 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Research and Practice in Simulation-based Testing of Industrial Robot Navigation Systems
Oct 10, 2025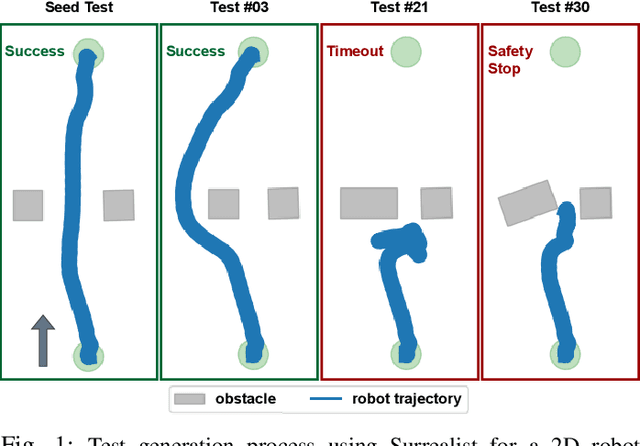
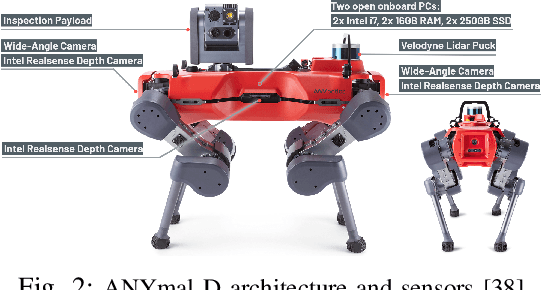
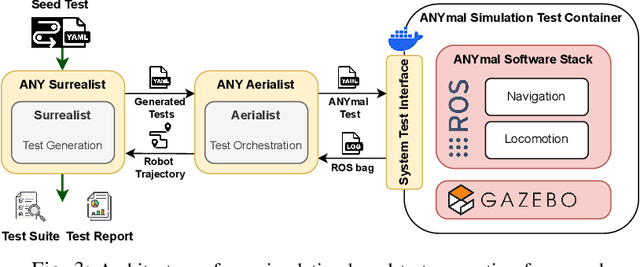
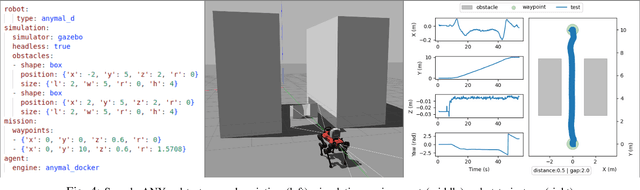
Ensuring robust robotic navigation in dynamic environments is a key challenge, as traditional testing methods often struggle to cover the full spectrum of operational requirements. This paper presents the industrial adoption of Surrealist, a simulation-based test generation framework originally for UAVs, now applied to the ANYmal quadrupedal robot for industrial inspection. Our method uses a search-based algorithm to automatically generate challenging obstacle avoidance scenarios, uncovering failures often missed by manual testing. In a pilot phase, generated test suites revealed critical weaknesses in one experimental algorithm (40.3% success rate) and served as an effective benchmark to prove the superior robustness of another (71.2% success rate). The framework was then integrated into the ANYbotics workflow for a six-month industrial evaluation, where it was used to test five proprietary algorithms. A formal survey confirmed its value, showing it enhances the development process, uncovers critical failures, provides objective benchmarks, and strengthens the overall verification pipeline.
