 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Vision and Language to 3D Masks for Long-Horizon Box Rearrangement
Mar 24, 2026We study long-horizon planning in 3D environments from under-specified natural-language goals using only visual observations, focusing on multi-step 3D box rearrangement tasks. Existing approaches typically rely on symbolic planners with brittle relational grounding of states and goals, or on direct action-sequence generation from 2D vision-language models (VLMs). Both approaches struggle with reasoning over many objects, rich 3D geometry, and implicit semantic constraints. Recent advances in 3D VLMs demonstrate strong grounding of natural-language referents to 3D segmentation masks, suggesting the potential for more general planning capabilities. We extend existing 3D grounding models and propose Reactive Action Mask Planner (RAMP-3D), which formulates long-horizon planning as sequential reactive prediction of paired 3D masks: a "which-object" mask indicating what to pick and a "which-target-region" mask specifying where to place it. The resulting system processes RGB-D observations and natural-language task specifications to reactively generate multi-step pick-and-place actions for 3D box rearrangement. We conduct experiments across 11 task variants in warehouse-style environments with 1-30 boxes and diverse natural-language constraints. RAMP-3D achieves 79.5% success rate on long-horizon rearrangement tasks and significantly outperforms 2D VLM-based baselines, establishing mask-based reactive policies as a promising alternative to symbolic pipelines for long-horizon planning.
Enhancing Diversity in Bayesian Deep Learning via Hyperspherical Energy Minimization of CKA
Oct 31, 2024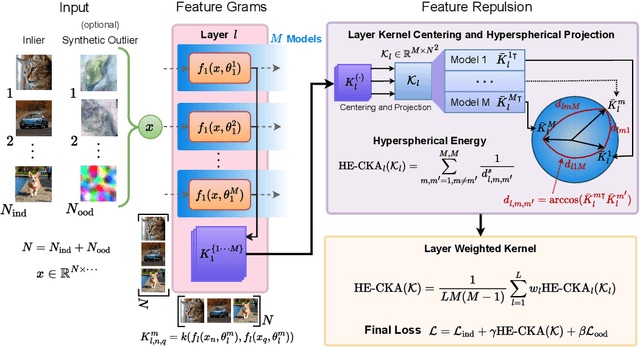
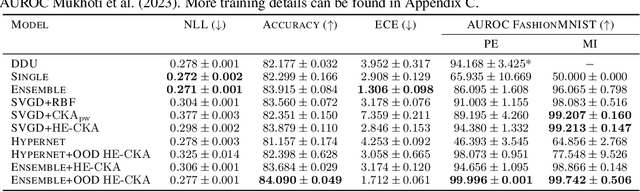
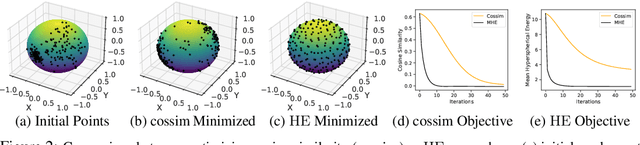
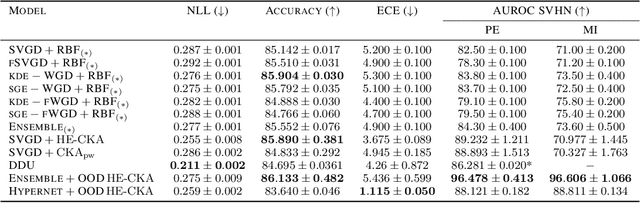
Particle-based Bayesian deep learning often requires a similarity metric to compare two networks. However, naive similarity metrics lack permutation invariance and are inappropriate for comparing networks. Centered Kernel Alignment (CKA) on feature kernels has been proposed to compare deep networks but has not been used as an optimization objective in Bayesian deep learning. In this paper, we explore the use of CKA in Bayesian deep learning to generate diverse ensembles and hypernetworks that output a network posterior. Noting that CKA projects kernels onto a unit hypersphere and that directly optimizing the CKA objective leads to diminishing gradients when two networks are very similar. We propose adopting the approach of hyperspherical energy (HE) on top of CKA kernels to address this drawback and improve training stability. Additionally, by leveraging CKA-based feature kernels, we derive feature repulsive terms applied to synthetically generated outlier examples. Experiments on both diverse ensembles and hypernetworks show that our approach significantly outperforms baselines in terms of uncertainty quantification in both synthetic and realistic outlier detection tasks.
