 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiased Estimators in High-Dimensional Regression: A Review and Replication of Javanmard and Montanari (2014)
Apr 01, 2026High-dimensional statistical settings ($p \gg n$) pose fundamental challenges for classical inference, largely due to bias introduced by regularized estimators such as the LASSO. To address this, Javanmard and Montanari (2014) propose a debiased estimator that enables valid hypothesis testing and confidence interval construction. This report examines their debiased LASSO framework, which yields asymptotically normal estimators in high-dimensional settings. We present the key theoretical results underlying this approach, specifically, the construction of an optimized debiased estimator that restores asymptotic normality, which enables the computation of valid confidence intervals and $p$-values. To evaluate the claims of Javanmard and Montanari, a subset of the original simulation study and a re-examination of their real-data analysis are presented. Building on this baseline, we extend the empirical analysis to include the desparsified LASSO, a closely related method referenced but not implemented in the original study. The results demonstrate that while the debiased LASSO achieves reliable coverage and controls Type I error, the LASSO projection estimator can offer improved power in low-signal settings without compromising error rates. Our findings highlight a critical practical trade-off: while the LASSO projection estimator demonstrates superior statistical power in an idealized simulated low-signal setting, the estimation procedure employed by Javanmard and Montanari adapts more robustly to complex correlation networks, yielding superior precision and signal detection in real-world genomic data.
fairmetrics: An R package for group fairness evaluation
Jun 06, 2025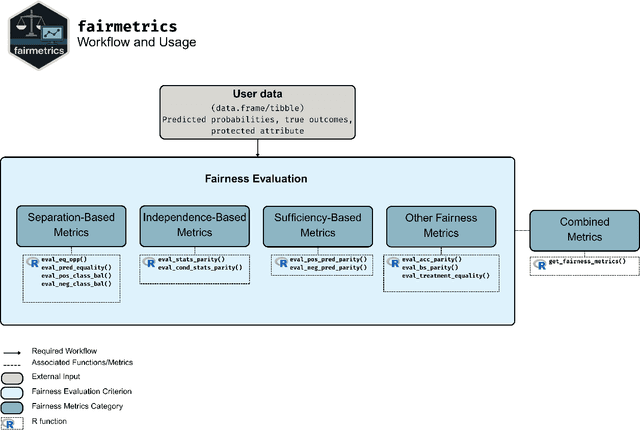
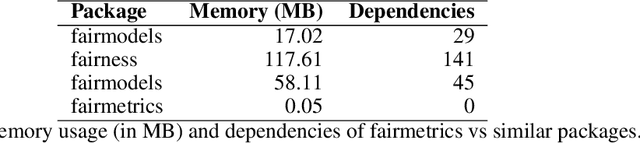
Fairness is a growing area of machine learning (ML) that focuses on ensuring models do not produce systematically biased outcomes for specific groups, particularly those defined by protected attributes such as race, gender, or age. Evaluating fairness is a critical aspect of ML model development, as biased models can perpetuate structural inequalities. The {fairmetrics} R package offers a user-friendly framework for rigorously evaluating numerous group-based fairness criteria, including metrics based on independence (e.g., statistical parity), separation (e.g., equalized odds), and sufficiency (e.g., predictive parity). Group-based fairness criteria assess whether a model is equally accurate or well-calibrated across a set of predefined groups so that appropriate bias mitigation strategies can be implemented. {fairmetrics} provides both point and interval estimates for multiple metrics through a convenient wrapper function and includes an example dataset derived from the Medical Information Mart for Intensive Care, version II (MIMIC-II) database (Goldberger et al., 2000; Raffa, 2016).
Creating a Cooperative AI Policymaking Platform through Open Source Collaboration
Dec 09, 2024

Advances in artificial intelligence (AI) present significant risks and opportunities, requiring improved governance to mitigate societal harms and promote equitable benefits. Current incentive structures and regulatory delays may hinder responsible AI development and deployment, particularly in light of the transformative potential of large language models (LLMs). To address these challenges, we propose developing the following three contributions: (1) a large multimodal text and economic-timeseries foundation model that integrates economic and natural language policy data for enhanced forecasting and decision-making, (2) algorithmic mechanisms for eliciting diverse and representative perspectives, enabling the creation of data-driven public policy recommendations, and (3) an AI-driven web platform for supporting transparent, inclusive, and data-driven policymaking.