PCLA: A Framework for Testing Autonomous Agents in the CARLA Simulator
Mar 13, 2025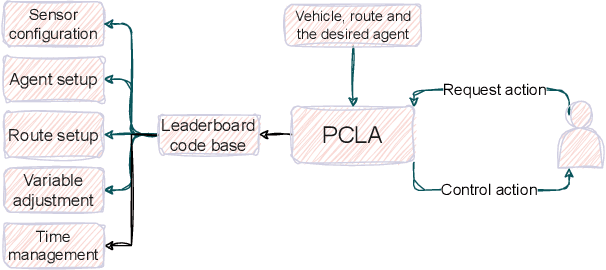
Recent research on testing autonomous driving agents has grown significantly, especially in simulation environments. The CARLA simulator is often the preferred choice, and the autonomous agents from the CARLA Leaderboard challenge are regarded as the best-performing agents within this environment. However, researchers who test these agents, rather than training their own ones from scratch, often face challenges in utilizing them within customized test environments and scenarios. To address these challenges, we introduce PCLA (Pretrained CARLA Leaderboard Agents), an open-source Python testing framework that includes nine high-performing pre-trained autonomous agents from the Leaderboard challenges. PCLA is the first infrastructure specifically designed for testing various autonomous agents in arbitrary CARLA environments/scenarios. PCLA provides a simple way to deploy Leaderboard agents onto a vehicle without relying on the Leaderboard codebase, it allows researchers to easily switch between agents without requiring modifications to CARLA versions or programming environments, and it is fully compatible with the latest version of CARLA while remaining independent of the Leaderboard's specific CARLA version. PCLA is publicly accessible at https://github.com/MasoudJTehrani/PCLA.
XSS Adversarial Attacks Based on Deep Reinforcement Learning: A Replication and Extension Study
Feb 26, 2025Cross-site scripting (XSS) poses a significant threat to web application security. While Deep Learning (DL) has shown remarkable success in detecting XSS attacks, it remains vulnerable to adversarial attacks due to the discontinuous nature of its input-output mapping. These adversarial attacks employ mutation-based strategies for different components of XSS attack vectors, allowing adversarial agents to iteratively select mutations to evade detection. Our work replicates a state-of-the-art XSS adversarial attack, highlighting threats to validity in the reference work and extending it toward a more effective evaluation strategy. Moreover, we introduce an XSS Oracle to mitigate these threats. The experimental results show that our approach achieves an escape rate above 96% when the threats to validity of the replicated technique are addressed.
When Uncertainty Leads to Unsafety: Empirical Insights into the Role of Uncertainty in Unmanned Aerial Vehicle Safety
Jan 15, 2025



Despite the recent developments in obstacle avoidance and other safety features, autonomous Unmanned Aerial Vehicles (UAVs) continue to face safety challenges. No previous work investigated the relationship between the behavioral uncertainty of a UAV and the unsafety of its flight. By quantifying uncertainty, it is possible to develop a predictor for unsafety, which acts as a flight supervisor. We conducted a large-scale empirical investigation of safety violations using PX4-Autopilot, an open-source UAV software platform. Our dataset of over 5,000 simulated flights, created to challenge obstacle avoidance, allowed us to explore the relation between uncertain UAV decisions and safety violations: up to 89% of unsafe UAV states exhibit significant decision uncertainty, and up to 74% of uncertain decisions lead to unsafe states. Based on these findings, we implemented Superialist (Supervising Autonomous Aerial Vehicles), a runtime uncertainty detector based on autoencoders, the state-of-the-art technology for anomaly detection. Superialist achieved high performance in detecting uncertain behaviors with up to 96% precision and 93% recall. Despite the observed performance degradation when using the same approach for predicting unsafety (up to 74% precision and 87% recall), Superialist enabled early prediction of unsafe states up to 50 seconds in advance.
Real Faults in Deep Learning Fault Benchmarks: How Real Are They?
Dec 20, 2024



As the adoption of Deep Learning (DL) systems continues to rise, an increasing number of approaches are being proposed to test these systems, localise faults within them, and repair those faults. The best attestation of effectiveness for such techniques is an evaluation that showcases their capability to detect, localise and fix real faults. To facilitate these evaluations, the research community has collected multiple benchmarks of real faults in DL systems. In this work, we perform a manual analysis of 490 faults from five different benchmarks and identify that 314 of them are eligible for our study. Our investigation focuses specifically on how well the bugs correspond to the sources they were extracted from, which fault types are represented, and whether the bugs are reproducible. Our findings indicate that only 18.5% of the faults satisfy our realism conditions. Our attempts to reproduce these faults were successful only in 52% of cases.
