 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximal Cliques on Multi-Frame Proposal Graph for Unsupervised Video Object Segmentation
Jan 29, 2023
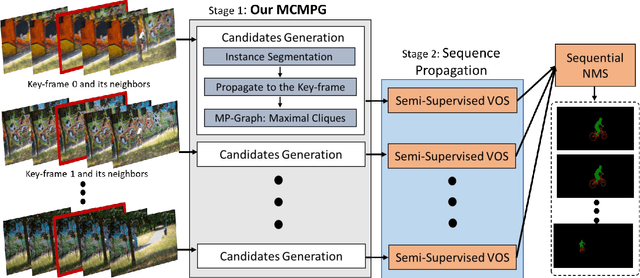
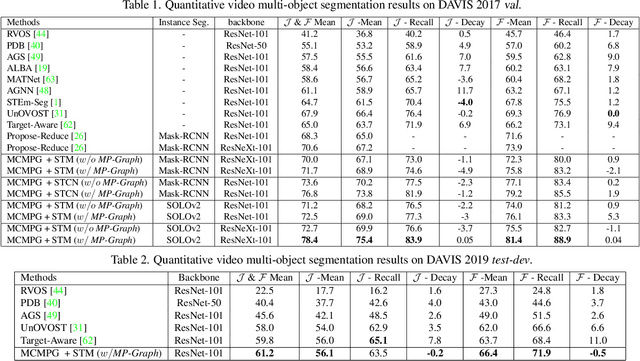
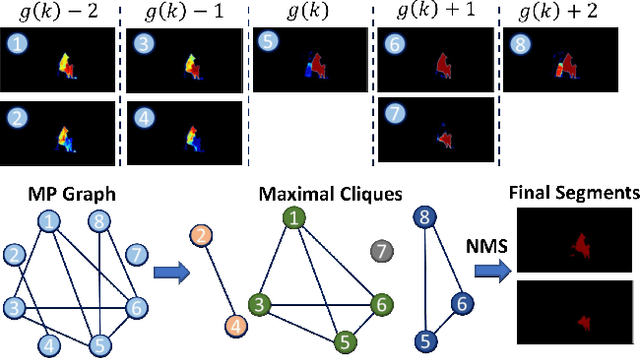
Unsupervised Video Object Segmentation (UVOS) aims at discovering objects and tracking them through videos. For accurate UVOS, we observe if one can locate precise segment proposals on key frames, subsequent processes are much simpler. Hence, we propose to reason about key frame proposals using a graph built with the object probability masks initially generated from multiple frames around the key frame and then propagated to the key frame. On this graph, we compute maximal cliques, with each clique representing one candidate object. By making multiple proposals in the clique to vote for the key frame proposal, we obtain refined key frame proposals that could be better than any of the single-frame proposals. A semi-supervised VOS algorithm subsequently tracks these key frame proposals to the entire video. Our algorithm is modular and hence can be used with any instance segmentation and semi-supervised VOS algorithm. We achieve state-of-the-art performance on the DAVIS-2017 validation and test-dev dataset. On the related problem of video instance segmentation, our method shows competitive performance with the previous best algorithm that requires joint training with the VOS algorithm.