Efficient Learning and Decoding of the Continuous-Time Hidden Markov Model for Disease Progression Modeling
Oct 26, 2021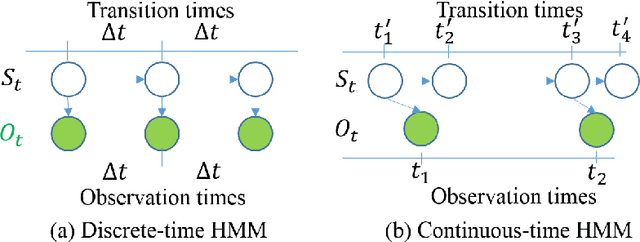

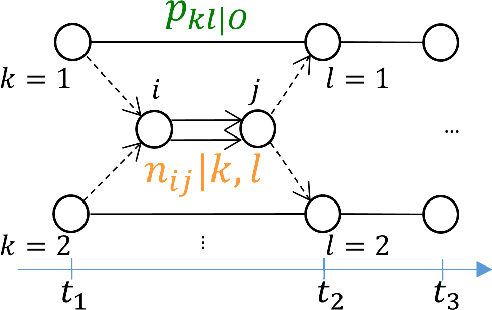
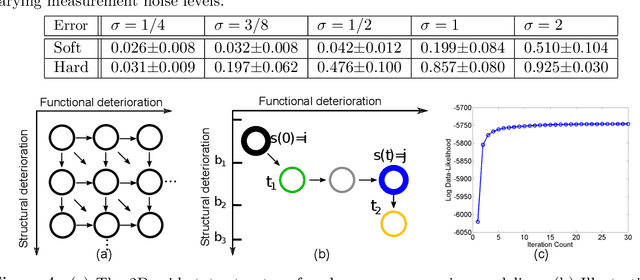
The Continuous-Time Hidden Markov Model (CT-HMM) is an attractive approach to modeling disease progression due to its ability to describe noisy observations arriving irregularly in time. However, the lack of an efficient parameter learning algorithm for CT-HMM restricts its use to very small models or requires unrealistic constraints on the state transitions. In this paper, we present the first complete characterization of efficient EM-based learning methods for CT-HMM models, as well as the first solution to decoding the optimal state transition sequence and the corresponding state dwelling time. We show that EM-based learning consists of two challenges: the estimation of posterior state probabilities and the computation of end-state conditioned statistics. We solve the first challenge by reformulating the estimation problem as an equivalent discrete time-inhomogeneous hidden Markov model. The second challenge is addressed by adapting three distinct approaches from the continuous time Markov chain (CTMC) literature to the CT-HMM domain. Additionally, we further improve the efficiency of the most efficient method by a factor of the number of states. Then, for decoding, we incorporate a state-of-the-art method from the (CTMC) literature, and extend the end-state conditioned optimal state sequence decoding to the CT-HMM case with the computation of the expected state dwelling time. We demonstrate the use of CT-HMMs with more than 100 states to visualize and predict disease progression using a glaucoma dataset and an Alzheimer's disease dataset, and to decode and visualize the most probable state transition trajectory for individuals on the glaucoma dataset, which helps to identify progressing phenotypes in a comprehensive way. Finally, we apply the CT-HMM modeling and decoding strategy to investigate the progression of language acquisition and development.
