 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Dense Embeddings with Sparse Autoencoders
Aug 05, 2024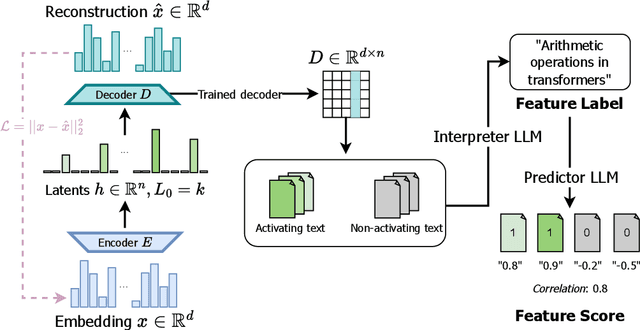
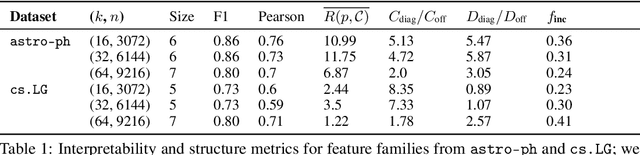
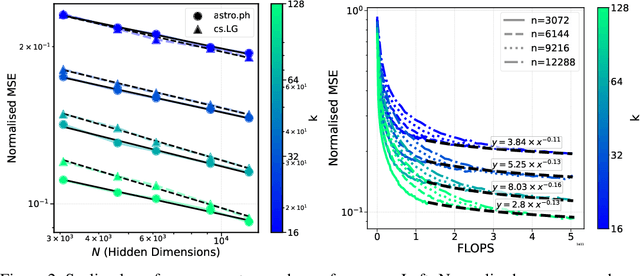
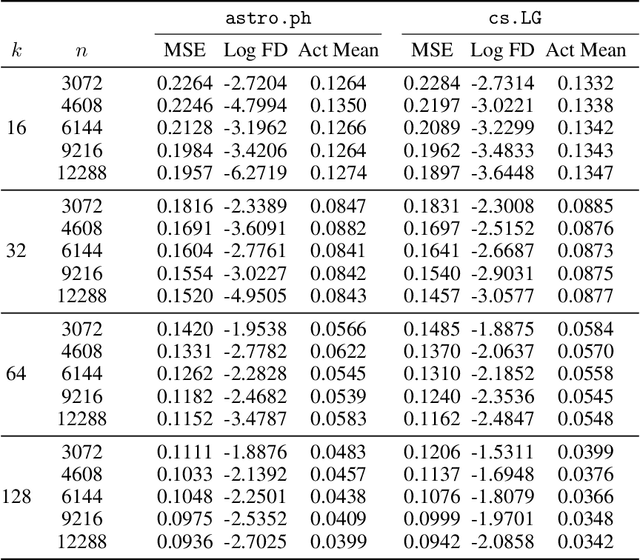
Sparse autoencoders (SAEs) have shown promise in extracting interpretable features from complex neural networks. We present one of the first applications of SAEs to dense text embeddings from large language models, demonstrating their effectiveness in disentangling semantic concepts. By training SAEs on embeddings of over 420,000 scientific paper abstracts from computer science and astronomy, we show that the resulting sparse representations maintain semantic fidelity while offering interpretability. We analyse these learned features, exploring their behaviour across different model capacities and introducing a novel method for identifying ``feature families'' that represent related concepts at varying levels of abstraction. To demonstrate the practical utility of our approach, we show how these interpretable features can be used to precisely steer semantic search, allowing for fine-grained control over query semantics. This work bridges the gap between the semantic richness of dense embeddings and the interpretability of sparse representations. We open source our embeddings, trained sparse autoencoders, and interpreted features, as well as a web app for exploring them.
Designing an Evaluation Framework for Large Language Models in Astronomy Research
May 30, 2024


Large Language Models (LLMs) are shifting how scientific research is done. It is imperative to understand how researchers interact with these models and how scientific sub-communities like astronomy might benefit from them. However, there is currently no standard for evaluating the use of LLMs in astronomy. Therefore, we present the experimental design for an evaluation study on how astronomy researchers interact with LLMs. We deploy a Slack chatbot that can answer queries from users via Retrieval-Augmented Generation (RAG); these responses are grounded in astronomy papers from arXiv. We record and anonymize user questions and chatbot answers, user upvotes and downvotes to LLM responses, user feedback to the LLM, and retrieved documents and similarity scores with the query. Our data collection method will enable future dynamic evaluations of LLM tools for astronomy.
