 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Deep Networks into Visual Explanations
Paper and Code
Apr 11, 2018
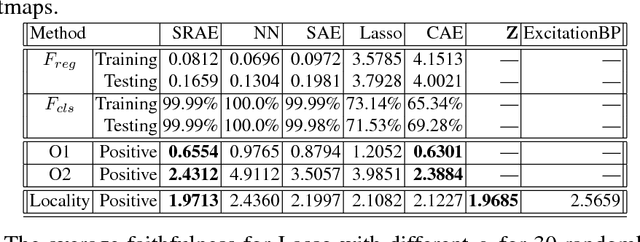
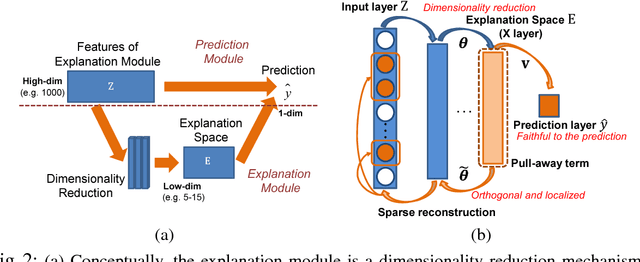
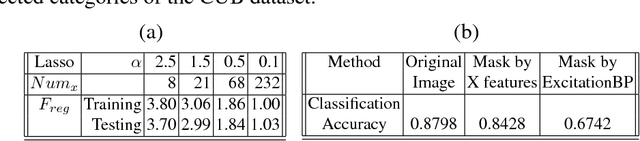
In this paper, we propose a novel explanation module to explain the predictions made by a deep network. The explanation module works by embedding a high-dimensional deep network layer nonlinearly into a low-dimensional explanation space while retaining faithfulness, so that the original deep learning predictions can be constructed from the few concepts extracted by the explanation module. We then visualize such concepts for human to learn about the high-level concepts that deep learning is using to make decisions. We propose an algorithm called Sparse Reconstruction Autoencoder (SRAE) for learning the embedding to the explanation space. SRAE aims to reconstruct part of the original feature space while retaining faithfulness. A pull-away term is applied to SRAE to make the explanation space more orthogonal. A visualization system is then introduced for human understanding of the features in the explanation space. The proposed method is applied to explain CNN models in image classification tasks, and several novel metrics are introduced to evaluate the performance of explanations quantitatively without human involvement. Experiments show that the proposed approach generates interesting explanations of the mechanisms CNN use for making predictions.