Unsupervised Few-Shot Action Recognition via Action-Appearance Aligned Meta-Adaptation
Oct 11, 2021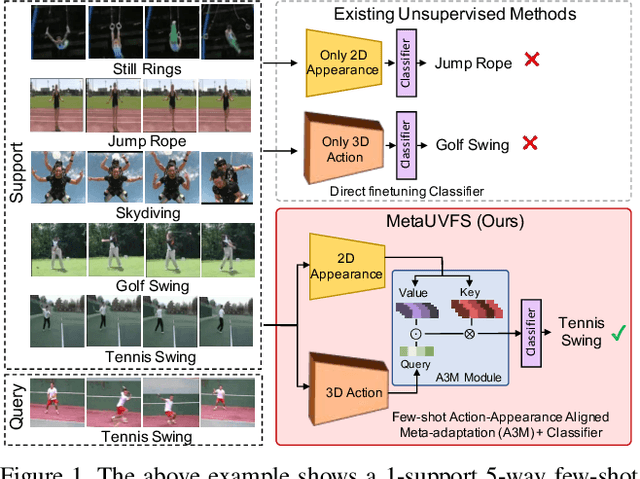
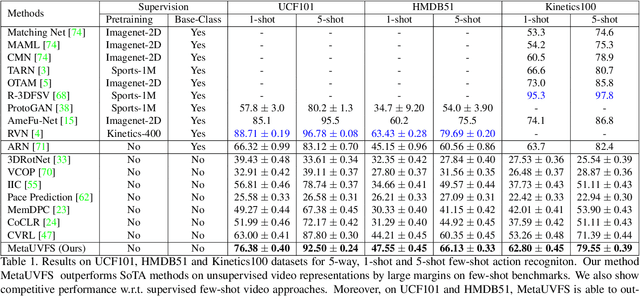
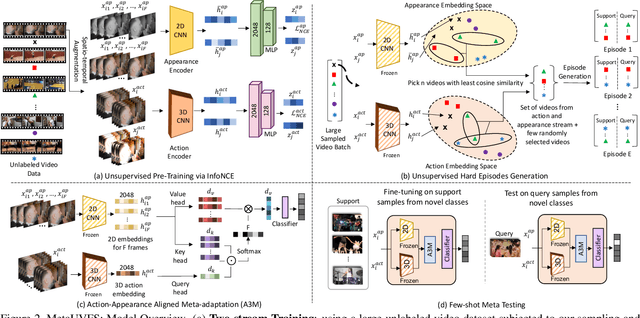
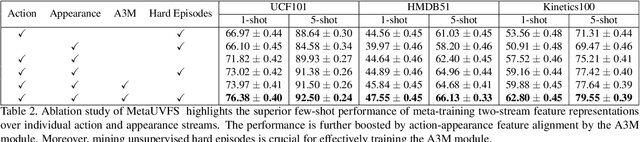
We present MetaUVFS as the first Unsupervised Meta-learning algorithm for Video Few-Shot action recognition. MetaUVFS leverages over 550K unlabeled videos to train a two-stream 2D and 3D CNN architecture via contrastive learning to capture the appearance-specific spatial and action-specific spatio-temporal video features respectively. MetaUVFS comprises a novel Action-Appearance Aligned Meta-adaptation (A3M) module that learns to focus on the action-oriented video features in relation to the appearance features via explicit few-shot episodic meta-learning over unsupervised hard-mined episodes. Our action-appearance alignment and explicit few-shot learner conditions the unsupervised training to mimic the downstream few-shot task, enabling MetaUVFS to significantly outperform all unsupervised methods on few-shot benchmarks. Moreover, unlike previous few-shot action recognition methods that are supervised, MetaUVFS needs neither base-class labels nor a supervised pretrained backbone. Thus, we need to train MetaUVFS just once to perform competitively or sometimes even outperform state-of-the-art supervised methods on popular HMDB51, UCF101, and Kinetics100 few-shot datasets.
Space Time Recurrent Memory Network
Sep 14, 2021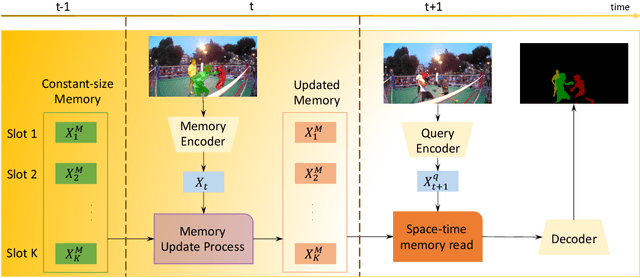
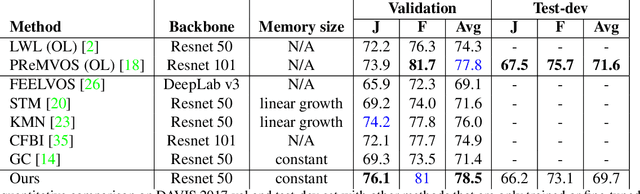
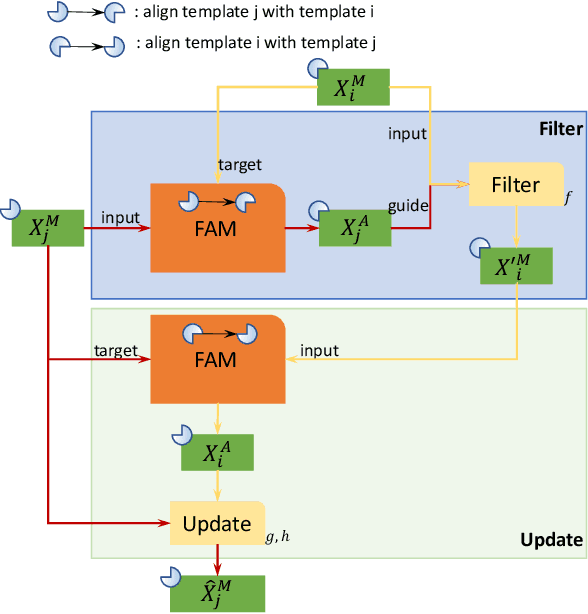
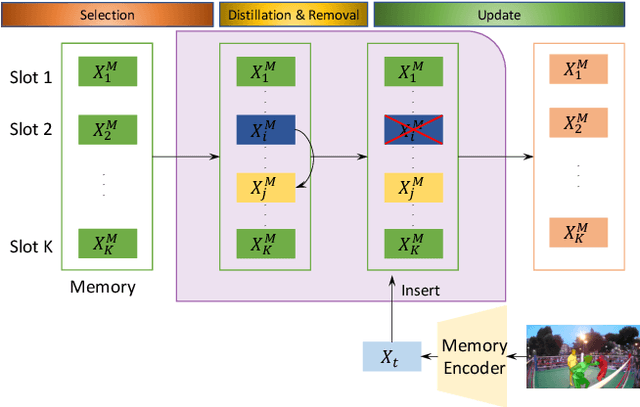