AstroLLaMA-Chat: Scaling AstroLLaMA with Conversational and Diverse Datasets
Jan 05, 2024We explore the potential of enhancing LLM performance in astronomy-focused question-answering through targeted, continual pre-training. By employing a compact 7B-parameter LLaMA-2 model and focusing exclusively on a curated set of astronomy corpora -- comprising abstracts, introductions, and conclusions -- we achieve notable improvements in specialized topic comprehension. While general LLMs like GPT-4 excel in broader question-answering scenarios due to superior reasoning capabilities, our findings suggest that continual pre-training with limited resources can still enhance model performance on specialized topics. Additionally, we present an extension of AstroLLaMA: the fine-tuning of the 7B LLaMA model on a domain-specific conversational dataset, culminating in the release of the chat-enabled AstroLLaMA for community use. Comprehensive quantitative benchmarking is currently in progress and will be detailed in an upcoming full paper. The model, AstroLLaMA-Chat, is now available at https://huggingface.co/universeTBD, providing the first open-source conversational AI tool tailored for the astronomy community.
AstroLLaMA: Towards Specialized Foundation Models in Astronomy
Sep 12, 2023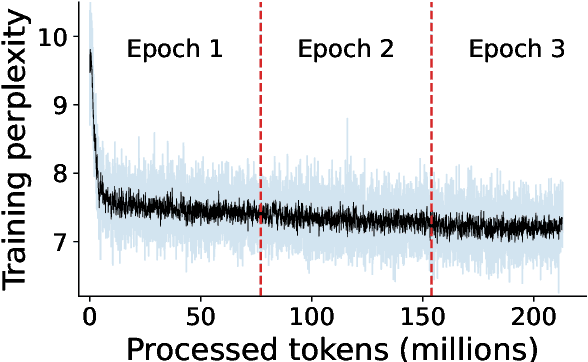

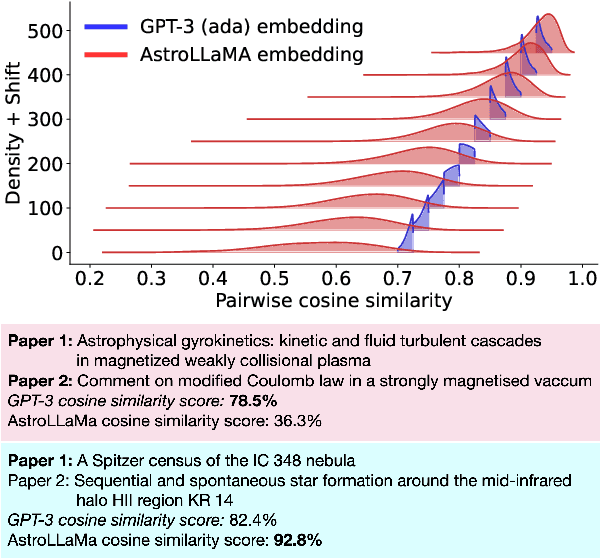
Large language models excel in many human-language tasks but often falter in highly specialized domains like scholarly astronomy. To bridge this gap, we introduce AstroLLaMA, a 7-billion-parameter model fine-tuned from LLaMA-2 using over 300,000 astronomy abstracts from arXiv. Optimized for traditional causal language modeling, AstroLLaMA achieves a 30% lower perplexity than Llama-2, showing marked domain adaptation. Our model generates more insightful and scientifically relevant text completions and embedding extraction than state-of-the-arts foundation models despite having significantly fewer parameters. AstroLLaMA serves as a robust, domain-specific model with broad fine-tuning potential. Its public release aims to spur astronomy-focused research, including automatic paper summarization and conversational agent development.
Harnessing the Power of Adversarial Prompting and Large Language Models for Robust Hypothesis Generation in Astronomy
Jun 20, 2023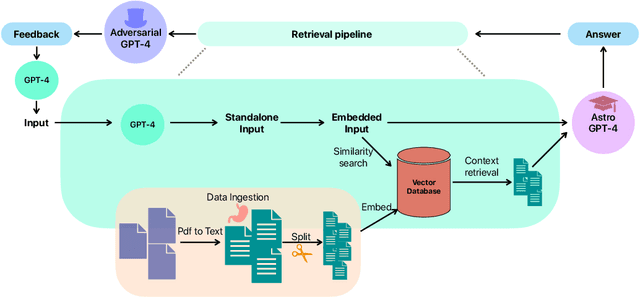
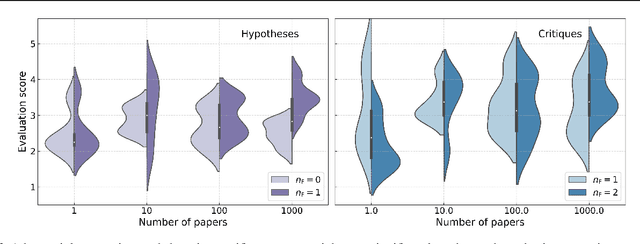
This study investigates the application of Large Language Models (LLMs), specifically GPT-4, within Astronomy. We employ in-context prompting, supplying the model with up to 1000 papers from the NASA Astrophysics Data System, to explore the extent to which performance can be improved by immersing the model in domain-specific literature. Our findings point towards a substantial boost in hypothesis generation when using in-context prompting, a benefit that is further accentuated by adversarial prompting. We illustrate how adversarial prompting empowers GPT-4 to extract essential details from a vast knowledge base to produce meaningful hypotheses, signaling an innovative step towards employing LLMs for scientific research in Astronomy.