Large Legislative Models: Towards Efficient AI Policymaking in Economic Simulations
Oct 10, 2024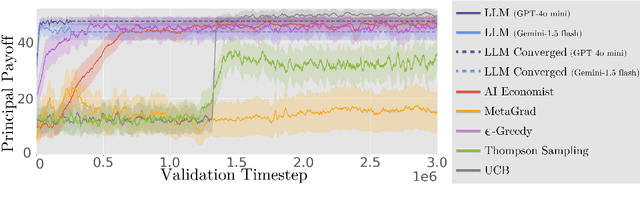
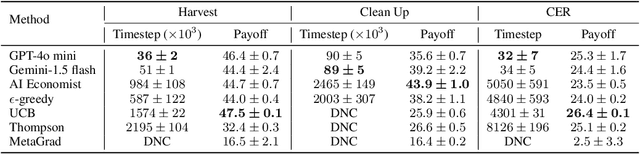
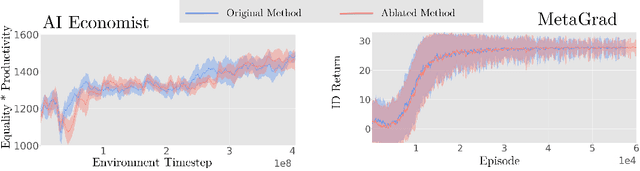
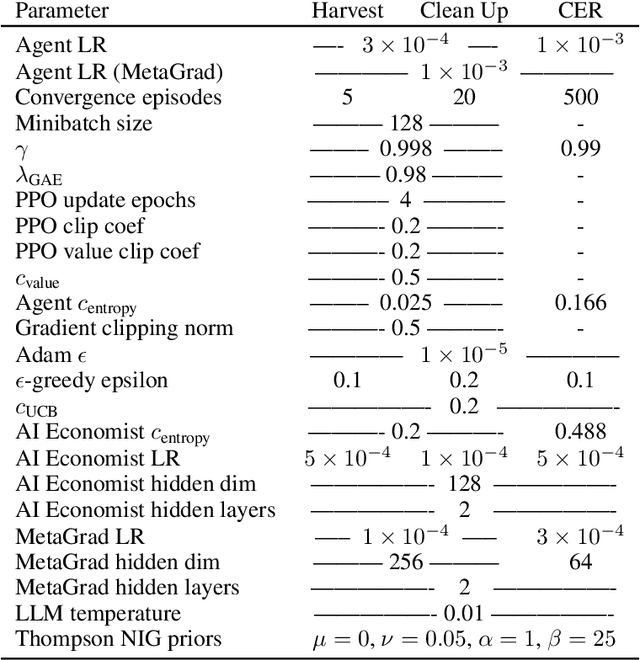
The improvement of economic policymaking presents an opportunity for broad societal benefit, a notion that has inspired research towards AI-driven policymaking tools. AI policymaking holds the potential to surpass human performance through the ability to process data quickly at scale. However, existing RL-based methods exhibit sample inefficiency, and are further limited by an inability to flexibly incorporate nuanced information into their decision-making processes. Thus, we propose a novel method in which we instead utilize pre-trained Large Language Models (LLMs), as sample-efficient policymakers in socially complex multi-agent reinforcement learning (MARL) scenarios. We demonstrate significant efficiency gains, outperforming existing methods across three environments. Our code is available at https://github.com/hegasz/large-legislative-models.
Ship Detection: Parameter Server Variant
Dec 02, 2020
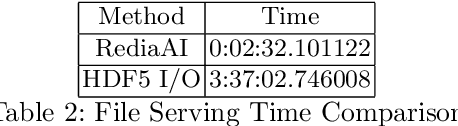
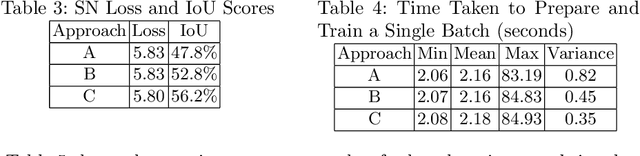

Deep learning ship detection in satellite optical imagery suffers from false positive occurrences with clouds, landmasses, and man-made objects that interfere with correct classification of ships, typically limiting class accuracy scores to 88\%. This work explores the tensions between customization strategies, class accuracy rates, training times, and costs in cloud based solutions. We demonstrate how a custom U-Net can achieve 92\% class accuracy over a validation dataset and 68\% over a target dataset with 90\% confidence. We also compare a single node architecture with a parameter server variant whose workers act as a boosting mechanism. The parameter server variant outperforms class accuracy on the target dataset reaching 73\% class accuracy compared to the best single node approach. A comparative investigation on the systematic performance of the single node and parameter server variant architectures is discussed with support from empirical findings.