Unsupervised Few-Shot Action Recognition via Action-Appearance Aligned Meta-Adaptation
Oct 11, 2021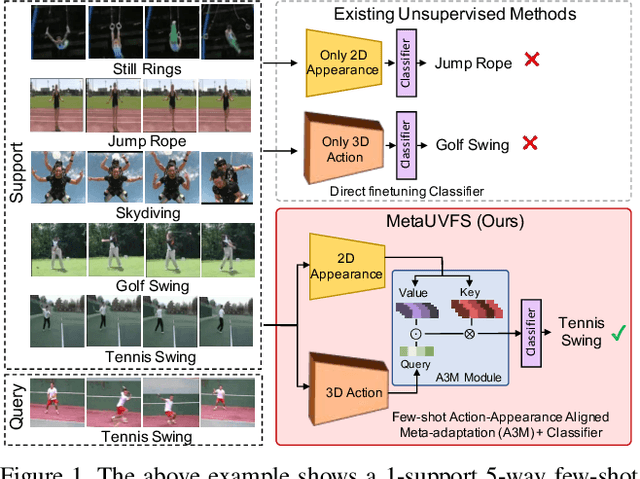
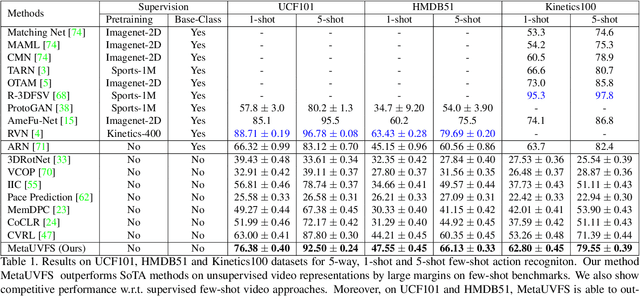
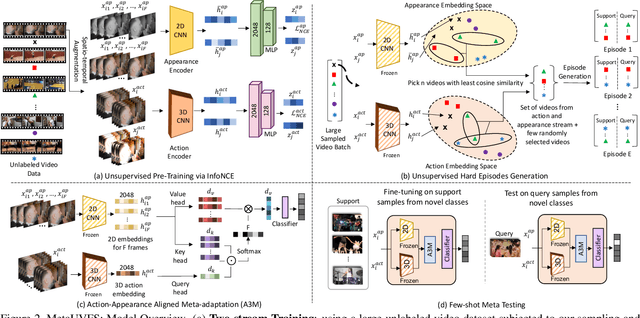
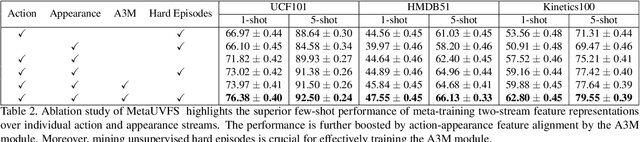
We present MetaUVFS as the first Unsupervised Meta-learning algorithm for Video Few-Shot action recognition. MetaUVFS leverages over 550K unlabeled videos to train a two-stream 2D and 3D CNN architecture via contrastive learning to capture the appearance-specific spatial and action-specific spatio-temporal video features respectively. MetaUVFS comprises a novel Action-Appearance Aligned Meta-adaptation (A3M) module that learns to focus on the action-oriented video features in relation to the appearance features via explicit few-shot episodic meta-learning over unsupervised hard-mined episodes. Our action-appearance alignment and explicit few-shot learner conditions the unsupervised training to mimic the downstream few-shot task, enabling MetaUVFS to significantly outperform all unsupervised methods on few-shot benchmarks. Moreover, unlike previous few-shot action recognition methods that are supervised, MetaUVFS needs neither base-class labels nor a supervised pretrained backbone. Thus, we need to train MetaUVFS just once to perform competitively or sometimes even outperform state-of-the-art supervised methods on popular HMDB51, UCF101, and Kinetics100 few-shot datasets.
2D-3D Fully Convolutional Neural Networks for Cardiac MR Segmentation
Jul 31, 2017

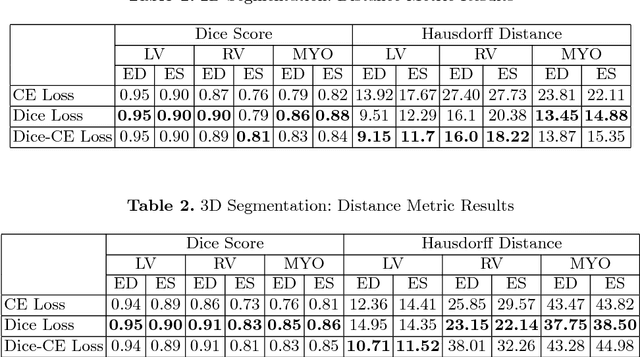

In this paper, we develop a 2D and 3D segmentation pipelines for fully automated cardiac MR image segmentation using Deep Convolutional Neural Networks (CNN). Our models are trained end-to-end from scratch using the ACD Challenge 2017 dataset comprising of 100 studies, each containing Cardiac MR images in End Diastole and End Systole phase. We show that both our segmentation models achieve near state-of-the-art performance scores in terms of distance metrics and have convincing accuracy in terms of clinical parameters. A comparative analysis is provided by introducing a novel dice loss function and its combination with cross entropy loss. By exploring different network structures and comprehensive experiments, we discuss several key insights to obtain optimal model performance, which also is central to the theme of this challenge.