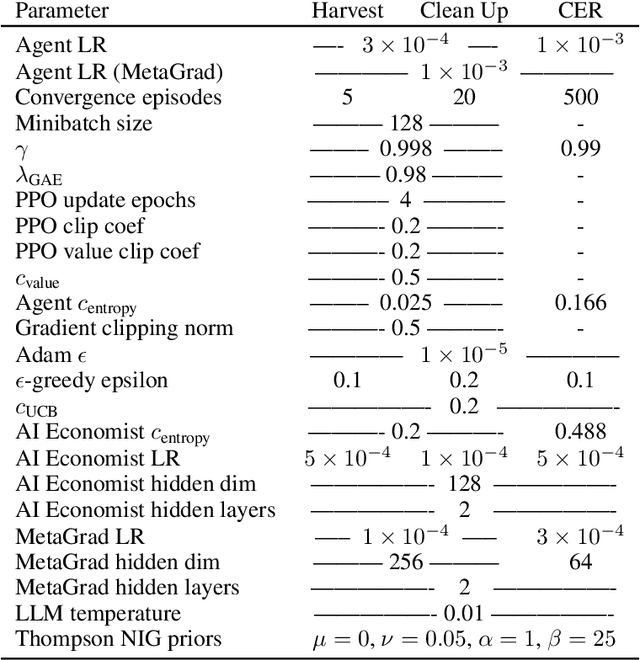
The improvement of economic policymaking presents an opportunity for broad societal benefit, a notion that has inspired research towards AI-driven policymaking tools. AI policymaking holds the potential to surpass human performance through the ability to process data quickly at scale. However, existing RL-based methods exhibit sample inefficiency, and are further limited by an inability to flexibly incorporate nuanced information into their decision-making processes. Thus, we propose a novel method in which we instead utilize pre-trained Large Language Models (LLMs), as sample-efficient policymakers in socially complex multi-agent reinforcement learning (MARL) scenarios. We demonstrate significant efficiency gains, outperforming existing methods across three environments. Our code is available at https://github.com/hegasz/large-legislative-models.
Offline Reinforcement Learning with Closed-Form Policy Improvement Operators
Nov 29, 2022
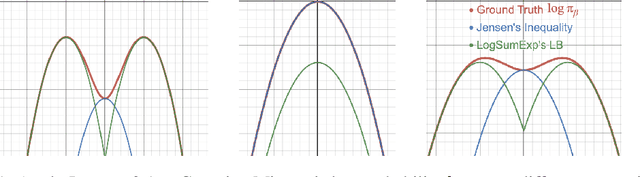


Behavior constrained policy optimization has been demonstrated to be a successful paradigm for tackling Offline Reinforcement Learning. By exploiting historical transitions, a policy is trained to maximize a learned value function while constrained by the behavior policy to avoid a significant distributional shift. In this paper, we propose our closed-form policy improvement operators. We make a novel observation that the behavior constraint naturally motivates the use of first-order Taylor approximation, leading to a linear approximation of the policy objective. Additionally, as practical datasets are usually collected by heterogeneous policies, we model the behavior policies as a Gaussian Mixture and overcome the induced optimization difficulties by leveraging the LogSumExp's lower bound and Jensen's Inequality, giving rise to a closed-form policy improvement operator. We instantiate offline RL algorithms with our novel policy improvement operators and empirically demonstrate their effectiveness over state-of-the-art algorithms on the standard D4RL benchmark.
Understanding Natural Gradient in Sobolev Spaces
Feb 21, 2022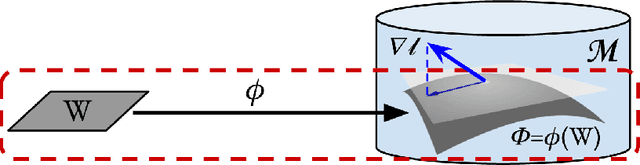
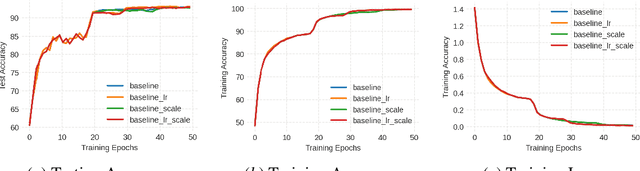
While natural gradients have been widely studied from both theoretical and empirical perspectives, we argue that a fundamental theoretical issue regarding the existence of gradients in infinite dimensional function spaces remains underexplored. We therefore study the natural gradient induced by Sobolev metrics and develop several rigorous results. Our results also establish new connections between natural gradients and RKHS theory, and specifically to the Neural Tangent Kernel (NTK). We develop computational techniques for the efficient approximation of the proposed Sobolev Natural Gradient. Preliminary experimental results reveal the potential of this new natural gradient variant.