Efficient Scene Compression for Visual-based Localization
Nov 27, 2020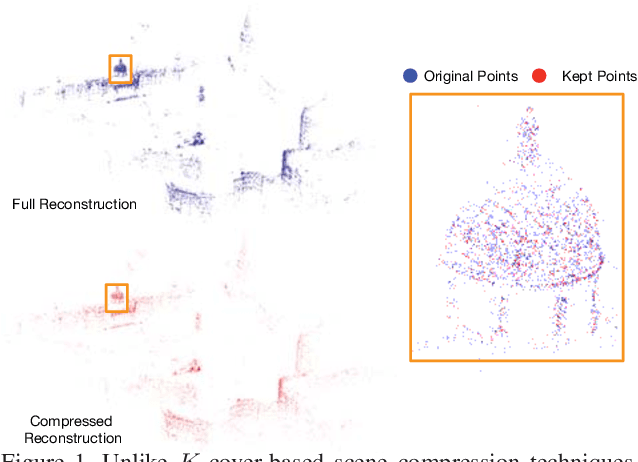
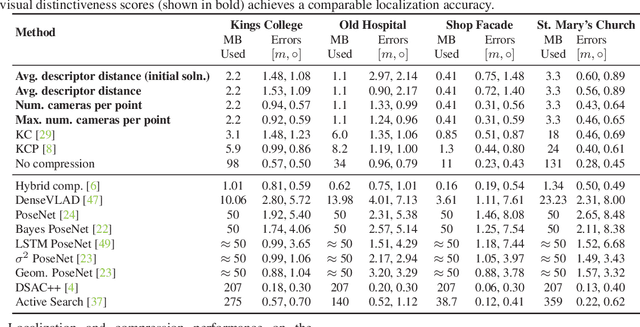
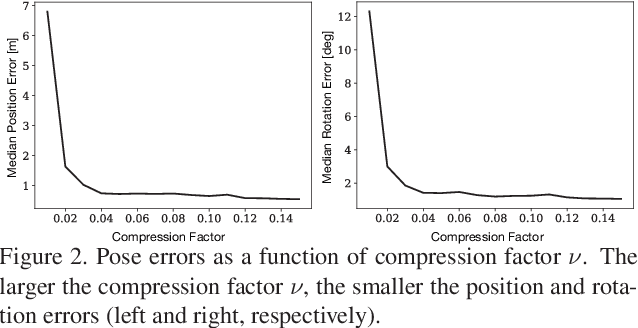

Estimating the pose of a camera with respect to a 3D reconstruction or scene representation is a crucial step for many mixed reality and robotics applications. Given the vast amount of available data nowadays, many applications constrain storage and/or bandwidth to work efficiently. To satisfy these constraints, many applications compress a scene representation by reducing its number of 3D points. While state-of-the-art methods use $K$-cover-based algorithms to compress a scene, they are slow and hard to tune. To enhance speed and facilitate parameter tuning, this work introduces a novel approach that compresses a scene representation by means of a constrained quadratic program (QP). Because this QP resembles a one-class support vector machine, we derive a variant of the sequential minimal optimization to solve it. Our approach uses the points corresponding to the support vectors as the subset of points to represent a scene. We also present an efficient initialization method that allows our method to converge quickly. Our experiments on publicly available datasets show that our approach compresses a scene representation quickly while delivering accurate pose estimates.
