 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Galaxy Cluster Mass Maps using Score-based Generative Modeling
Oct 03, 2024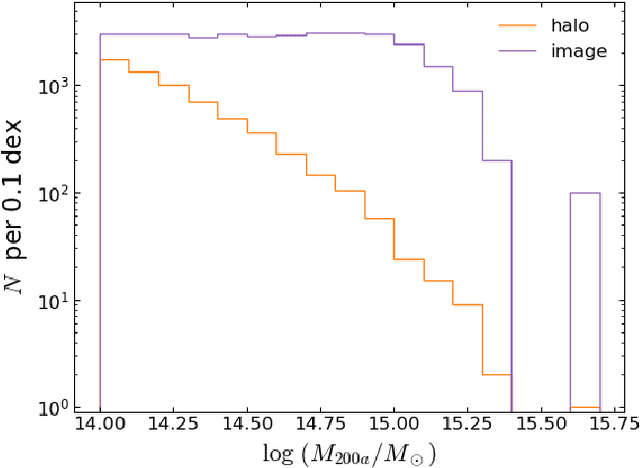


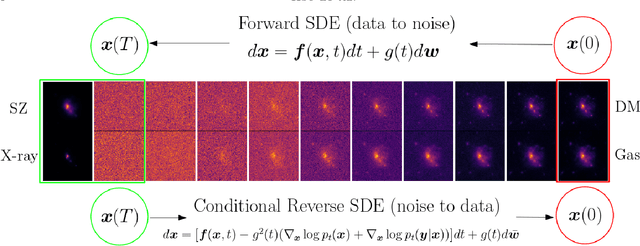
We present a novel approach to reconstruct gas and dark matter projected density maps of galaxy clusters using score-based generative modeling. Our diffusion model takes in mock SZ and X-ray images as conditional observations, and generates realizations of corresponding gas and dark matter maps by sampling from a learned data posterior. We train and validate the performance of our model by using mock data from a hydrodynamical cosmological simulation. The model accurately reconstructs both the mean and spread of the radial density profiles in the spatial domain to within 5\%, indicating that the model is able to distinguish between clusters of different sizes. In the spectral domain, the model achieves close-to-unity values for the bias and cross-correlation coefficients, indicating that the model can accurately probe cluster structures on both large and small scales. Our experiments demonstrate the ability of score models to learn a strong, nonlinear, and unbiased mapping between input observables and fundamental density distributions of galaxy clusters. These diffusion models can be further fine-tuned and generalized to not only take in additional observables as inputs, but also real observations and predict unknown density distributions of galaxy clusters.
Designing an Evaluation Framework for Large Language Models in Astronomy Research
May 30, 2024


Large Language Models (LLMs) are shifting how scientific research is done. It is imperative to understand how researchers interact with these models and how scientific sub-communities like astronomy might benefit from them. However, there is currently no standard for evaluating the use of LLMs in astronomy. Therefore, we present the experimental design for an evaluation study on how astronomy researchers interact with LLMs. We deploy a Slack chatbot that can answer queries from users via Retrieval-Augmented Generation (RAG); these responses are grounded in astronomy papers from arXiv. We record and anonymize user questions and chatbot answers, user upvotes and downvotes to LLM responses, user feedback to the LLM, and retrieved documents and similarity scores with the query. Our data collection method will enable future dynamic evaluations of LLM tools for astronomy.
Algorithms and Statistical Models for Scientific Discovery in the Petabyte Era
Nov 05, 2019The field of astronomy has arrived at a turning point in terms of size and complexity of both datasets and scientific collaboration. Commensurately, algorithms and statistical models have begun to adapt --- e.g., via the onset of artificial intelligence --- which itself presents new challenges and opportunities for growth. This white paper aims to offer guidance and ideas for how we can evolve our technical and collaborative frameworks to promote efficient algorithmic development and take advantage of opportunities for scientific discovery in the petabyte era. We discuss challenges for discovery in large and complex data sets; challenges and requirements for the next stage of development of statistical methodologies and algorithmic tool sets; how we might change our paradigms of collaboration and education; and the ethical implications of scientists' contributions to widely applicable algorithms and computational modeling. We start with six distinct recommendations that are supported by the commentary following them. This white paper is related to a larger corpus of effort that has taken place within and around the Petabytes to Science Workshops (https://petabytestoscience.github.io/).