 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Interest Point Detection and Description for Fisheye and Perspective Images
Jun 02, 2023



Keypoint detection and matching is a fundamental task in many computer vision problems, from shape reconstruction, to structure from motion, to AR/VR applications and robotics. It is a well-studied problem with remarkable successes such as SIFT, and more recent deep learning approaches. While great robustness is exhibited by these techniques with respect to noise, illumination variation, and rigid motion transformations, less attention has been placed on image distortion sensitivity. In this work, we focus on the case when this is caused by the geometry of the cameras used for image acquisition, and consider the keypoint detection and matching problem between the hybrid scenario of a fisheye and a projective image. We build on a state-of-the-art approach and derive a self-supervised procedure that enables training an interest point detector and descriptor network. We also collected two new datasets for additional training and testing in this unexplored scenario, and we demonstrate that current approaches are suboptimal because they are designed to work in traditional projective conditions, while the proposed approach turns out to be the most effective.
Efficient Scene Compression for Visual-based Localization
Nov 27, 2020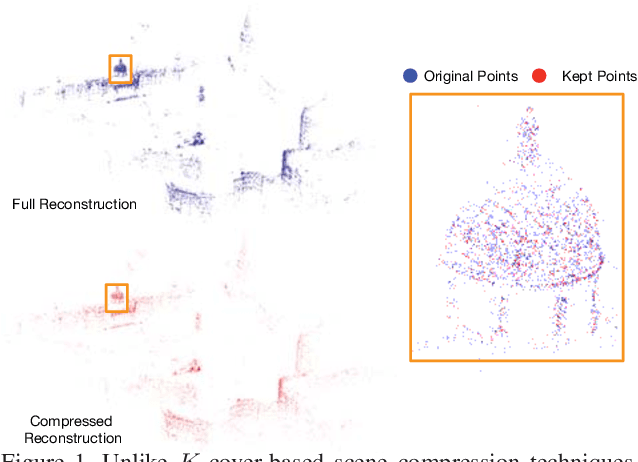
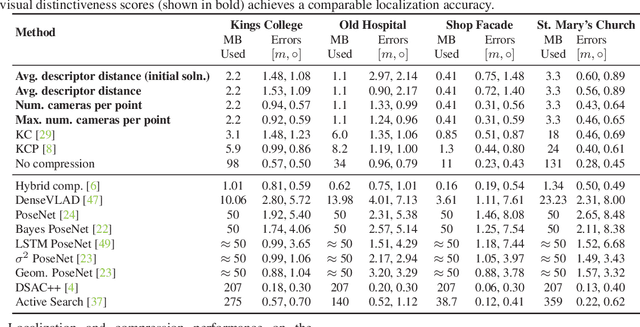
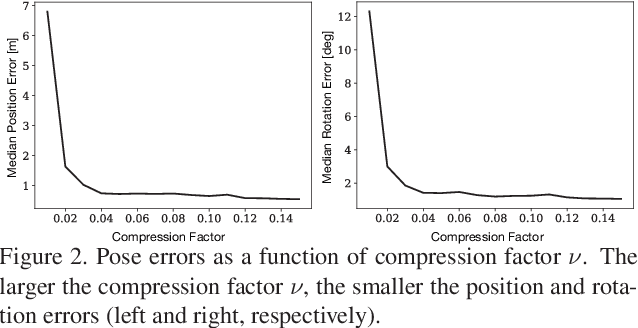

Estimating the pose of a camera with respect to a 3D reconstruction or scene representation is a crucial step for many mixed reality and robotics applications. Given the vast amount of available data nowadays, many applications constrain storage and/or bandwidth to work efficiently. To satisfy these constraints, many applications compress a scene representation by reducing its number of 3D points. While state-of-the-art methods use $K$-cover-based algorithms to compress a scene, they are slow and hard to tune. To enhance speed and facilitate parameter tuning, this work introduces a novel approach that compresses a scene representation by means of a constrained quadratic program (QP). Because this QP resembles a one-class support vector machine, we derive a variant of the sequential minimal optimization to solve it. Our approach uses the points corresponding to the support vectors as the subset of points to represent a scene. We also present an efficient initialization method that allows our method to converge quickly. Our experiments on publicly available datasets show that our approach compresses a scene representation quickly while delivering accurate pose estimates.