 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHARM: Creating Halos with Auto-Regressive Multi-stage networks
Sep 13, 2024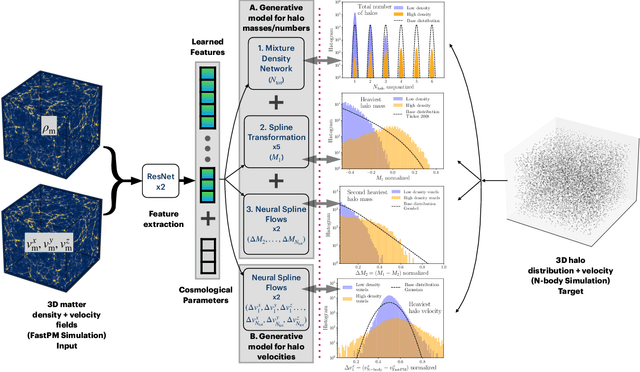
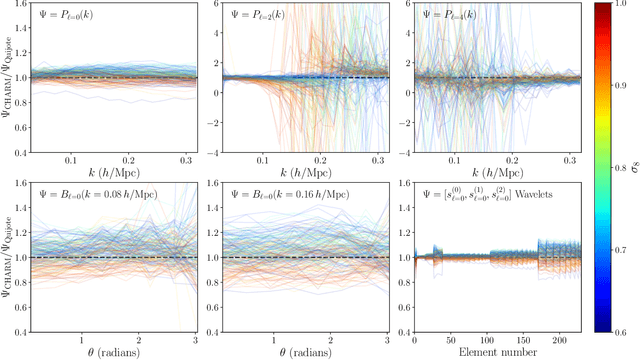
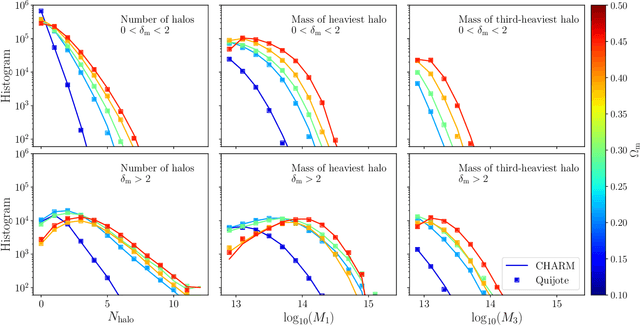
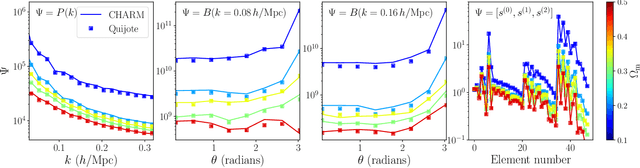
To maximize the amount of information extracted from cosmological datasets, simulations that accurately represent these observations are necessary. However, traditional simulations that evolve particles under gravity by estimating particle-particle interactions (N-body simulations) are computationally expensive and prohibitive to scale to the large volumes and resolutions necessary for the upcoming datasets. Moreover, modeling the distribution of galaxies typically involves identifying virialized dark matter halos, which is also a time- and memory-consuming process for large N-body simulations, further exacerbating the computational cost. In this study, we introduce CHARM, a novel method for creating mock halo catalogs by matching the spatial, mass, and velocity statistics of halos directly from the large-scale distribution of the dark matter density field. We develop multi-stage neural spline flow-based networks to learn this mapping at redshift z=0.5 directly with computationally cheaper low-resolution particle mesh simulations instead of relying on the high-resolution N-body simulations. We show that the mock halo catalogs and painted galaxy catalogs have the same statistical properties as obtained from $N$-body simulations in both real space and redshift space. Finally, we use these mock catalogs for cosmological inference using redshift-space galaxy power spectrum, bispectrum, and wavelet-based statistics using simulation-based inference, performing the first inference with accelerated forward model simulations and finding unbiased cosmological constraints with well-calibrated posteriors. The code was developed as part of the Simons Collaboration on Learning the Universe and is publicly available at \url{https://github.com/shivampcosmo/CHARM}.
