 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Naming for Explaining Deep Neural Networks: A Formative Study
Dec 20, 2018
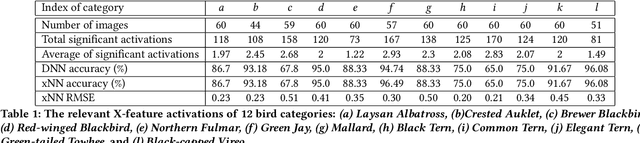

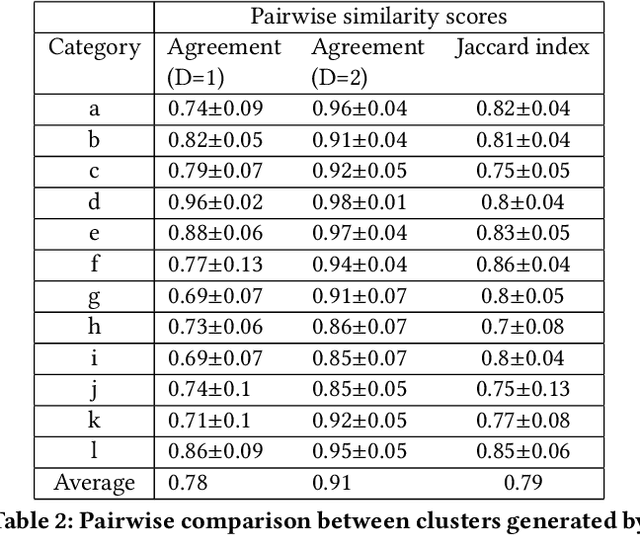
We consider the problem of explaining the decisions of deep neural networks for image recognition in terms of human-recognizable visual concepts. In particular, given a test set of images, we aim to explain each classification in terms of a small number of image regions, or activation maps, which have been associated with semantic concepts by a human annotator. This allows for generating summary views of the typical reasons for classifications, which can help build trust in a classifier and/or identify example types for which the classifier may not be trusted. For this purpose, we developed a user interface for "interactive naming," which allows a human annotator to manually cluster significant activation maps in a test set into meaningful groups called "visual concepts". The main contribution of this paper is a systematic study of the visual concepts produced by five human annotators using the interactive naming interface. In particular, we consider the adequacy of the concepts for explaining the classification of test-set images, correspondence of the concepts to activations of individual neurons, and the inter-annotator agreement of visual concepts. We find that a large fraction of the activation maps have recognizable visual concepts, and that there is significant agreement between the different annotators about their denotations. Our work is an exploratory study of the interplay between machine learning and human recognition mediated by visualizations of the results of learning.