Bridging Scene Understanding and Task Execution with Flexible Simulation Environments
Nov 20, 2020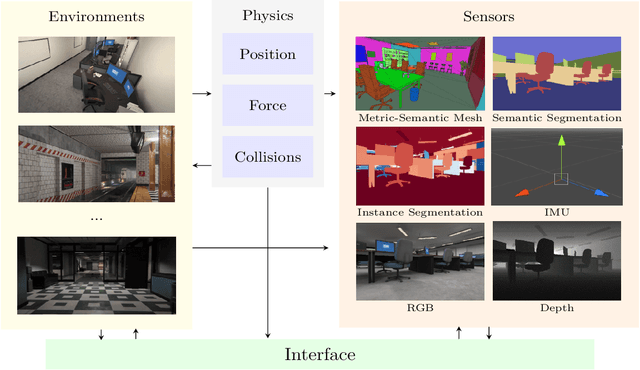

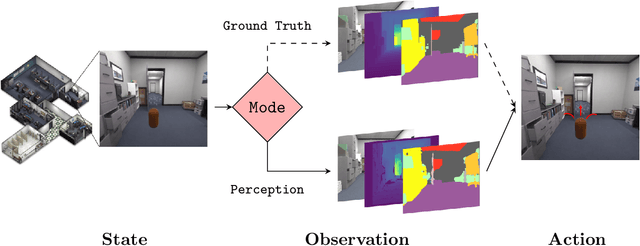
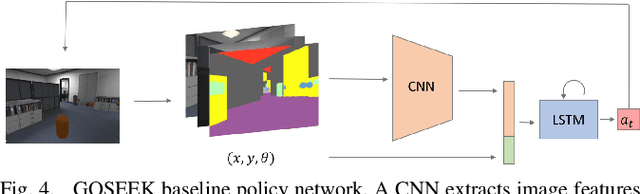
Significant progress has been made in scene understanding which seeks to build 3D, metric and object-oriented representations of the world. Concurrently, reinforcement learning has made impressive strides largely enabled by advances in simulation. Comparatively, there has been less focus in simulation for perception algorithms. Simulation is becoming increasingly vital as sophisticated perception approaches such as metric-semantic mapping or 3D dynamic scene graph generation require precise 3D, 2D, and inertial information in an interactive environment. To that end, we present TESSE (Task Execution with Semantic Segmentation Environments), an open source simulator for developing scene understanding and task execution algorithms. TESSE has been used to develop state-of-the-art solutions for metric-semantic mapping and 3D dynamic scene graph generation. Additionally, TESSE served as the platform for the GOSEEK Challenge at the International Conference of Robotics and Automation (ICRA) 2020, an object search competition with an emphasis on reinforcement learning. Code for TESSE is available at https://github.com/MIT-TESSE.
Anomaly Detection with SDAE
Apr 09, 2020
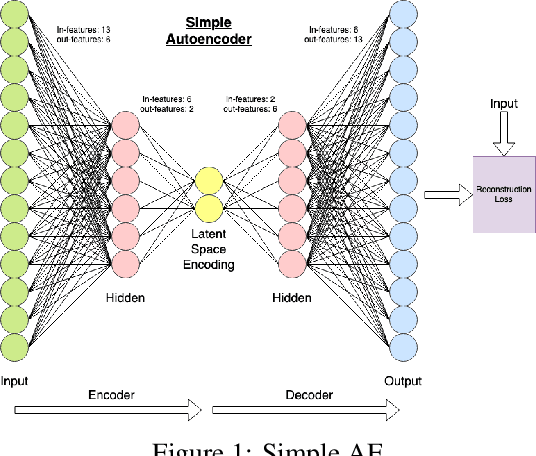

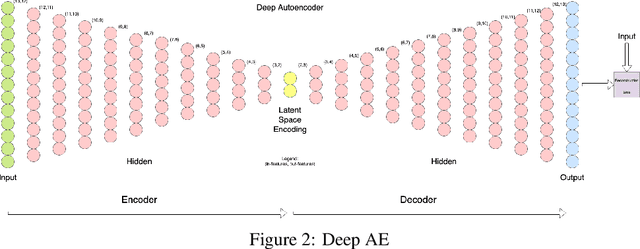
Anomaly detection is a prominent data preprocessing step in learning applications for correction and/or removal of faulty data. Automating this data type with the use of autoencoders could increase the quality of the dataset by isolating anomalies that were missed through manual or basic statistical analysis. A Simple, Deep, and Supervised Deep Autoencoder were trained and compared for anomaly detection over the ASHRAE building energy dataset. Given the restricted parameters under which the models were trained, the Deep Autoencoder perfoms the best, however, the Supervised Deep Autoencoder outperforms the other models in total anomalies detected when considerations for the test datasets are given.