We propose a novel visual memory network architecture for the learning and inference problem in the spatial-temporal domain. Different from the popular transformers, we maintain a fixed set of memory slots in our memory network and explore designs to input new information into the memory, combine the information in different memory slots and decide when to discard old memory slots. Finally, this architecture is benchmarked on the video object segmentation and video prediction problems. Through the experiments, we show that our memory architecture can achieve competitive results with state-of-the-art while maintaining constant memory capacity.
Counterfactual State Explanations for Reinforcement Learning Agents via Generative Deep Learning
Jan 29, 2021



Counterfactual explanations, which deal with "why not?" scenarios, can provide insightful explanations to an AI agent's behavior. In this work, we focus on generating counterfactual explanations for deep reinforcement learning (RL) agents which operate in visual input environments like Atari. We introduce counterfactual state explanations, a novel example-based approach to counterfactual explanations based on generative deep learning. Specifically, a counterfactual state illustrates what minimal change is needed to an Atari game image such that the agent chooses a different action. We also evaluate the effectiveness of counterfactual states on human participants who are not machine learning experts. Our first user study investigates if humans can discern if the counterfactual state explanations are produced by the actual game or produced by a generative deep learning approach. Our second user study investigates if counterfactual state explanations can help non-expert participants identify a flawed agent; we compare against a baseline approach based on a nearest neighbor explanation which uses images from the actual game. Our results indicate that counterfactual state explanations have sufficient fidelity to the actual game images to enable non-experts to more effectively identify a flawed RL agent compared to the nearest neighbor baseline and to having no explanation at all.