LtU-ILI: An All-in-One Framework for Implicit Inference in Astrophysics and Cosmology
Feb 06, 2024



This paper presents the Learning the Universe Implicit Likelihood Inference (LtU-ILI) pipeline, a codebase for rapid, user-friendly, and cutting-edge machine learning (ML) inference in astrophysics and cosmology. The pipeline includes software for implementing various neural architectures, training schema, priors, and density estimators in a manner easily adaptable to any research workflow. It includes comprehensive validation metrics to assess posterior estimate coverage, enhancing the reliability of inferred results. Additionally, the pipeline is easily parallelizable, designed for efficient exploration of modeling hyperparameters. To demonstrate its capabilities, we present real applications across a range of astrophysics and cosmology problems, such as: estimating galaxy cluster masses from X-ray photometry; inferring cosmology from matter power spectra and halo point clouds; characterising progenitors in gravitational wave signals; capturing physical dust parameters from galaxy colors and luminosities; and establishing properties of semi-analytic models of galaxy formation. We also include exhaustive benchmarking and comparisons of all implemented methods as well as discussions about the challenges and pitfalls of ML inference in astronomical sciences. All code and examples are made publicly available at https://github.com/maho3/ltu-ili.
Robust field-level inference with dark matter halos
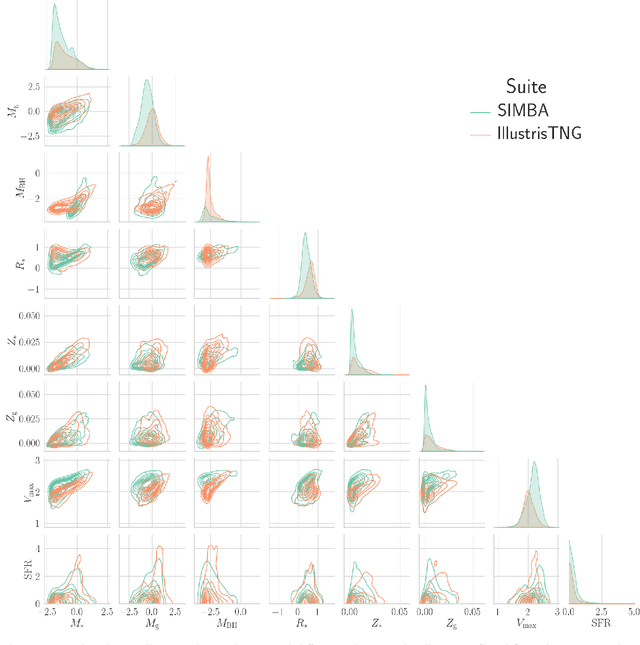
Sep 14, 2022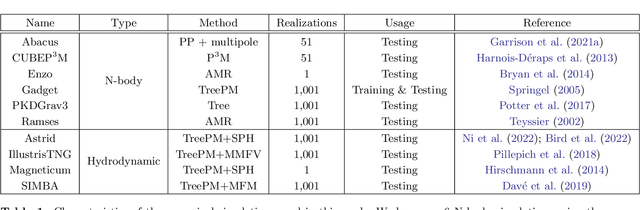
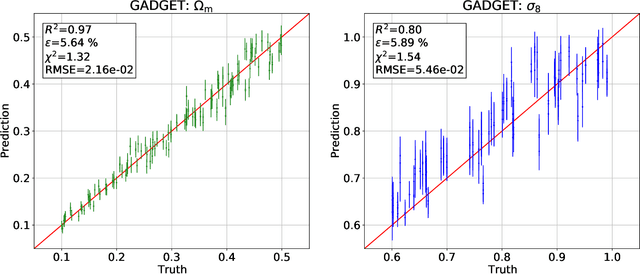
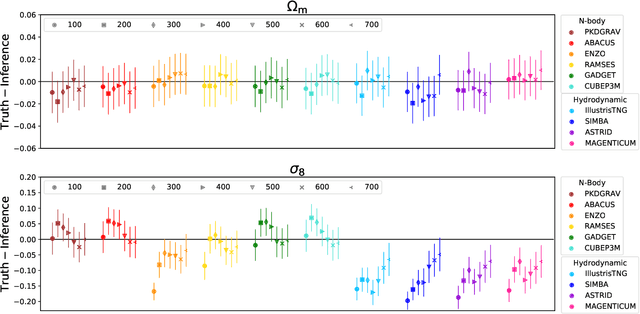

We train graph neural networks on halo catalogues from Gadget N-body simulations to perform field-level likelihood-free inference of cosmological parameters. The catalogues contain $\lesssim$5,000 halos with masses $\gtrsim 10^{10}~h^{-1}M_\odot$ in a periodic volume of $(25~h^{-1}{\rm Mpc})^3$; every halo in the catalogue is characterized by several properties such as position, mass, velocity, concentration, and maximum circular velocity. Our models, built to be permutationally, translationally, and rotationally invariant, do not impose a minimum scale on which to extract