 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAFFMAE: Scalable and Efficient Vision Pretraining for Desktop Graphics Cards
Feb 18, 2026Self-supervised pretraining has transformed computer vision by enabling data-efficient fine-tuning, yet high-resolution training typically requires server-scale infrastructure, limiting in-domain foundation model development for many research laboratories. Masked Autoencoders (MAE) reduce computation by encoding only visible tokens, but combining MAE with hierarchical downsampling architectures remains structurally challenging due to dense grid priors and mask-aware design compromises. We introduce AFFMAE, a masking-friendly hierarchical pretraining framework built on adaptive, off-grid token merging. By discarding masked tokens and performing dynamic merging exclusively over visible tokens, AFFMAE removes dense-grid assumptions while preserving hierarchical scalability. We developed numerically stable mixed-precision Flash-style cluster attention kernels, and mitigate sparse-stage representation collapse via deep supervision. On high-resolution electron microscopy segmentation, AFFMAE matches ViT-MAE performance at equal parameter count while reducing FLOPs by up to 7x, halving memory usage, and achieving faster training on a single RTX 5090. Code available at https://github.com/najafian-lab/affmae.
Enhancing Diversity in Bayesian Deep Learning via Hyperspherical Energy Minimization of CKA
Oct 31, 2024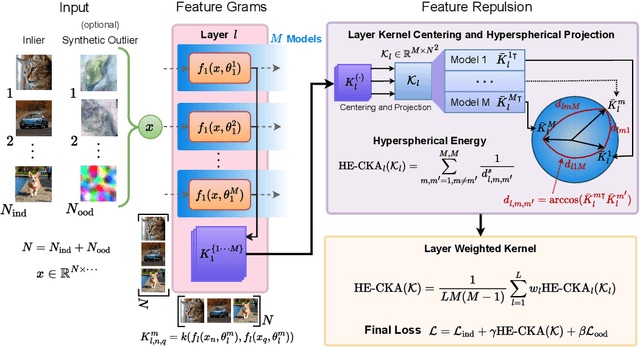
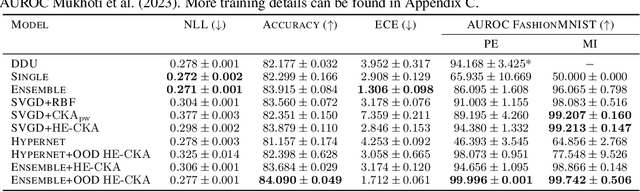
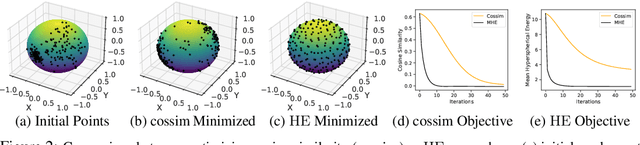
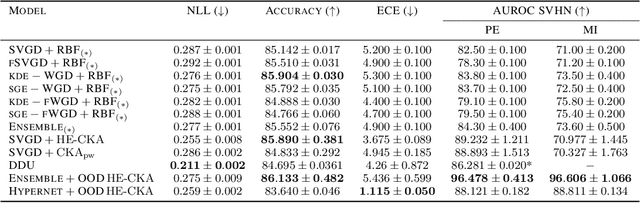
Particle-based Bayesian deep learning often requires a similarity metric to compare two networks. However, naive similarity metrics lack permutation invariance and are inappropriate for comparing networks. Centered Kernel Alignment (CKA) on feature kernels has been proposed to compare deep networks but has not been used as an optimization objective in Bayesian deep learning. In this paper, we explore the use of CKA in Bayesian deep learning to generate diverse ensembles and hypernetworks that output a network posterior. Noting that CKA projects kernels onto a unit hypersphere and that directly optimizing the CKA objective leads to diminishing gradients when two networks are very similar. We propose adopting the approach of hyperspherical energy (HE) on top of CKA kernels to address this drawback and improve training stability. Additionally, by leveraging CKA-based feature kernels, we derive feature repulsive terms applied to synthetically generated outlier examples. Experiments on both diverse ensembles and hypernetworks show that our approach significantly outperforms baselines in terms of uncertainty quantification in both synthetic and realistic outlier detection tasks.