* Full source code available at https://github.com/mattolson93/counterfactual-state-explanations
iGOS++: Integrated Gradient Optimized Saliency by Bilateral Perturbations
Dec 31, 2020

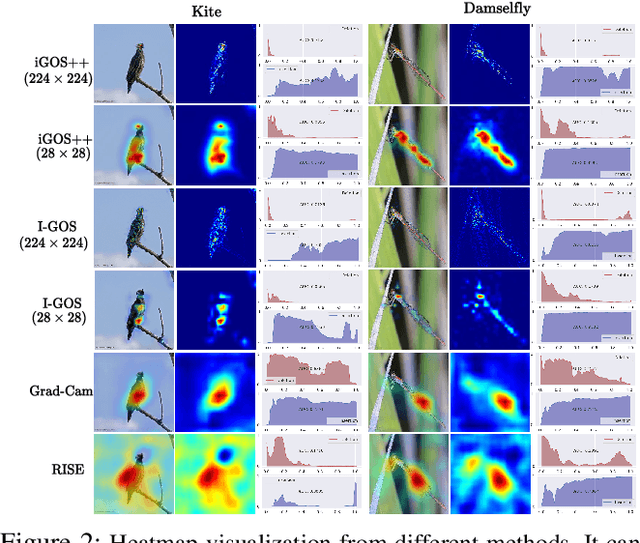

The black-box nature of the deep networks makes the explanation for "why" they make certain predictions extremely challenging. Saliency maps are one of the most widely-used local explanation tools to alleviate this problem. One of the primary approaches for generating saliency maps is by optimizing a mask over the input dimensions so that the output of the network is influenced the most by the masking. However, prior work only studies such influence by removing evidence from the input. In this paper, we present iGOS++, a framework to generate saliency maps that are optimized for altering the output of the black-box system by either removing or preserving only a small fraction of the input. Additionally, we propose to add a bilateral total variation term to the optimization that improves the continuity of the saliency map especially under high resolution and with thin object parts. The evaluation results from comparing iGOS++ against state-of-the-art saliency map methods show significant improvement in locating salient regions that are directly interpretable by humans. We utilized iGOS++ in the task of classifying COVID-19 cases from x-ray images and discovered that sometimes the CNN network is overfitted to the characters printed on the x-ray images when performing classification. Fixing this issue by data cleansing significantly improved the precision and recall of the classifier.
Counterfactual States for Atari Agents via Generative Deep Learning
Sep 27, 2019
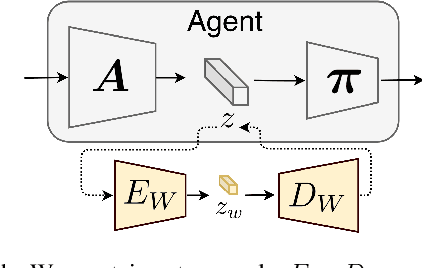

Although deep reinforcement learning agents have produced impressive results in many domains, their decision making is difficult to explain to humans. To address this problem, past work has mainly focused on explaining why an action was chosen in a given state. A different type of explanation that is useful is a counterfactual, which deals with "what if?" scenarios. In this work, we introduce the concept of a counterfactual state to help humans gain a better understanding of what would need to change (minimally) in an Atari game image for the agent to choose a different action. We introduce a novel method to create counterfactual states from a generative deep learning architecture. In addition, we evaluate the effectiveness of counterfactual states on human participants who are not machine learning experts. Our user study results suggest that our generated counterfactual states are useful in helping non-expert participants gain a better understanding of an agent's decision making process.
Interactive Naming for Explaining Deep Neural Networks: A Formative Study
Dec 20, 2018
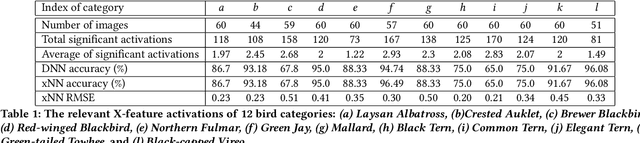

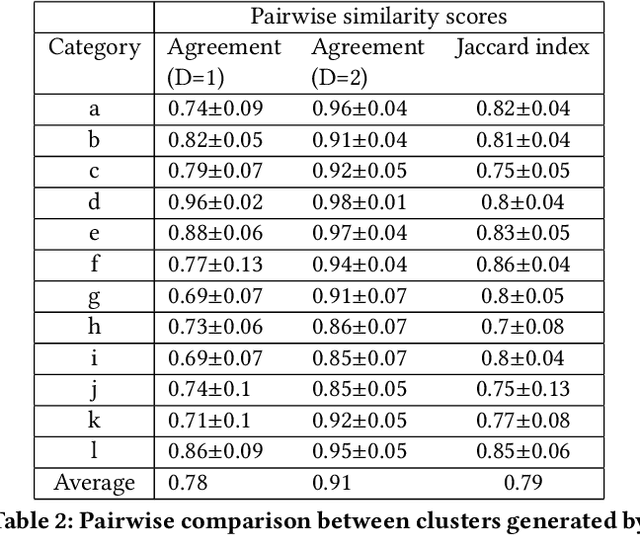
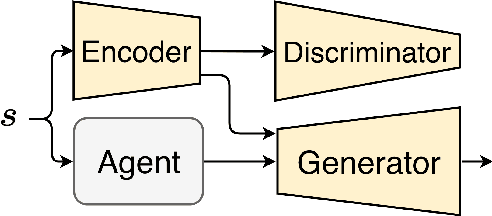
We consider the problem of explaining the decisions of deep neural networks for image recognition in terms of human-recognizable visual concepts. In particular, given a test set of images, we aim to explain each classification in terms of a small number of image regions, or activation maps, which have been associated with semantic concepts by a human annotator. This allows for generating summary views of the typical reasons for classifications, which can help build trust in a classifier and/or identify example types for which the classifier may not be trusted. For this purpose, we developed a user interface for "interactive naming," which allows a human annotator to manually cluster significant activation maps in a test set into meaningful groups called "visual concepts". The main contribution of this paper is a systematic study of the visual concepts produced by five human annotators using the interactive naming interface. In particular, we consider the adequacy of the concepts for explaining the classification of test-set images, correspondence of the concepts to activations of individual neurons, and the inter-annotator agreement of visual concepts. We find that a large fraction of the activation maps have recognizable visual concepts, and that there is significant agreement between the different annotators about their denotations. Our work is an exploratory study of the interplay between machine learning and human recognition mediated by visualizations of the results of learning.