Off-policy Reinforcement Learning with Optimistic Exploration and Distribution Correction
Oct 27, 2021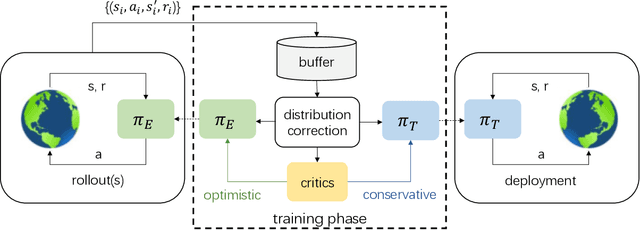
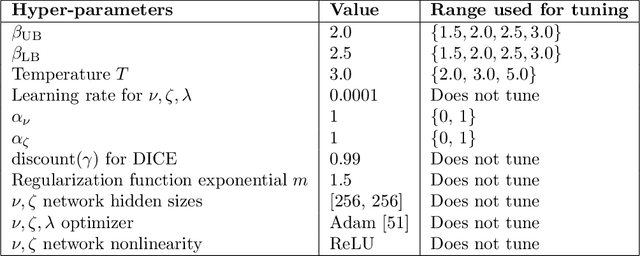

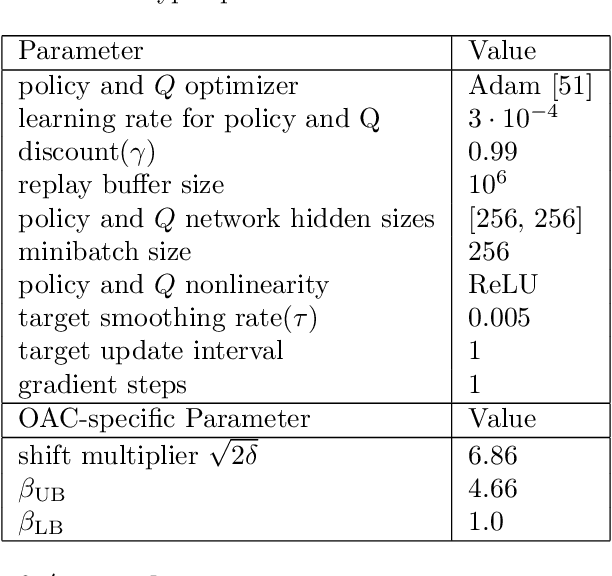
Improving sample efficiency of reinforcement learning algorithms requires effective exploration. Following the principle of $\textit{optimism in the face of uncertainty}$, we train a separate exploration policy to maximize an approximate upper confidence bound of the critics in an off-policy actor-critic framework. However, this introduces extra differences between the replay buffer and the target policy in terms of their stationary state-action distributions. To mitigate the off-policy-ness, we adapt the recently introduced DICE framework to learn a distribution correction ratio for off-policy actor-critic training. In particular, we correct the training distribution for both policies and critics. Empirically, we evaluate our proposed method in several challenging continuous control tasks and show superior performance compared to state-of-the-art methods. We also conduct extensive ablation studies to demonstrate the effectiveness and the rationality of the proposed method.
