Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpace Time Recurrent Memory Network
Paper and Code
Sep 14, 2021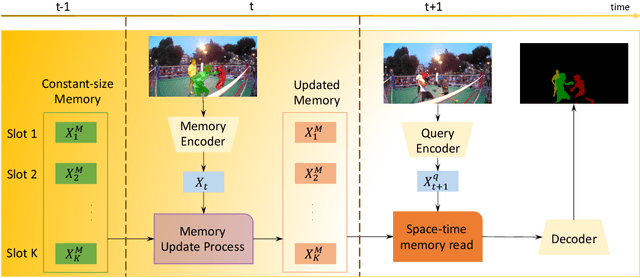
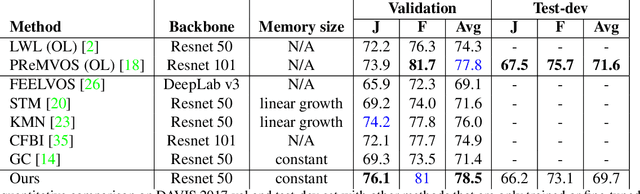
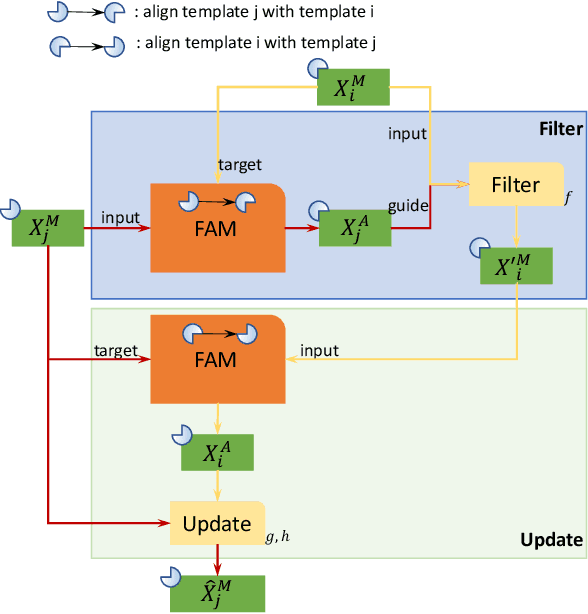
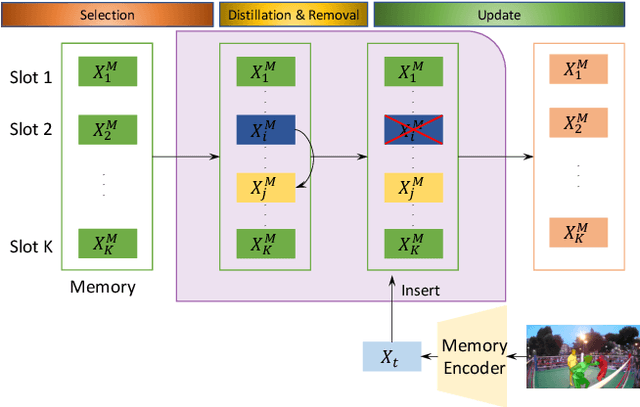
We propose a novel visual memory network architecture for the learning and inference problem in the spatial-temporal domain. Different from the popular transformers, we maintain a fixed set of memory slots in our memory network and explore designs to input new information into the memory, combine the information in different memory slots and decide when to discard old memory slots. Finally, this architecture is benchmarked on the video object segmentation and video prediction problems. Through the experiments, we show that our memory architecture can achieve competitive results with state-of-the-art while maintaining constant memory capacity.
View paper on
 OpenReview
OpenReview