Purely Geometric Scene Association and Retrieval - A Case for Macro Scale 3D Geometry
Aug 03, 2018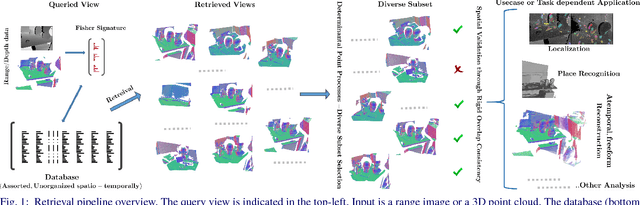
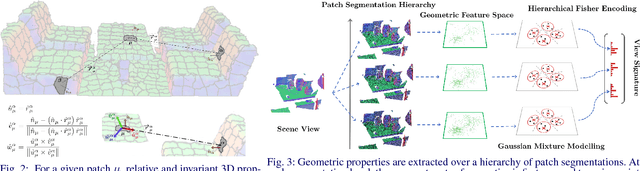
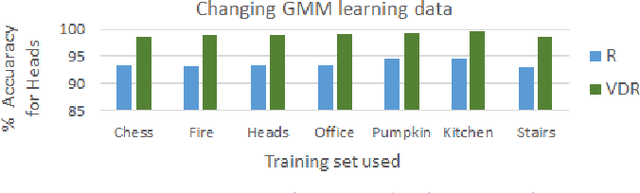
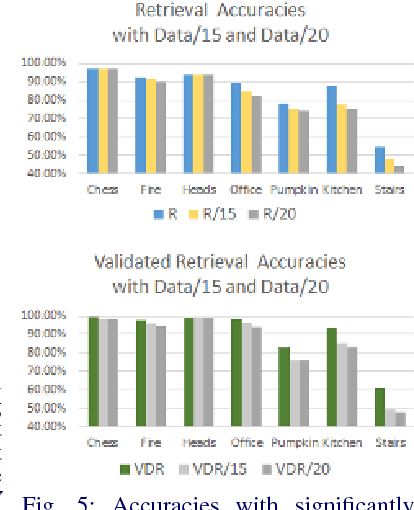
We address the problems of measuring geometric similarity between 3D scenes, represented through point clouds or range data frames, and associating them. Our approach leverages macro-scale 3D structural geometry - the relative configuration of arbitrary surfaces and relationships among structures that are potentially far apart. We express such discriminative information in a viewpoint-invariant feature space. These are subsequently encoded in a frame-level signature that can be utilized to measure geometric similarity. Such a characterization is robust to noise, incomplete and partially overlapping data besides viewpoint changes. We show how it can be employed to select a diverse set of data frames which have structurally similar content, and how to validate whether views with similar geometric content are from the same scene. The problem is formulated as one of general purpose retrieval from an unannotated, spatio-temporally unordered database. Empirical analysis indicates that the presented approach thoroughly outperforms baselines on depth / range data. Its depth-only performance is competitive with state-of-the-art approaches with RGB or RGB-D inputs, including ones based on deep learning. Experiments show retrieval performance to hold up well with much sparser databases, which is indicative of the approach's robustness. The approach generalized well - it did not require dataset specific training, and scaled up in our experiments. Finally, we also demonstrate how geometrically diverse selection of views can result in richer 3D reconstructions.