Generative Particle Variational Inference via Estimation of Functional Gradients
Mar 01, 2021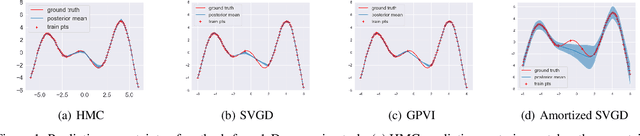
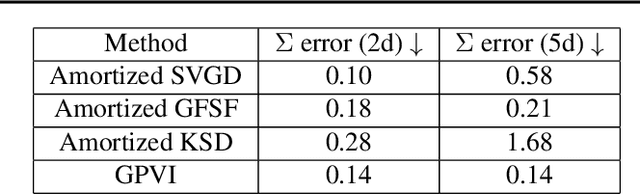
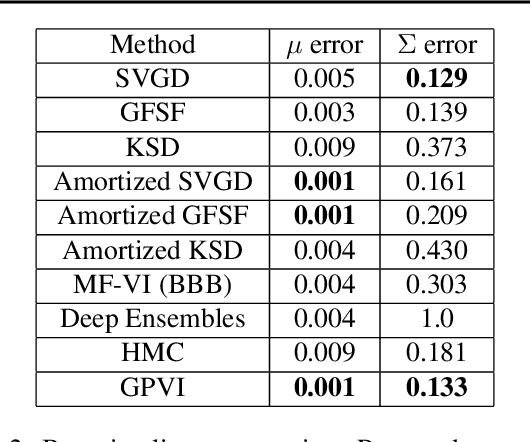
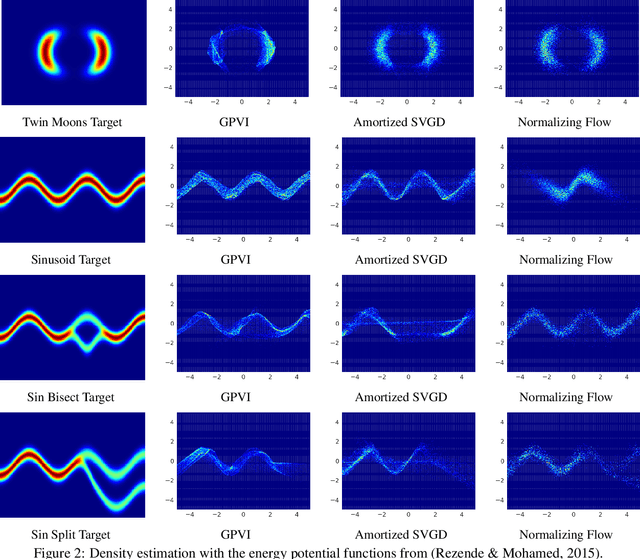
Recently, particle-based variational inference (ParVI) methods have gained interest because they directly minimize the Kullback-Leibler divergence and do not suffer from approximation errors from the evidence-based lower bound. However, many ParVI approaches do not allow arbitrary sampling from the posterior, and the few that do allow such sampling suffer from suboptimality. This work proposes a new method for learning to approximately sample from the posterior distribution. We construct a neural sampler that is trained with the functional gradient of the KL-divergence between the empirical sampling distribution and the target distribution, assuming the gradient resides within a reproducing kernel Hilbert space. Our generative ParVI (GPVI) approach maintains the asymptotic performance of ParVI methods while offering the flexibility of a generative sampler. Through carefully constructed experiments, we show that GPVI outperforms previous generative ParVI methods such as amortized SVGD, and is competitive with ParVI as well as gold-standard approaches like Hamiltonian Monte Carlo for fitting both exactly known and intractable target distributions.
Robust Visual Object Tracking with Natural Language Region Proposal Network
Dec 04, 2019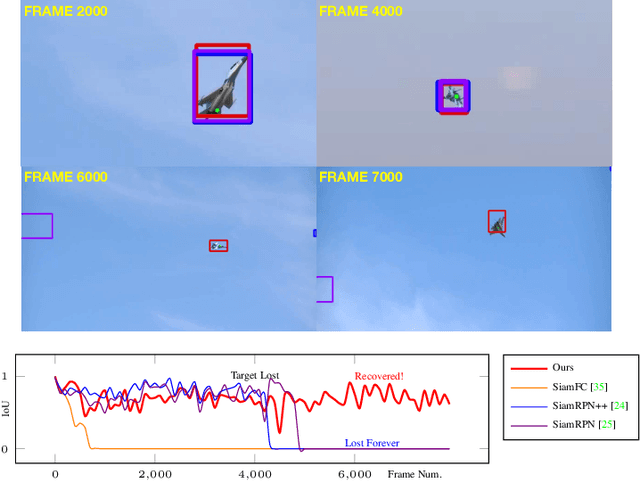
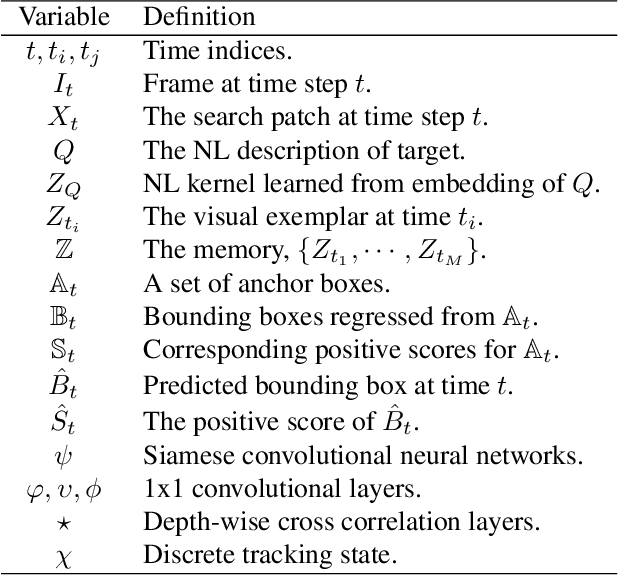
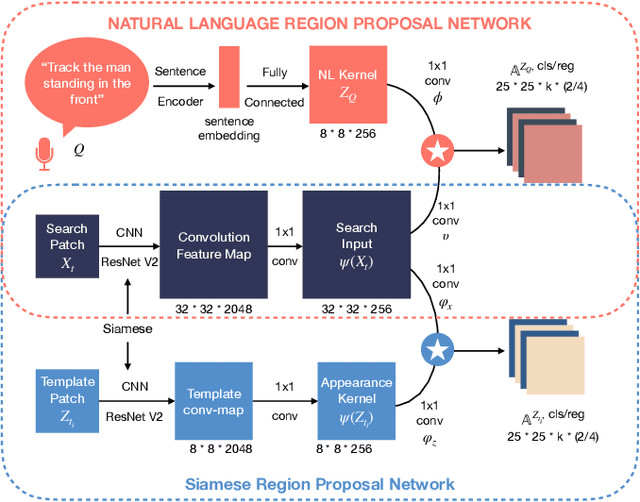
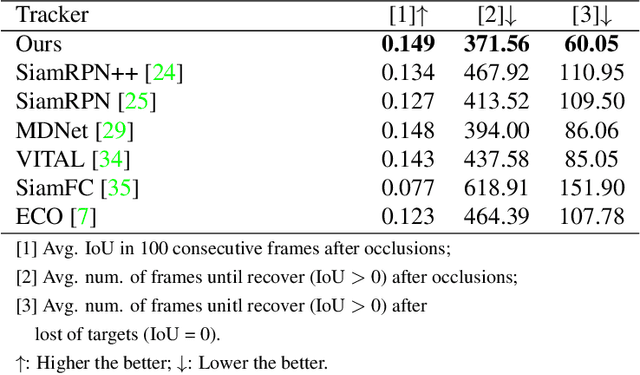