An Empirical Study of Fault Localisation Techniques for Deep Learning
Dec 17, 2024With the increased popularity of Deep Neural Networks (DNNs), increases also the need for tools to assist developers in the DNN implementation, testing and debugging process. Several approaches have been proposed that automatically analyse and localise potential faults in DNNs under test. In this work, we evaluate and compare existing state-of-the-art fault localisation techniques, which operate based on both dynamic and static analysis of the DNN. The evaluation is performed on a benchmark consisting of both real faults obtained from bug reporting platforms and faulty models produced by a mutation tool. Our findings indicate that the usage of a single, specific ground truth (e.g., the human defined one) for the evaluation of DNN fault localisation tools results in pretty low performance (maximum average recall of 0.31 and precision of 0.23). However, such figures increase when considering alternative, equivalent patches that exist for a given faulty DNN. Results indicate that \dfd is the most effective tool, achieving an average recall of 0.61 and precision of 0.41 on our benchmark.
Predicting Safety Misbehaviours in Autonomous Driving Systems using Uncertainty Quantification
Apr 29, 2024
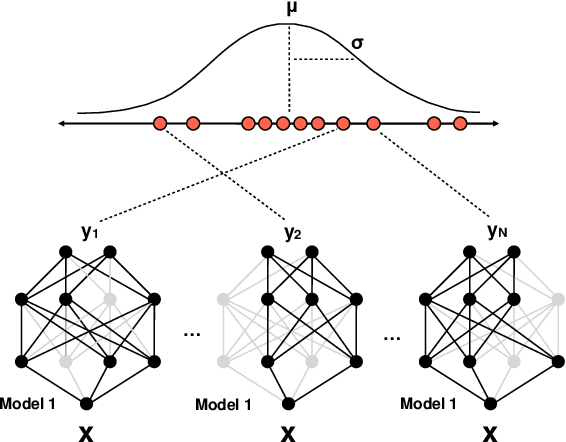
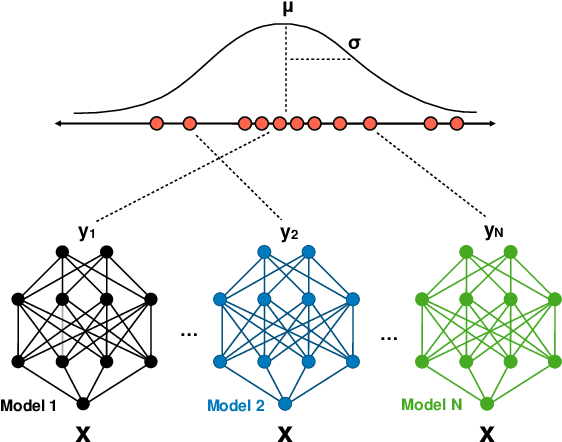
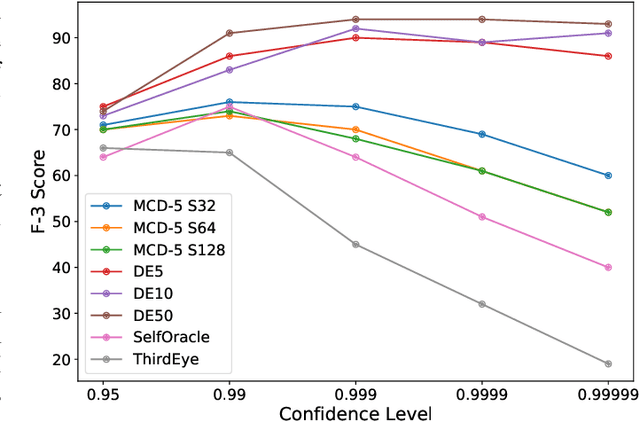
The automated real-time recognition of unexpected situations plays a crucial role in the safety of autonomous vehicles, especially in unsupported and unpredictable scenarios. This paper evaluates different Bayesian uncertainty quantification methods from the deep learning domain for the anticipatory testing of safety-critical misbehaviours during system-level simulation-based testing. Specifically, we compute uncertainty scores as the vehicle executes, following the intuition that high uncertainty scores are indicative of unsupported runtime conditions that can be used to distinguish safe from failure-inducing driving behaviors. In our study, we conducted an evaluation of the effectiveness and computational overhead associated with two Bayesian uncertainty quantification methods, namely MC- Dropout and Deep Ensembles, for misbehaviour avoidance. Overall, for three benchmarks from the Udacity simulator comprising both out-of-distribution and unsafe conditions introduced via mutation testing, both methods successfully detected a high number of out-of-bounds episodes providing early warnings several seconds in advance, outperforming two state-of-the-art misbehaviour prediction methods based on autoencoders and attention maps in terms of effectiveness and efficiency. Notably, Deep Ensembles detected most misbehaviours without any false alarms and did so even when employing a relatively small number of models, making them computationally feasible for real-time detection. Our findings suggest that incorporating uncertainty quantification methods is a viable approach for building fail-safe mechanisms in deep neural network-based autonomous vehicles.
