 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Dense Embeddings with Sparse Autoencoders
Paper and Code
Aug 05, 2024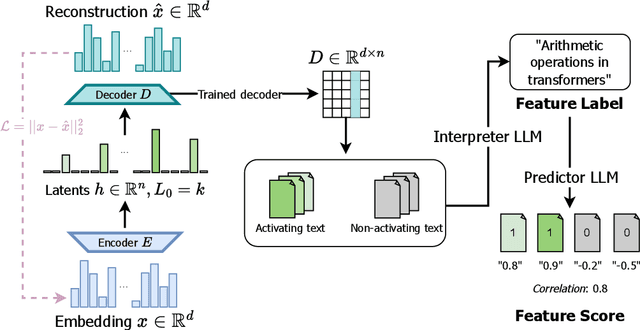
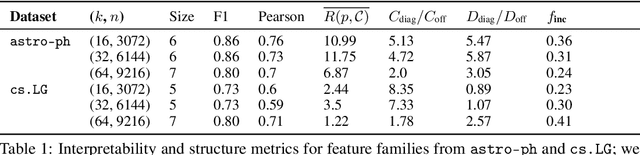
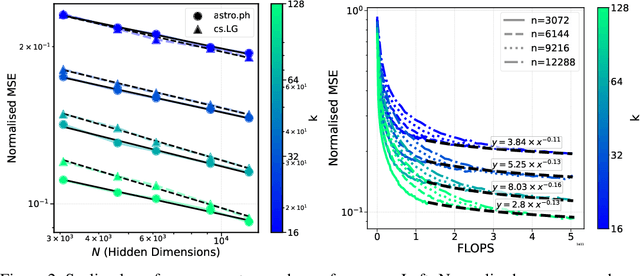
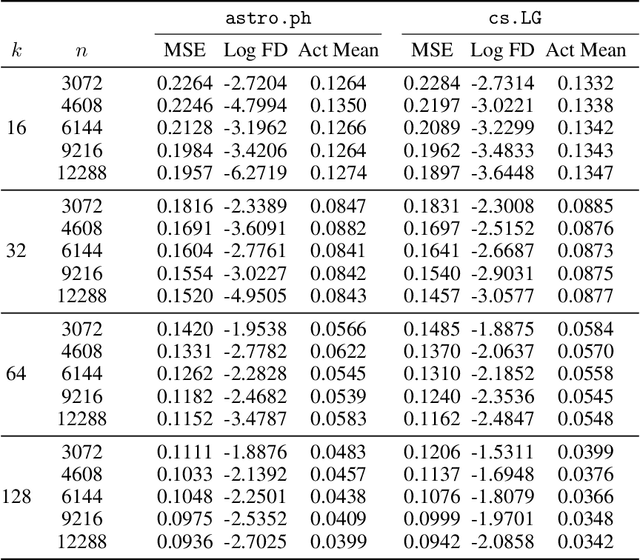
Sparse autoencoders (SAEs) have shown promise in extracting interpretable features from complex neural networks. We present one of the first applications of SAEs to dense text embeddings from large language models, demonstrating their effectiveness in disentangling semantic concepts. By training SAEs on embeddings of over 420,000 scientific paper abstracts from computer science and astronomy, we show that the resulting sparse representations maintain semantic fidelity while offering interpretability. We analyse these learned features, exploring their behaviour across different model capacities and introducing a novel method for identifying ``feature families'' that represent related concepts at varying levels of abstraction. To demonstrate the practical utility of our approach, we show how these interpretable features can be used to precisely steer semantic search, allowing for fine-grained control over query semantics. This work bridges the gap between the semantic richness of dense embeddings and the interpretability of sparse representations. We open source our embeddings, trained sparse autoencoders, and interpreted features, as well as a web app for exploring them.