Tracking with natural-language (NL) specification is a powerful new paradigm to yield trackers that initialize without a manually-specified bounding box, stay on target in spite of occlusions, and auto-recover when diverged. These advantages stem in part from visual appearance and NL having distinct and complementary invariance properties. However, realizing these advantages is technically challenging: the two modalities have incompatible representations. In this paper, we present the first practical and competitive solution to the challenge of tracking with NL specification. Our first novelty is an NL region proposal network (NL-RPN) that transforms an NL description into a convolutional kernel and shares the search branch with siamese trackers; the combined network can be trained end-to-end. Secondly, we propose a novel formulation to represent the history of past visual exemplars and use those exemplars to automatically reset the tracker together with our NL-RPN. Empirical results over tracking benchmarks with NL annotations demonstrate the effectiveness of our approach.
Implicit Generative Modeling for Efficient Exploration
Nov 19, 2019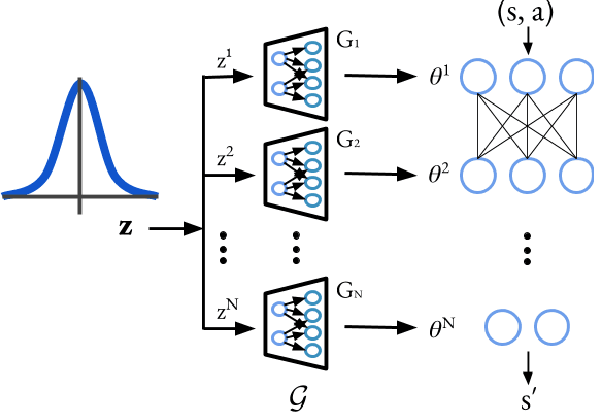

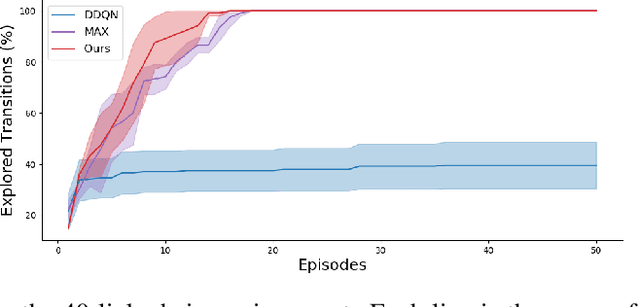
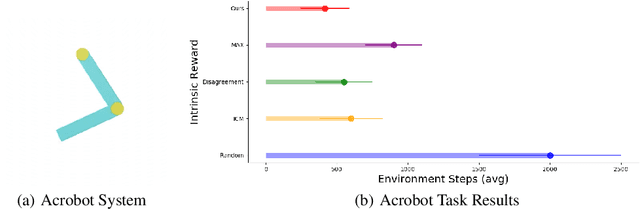
Efficient exploration remains a challenging problem in reinforcement learning, especially for those tasks where rewards from environments are sparse. A commonly used approach for exploring such environments is to introduce some "intrinsic" reward. In this work, we focus on model uncertainty estimation as an intrinsic reward for efficient exploration. In particular, we introduce an implicit generative modeling approach to estimate a Bayesian uncertainty of the agent's belief of the environment dynamics. Each random draw from our generative model is a neural network that instantiates the dynamic function, hence multiple draws would approximate the posterior, and the variance in the