Reinforcement Learning for Online Testing of Autonomous Driving Systems: a Replication and Extension Study
Mar 20, 2024In a recent study, Reinforcement Learning (RL) used in combination with many-objective search, has been shown to outperform alternative techniques (random search and many-objective search) for online testing of Deep Neural Network-enabled systems. The empirical evaluation of these techniques was conducted on a state-of-the-art Autonomous Driving System (ADS). This work is a replication and extension of that empirical study. Our replication shows that RL does not outperform pure random test generation in a comparison conducted under the same settings of the original study, but with no confounding factor coming from the way collisions are measured. Our extension aims at eliminating some of the possible reasons for the poor performance of RL observed in our replication: (1) the presence of reward components providing contrasting or useless feedback to the RL agent; (2) the usage of an RL algorithm (Q-learning) which requires discretization of an intrinsically continuous state space. Results show that our new RL agent is able to converge to an effective policy that outperforms random testing. Results also highlight other possible improvements, which open to further investigations on how to best leverage RL for online ADS testing.
Boundary State Generation for Testing and Improvement of Autonomous Driving Systems
Jul 20, 2023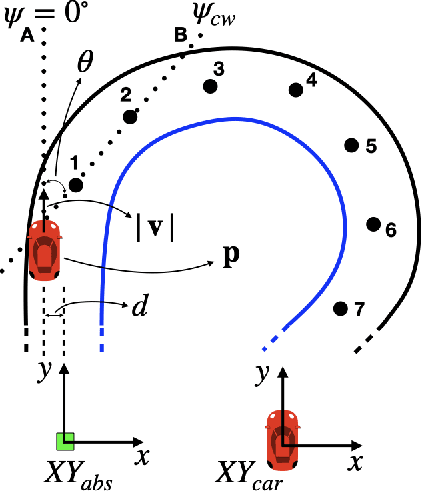
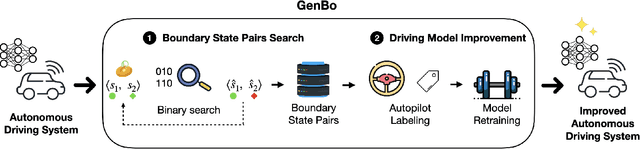
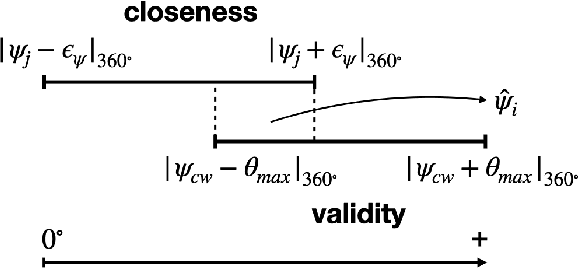
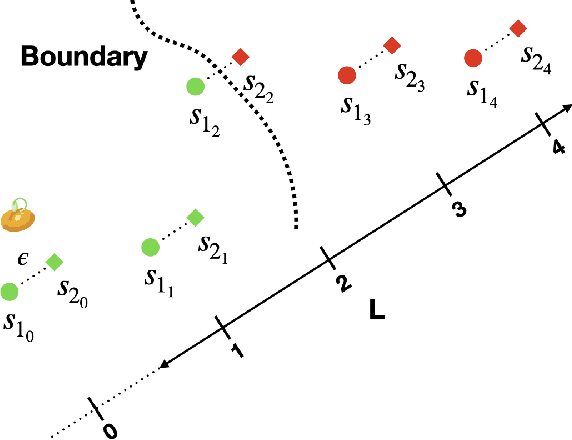
Recent advances in Deep Neural Networks (DNNs) and sensor technologies are enabling autonomous driving systems (ADSs) with an ever-increasing level of autonomy. However, assessing their dependability remains a critical concern. State-of-the-art ADS testing approaches modify the controllable attributes of a simulated driving environment until the ADS misbehaves. Such approaches have two main drawbacks: (1) modifications to the simulated environment might not be easily transferable to the in-field test setting (e.g., changing the road shape); (2) environment instances in which the ADS is successful are discarded, despite the possibility that they could contain hidden driving conditions in which the ADS may misbehave. In this paper, we present GenBo (GENerator of BOundary state pairs), a novel test generator for ADS testing. GenBo mutates the driving conditions of the ego vehicle (position, velocity and orientation), collected in a failure-free environment instance, and efficiently generates challenging driving conditions at the behavior boundary (i.e., where the model starts to misbehave) in the same environment. We use such boundary conditions to augment the initial training dataset and retrain the DNN model under test. Our evaluation results show that the retrained model has up to 16 higher success rate on a separate set of evaluation tracks with respect to the original DNN model.
