 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCLA: A Framework for Testing Autonomous Agents in the CARLA Simulator
Mar 13, 2025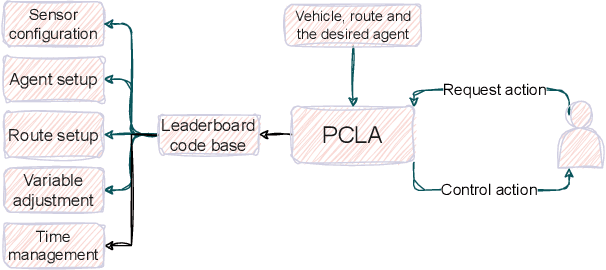
Recent research on testing autonomous driving agents has grown significantly, especially in simulation environments. The CARLA simulator is often the preferred choice, and the autonomous agents from the CARLA Leaderboard challenge are regarded as the best-performing agents within this environment. However, researchers who test these agents, rather than training their own ones from scratch, often face challenges in utilizing them within customized test environments and scenarios. To address these challenges, we introduce PCLA (Pretrained CARLA Leaderboard Agents), an open-source Python testing framework that includes nine high-performing pre-trained autonomous agents from the Leaderboard challenges. PCLA is the first infrastructure specifically designed for testing various autonomous agents in arbitrary CARLA environments/scenarios. PCLA provides a simple way to deploy Leaderboard agents onto a vehicle without relying on the Leaderboard codebase, it allows researchers to easily switch between agents without requiring modifications to CARLA versions or programming environments, and it is fully compatible with the latest version of CARLA while remaining independent of the Leaderboard's specific CARLA version. PCLA is publicly accessible at https://github.com/MasoudJTehrani/PCLA.
XSS Adversarial Attacks Based on Deep Reinforcement Learning: A Replication and Extension Study
Feb 26, 2025Cross-site scripting (XSS) poses a significant threat to web application security. While Deep Learning (DL) has shown remarkable success in detecting XSS attacks, it remains vulnerable to adversarial attacks due to the discontinuous nature of its input-output mapping. These adversarial attacks employ mutation-based strategies for different components of XSS attack vectors, allowing adversarial agents to iteratively select mutations to evade detection. Our work replicates a state-of-the-art XSS adversarial attack, highlighting threats to validity in the reference work and extending it toward a more effective evaluation strategy. Moreover, we introduce an XSS Oracle to mitigate these threats. The experimental results show that our approach achieves an escape rate above 96% when the threats to validity of the replicated technique are addressed.
Real Faults in Deep Learning Fault Benchmarks: How Real Are They?
Dec 20, 2024



As the adoption of Deep Learning (DL) systems continues to rise, an increasing number of approaches are being proposed to test these systems, localise faults within them, and repair those faults. The best attestation of effectiveness for such techniques is an evaluation that showcases their capability to detect, localise and fix real faults. To facilitate these evaluations, the research community has collected multiple benchmarks of real faults in DL systems. In this work, we perform a manual analysis of 490 faults from five different benchmarks and identify that 314 of them are eligible for our study. Our investigation focuses specifically on how well the bugs correspond to the sources they were extracted from, which fault types are represented, and whether the bugs are reproducible. Our findings indicate that only 18.5% of the faults satisfy our realism conditions. Our attempts to reproduce these faults were successful only in 52% of cases.
An Empirical Study of Fault Localisation Techniques for Deep Learning
Dec 17, 2024With the increased popularity of Deep Neural Networks (DNNs), increases also the need for tools to assist developers in the DNN implementation, testing and debugging process. Several approaches have been proposed that automatically analyse and localise potential faults in DNNs under test. In this work, we evaluate and compare existing state-of-the-art fault localisation techniques, which operate based on both dynamic and static analysis of the DNN. The evaluation is performed on a benchmark consisting of both real faults obtained from bug reporting platforms and faulty models produced by a mutation tool. Our findings indicate that the usage of a single, specific ground truth (e.g., the human defined one) for the evaluation of DNN fault localisation tools results in pretty low performance (maximum average recall of 0.31 and precision of 0.23). However, such figures increase when considering alternative, equivalent patches that exist for a given faulty DNN. Results indicate that \dfd is the most effective tool, achieving an average recall of 0.61 and precision of 0.41 on our benchmark.
Reducing DNN Labelling Cost using Surprise Adequacy: An Industrial Case Study for Autonomous Driving
May 29, 2020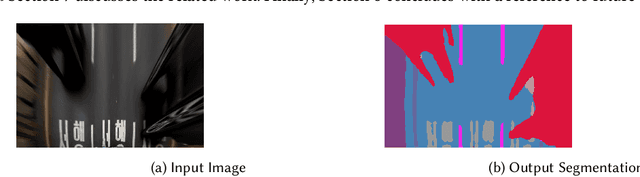
Deep Neural Networks (DNNs) are rapidly being adopted by the automotive industry, due to their impressive performance in tasks that are essential for autonomous driving. Object segmentation is one such task: its aim is to precisely locate boundaries of objects and classify the identified objects, helping autonomous cars to recognise the road environment and the traffic situation. Not only is this task safety critical, but developing a DNN based object segmentation module presents a set of challenges that are significantly different from traditional development of safety critical software. The development process in use consists of multiple iterations of data collection, labelling, training, and evaluation. Among these stages, training and evaluation are computation intensive while data collection and labelling are manual labour intensive. This paper shows how development of DNN based object segmentation can be improved by exploiting the correlation between Surprise Adequacy (SA) and model performance. The correlation allows us to predict model performance for inputs without manually labelling them. This, in turn, enables understanding of model performance, more guided data collection, and informed decisions about further training. In our industrial case study the technique allows cost savings of up to 50% with negligible evaluation inaccuracy. Furthermore, engineers can trade off cost savings versus the tolerable level of inaccuracy depending on different development phases and scenarios.