future prediction based on this posterior is used as an intrinsic reward for exploration. We design a training algorithm for our generative model based on the amortized Stein Variational Gradient Descent. In experiments, we compare our implementation with state-of-the-art intrinsic reward-based exploration approaches, including two recent approaches based on an ensemble of dynamic models. In challenging exploration tasks, our implicit generative model consistently outperforms competing approaches regarding data efficiency in exploration.
Tell Me What to Track
Aug 05, 2019

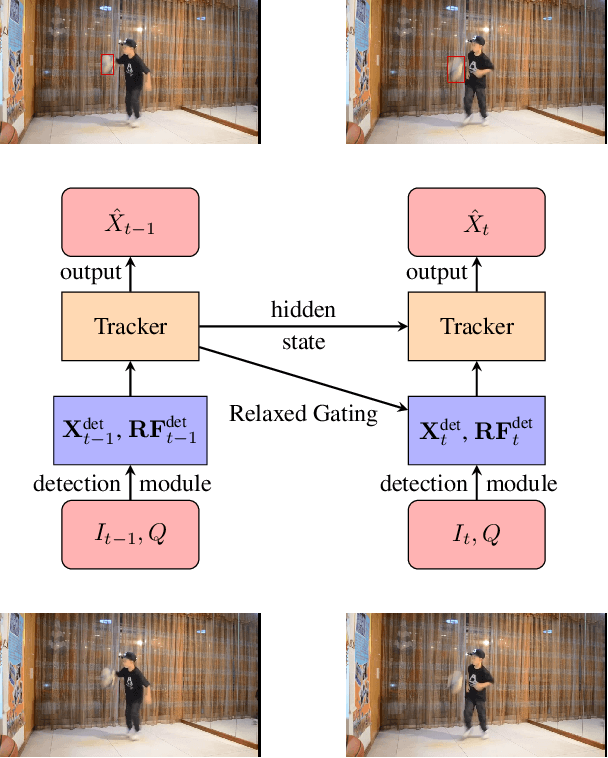
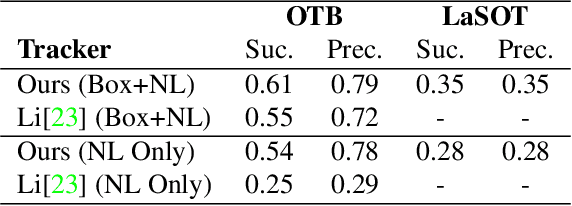
In recent years, deep-learning-based visual object trackers have been studied thoroughly, but handling occlusions and/or rapid motion of the target remains challenging. In this work, we argue that conditioning on the natural language (NL) description of a target provides information for longer-term invariance, and thus helps cope with typical tracking challenges. However, deriving a formulation to combine the strengths of appearance-based tracking with the language modality is not straightforward. We propose a novel deep tracking-by-detection formulation that can take advantage of NL descriptions. Regions that are related to the given NL description are generated by a proposal network during the detection phase of the tracker. Our LSTM based tracker then predicts the update of the target from regions proposed by the NL based detection phase. In benchmarks, our method is competitive with state of the art trackers, while it outperforms all other trackers on targets with unambiguous and precise language annotations. It also beats the state-of-the-art NL tracker when initializing without a bounding box. Our method runs at over 30 fps on a single GPU.