information and are able to infer the values of $\Omega_{\rm m}$ and $\sigma_8$ with a mean relative error of $\sim6\%$, when using positions plus velocities and positions plus masses, respectively. More importantly, we find that our models are very robust: they can infer the value of $\Omega_{\rm m}$ and $\sigma_8$ when tested using halo catalogues from thousands of N-body simulations run with five different N-body codes: Abacus, CUBEP$^3$M, Enzo, PKDGrav3, and Ramses. Surprisingly, the model trained to infer $\Omega_{\rm m}$ also works when tested on thousands of state-of-the-art CAMELS hydrodynamic simulations run with four different codes and subgrid physics implementations. Using halo properties such as concentration and maximum circular velocity allow our models to extract more information, at the expense of breaking the robustness of the models. This may happen because the different N-body codes are not converged on the relevant scales corresponding to these parameters.
The CAMELS project: public data release
Jan 04, 2022
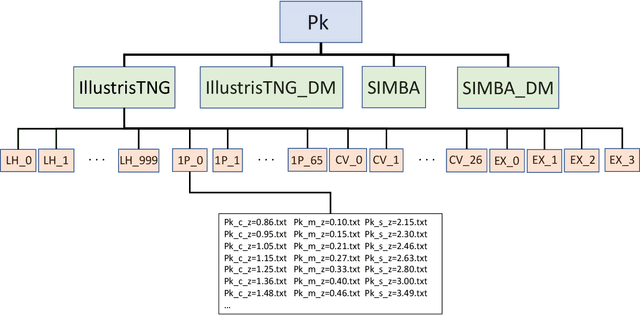
The Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) project was developed to combine cosmology with astrophysics through thousands of cosmological hydrodynamic simulations and machine learning. CAMELS contains 4,233 cosmological simulations, 2,049 N-body and 2,184 state-of-the-art hydrodynamic simulations that sample a vast volume in parameter space. In this paper we present the CAMELS public data release, describing the characteristics of the CAMELS simulations and a variety of data products generated from them, including halo, subhalo, galaxy, and void catalogues, power spectra, bispectra, Lyman-$\alpha$ spectra, probability distribution functions, halo radial profiles, and X-rays photon lists. We also release over one thousand catalogues that contain billions of galaxies from CAMELS-SAM: a large collection of N-body simulations that have been combined with the Santa Cruz Semi-Analytic Model. We release all the data, comprising more than 350 terabytes and containing 143,922 snapshots, millions of halos, galaxies and summary statistics. We provide further technical details on how to access, download, read, and process the data at \url{https://camels.readthedocs.io}.