Guiding Deep Learning System Testing using Surprise Adequacy
Aug 25, 2018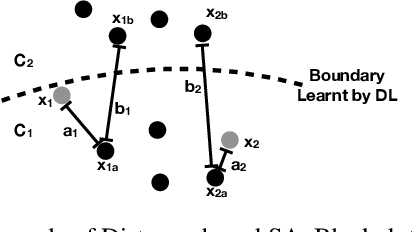
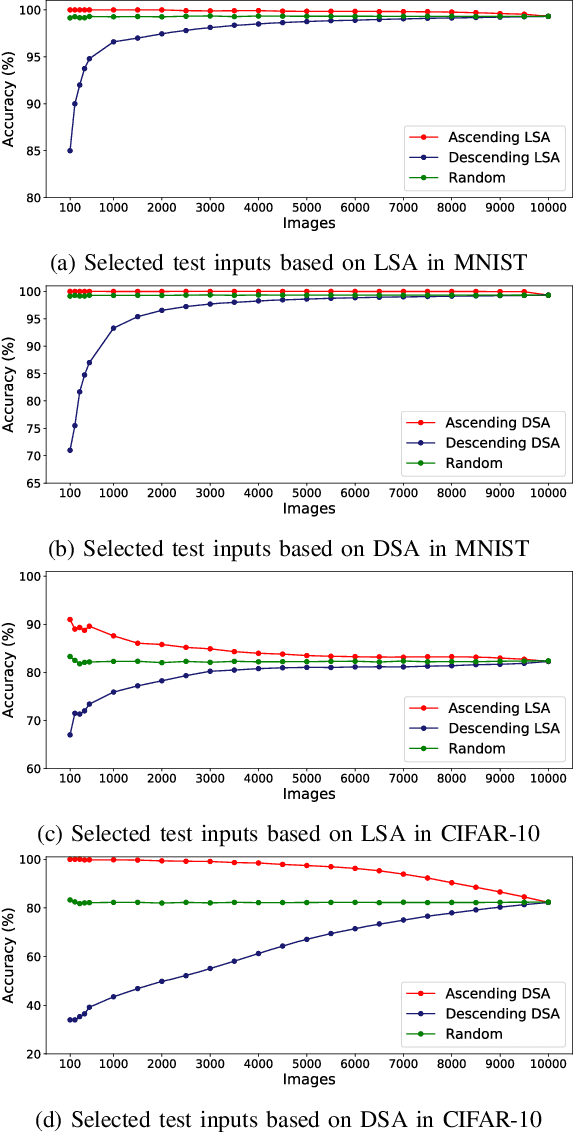

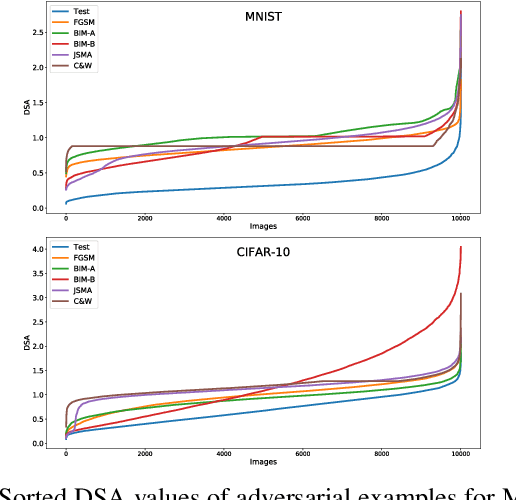
Deep Learning (DL) systems are rapidly being adopted in safety and security critical domains, urgently calling for ways to test their correctness and robustness. Testing of DL systems has traditionally relied on manual collection and labelling of data. Recently, a number of coverage criteria based on neuron activation values have been proposed. These criteria essentially count the number of neurons whose activation during the execution of a DL system satisfied certain properties, such as being above predefined thresholds. However, existing coverage criteria are not sufficiently fine grained to capture subtle behaviours exhibited by DL systems. Moreover, evaluations have focused on showing correlation between adversarial examples and proposed criteria rather than evaluating and guiding their use for actual testing of DL systems. We propose a novel test adequacy criterion for testing of DL systems, called Surprise Adequacy for Deep Learning Systems (SADL), which is based on the behaviour of DL systems with respect to their training data. We measure the surprise of an input as the difference in DL system's behaviour between the input and the training data (i.e., what was learnt during training), and subsequently develop this as an adequacy criterion: a good test input should be sufficiently but not overtly surprising compared to training data. Empirical evaluation using a range of DL systems from simple image classifiers to autonomous driving car platforms shows that systematic sampling of inputs based on their surprise can improve classification accuracy of DL systems against adversarial examples by up to 77.5% via retraining.