Testing of Deep Reinforcement Learning Agents with Surrogate Models
May 22, 2023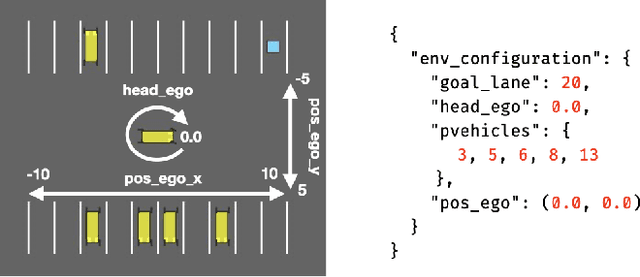
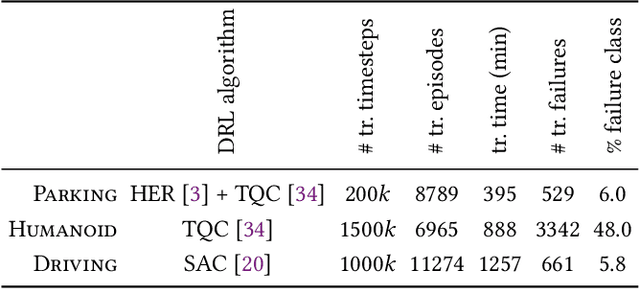
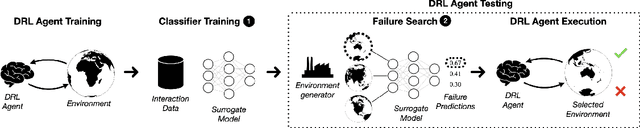
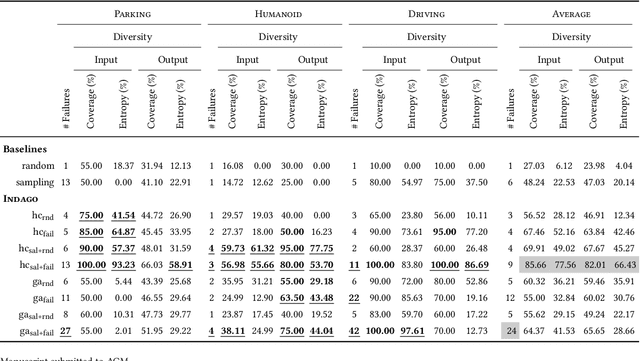
Deep Reinforcement Learning (DRL) has received a lot of attention from the research community in recent years. As the technology moves away from game playing to practical contexts, such as autonomous vehicles and robotics, it is crucial to evaluate the quality of DRL agents. In this paper, we propose a search-based approach to test such agents. Our approach, implemented in a tool called Indago, trains a classifier on failure and non-failure environment configurations resulting from the DRL training process. The classifier is used at testing time as a surrogate model for the DRL agent execution in the environment, predicting the extent to which a given environment configuration induces a failure of the DRL agent under test. Indeed, the failure prediction acts as a fitness function, in order to guide the generation towards failure environment configurations, while saving computation time by deferring the execution of the DRL agent in the environment to those configurations that are more likely to expose failures. Experimental results show that our search-based approach finds 50% more failures of the DRL agent than state-of-the-art techniques. Moreover, such failure environment configurations, as well as the behaviours of the DRL agent induced by them, are significantly more diverse.