 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Reasoning in Software Quality Assurance: A Systematic Review
Aug 30, 2024
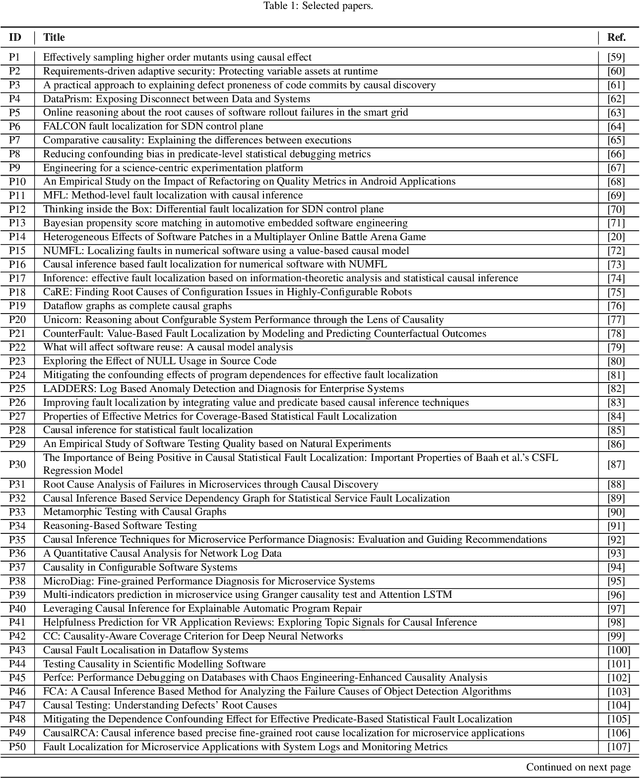
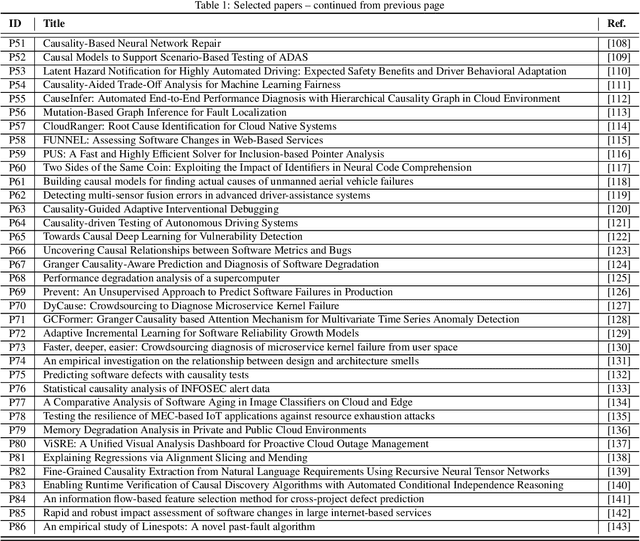
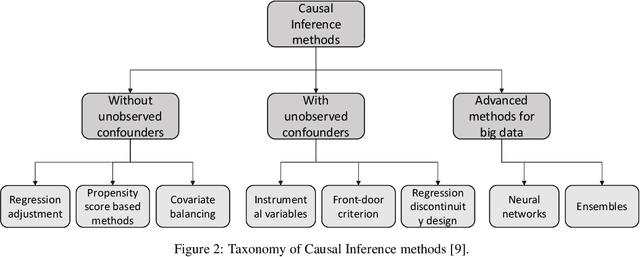
Context: Software Quality Assurance (SQA) is a fundamental part of software engineering to ensure stakeholders that software products work as expected after release in operation. Machine Learning (ML) has proven to be able to boost SQA activities and contribute to the development of quality software systems. In this context, Causal Reasoning is gaining increasing interest as a methodology to solve some of the current ML limitations. It aims to go beyond a purely data-driven approach by exploiting the use of causality for more effective SQA strategies. Objective: Provide a broad and detailed overview of the use of causal reasoning for SQA activities, in order to support researchers to access this research field, identifying room for application, main challenges and research opportunities. Methods: A systematic literature review of causal reasoning in the SQA research area. Scientific papers have been searched, classified, and analyzed according to established guidelines for software engineering secondary studies. Results: Results highlight the primary areas within SQA where causal reasoning has been applied, the predominant methodologies used, and the level of maturity of the proposed solutions. Fault localization is the activity where causal reasoning is more exploited, especially in the web services/microservices domain, but other tasks like testing are rapidly gaining popularity. Both causal inference and causal discovery are exploited, with the Pearl's graphical formulation of causality being preferred, likely due to its intuitiveness. Tools to favour their application are appearing at a fast pace - most of them after 2021. Conclusions: The findings show that causal reasoning is a valuable means for SQA tasks with respect to multiple quality attributes, especially during V&V, evolution and maintenance to ensure reliability, while it is not yet fully exploited for phases like ...
DeepSample: DNN sampling-based testing for operational accuracy assessment
Mar 28, 2024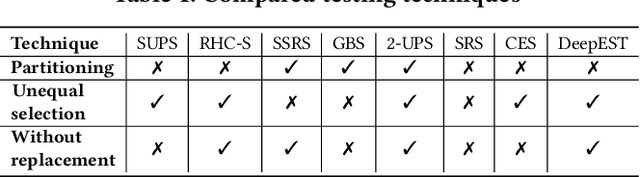
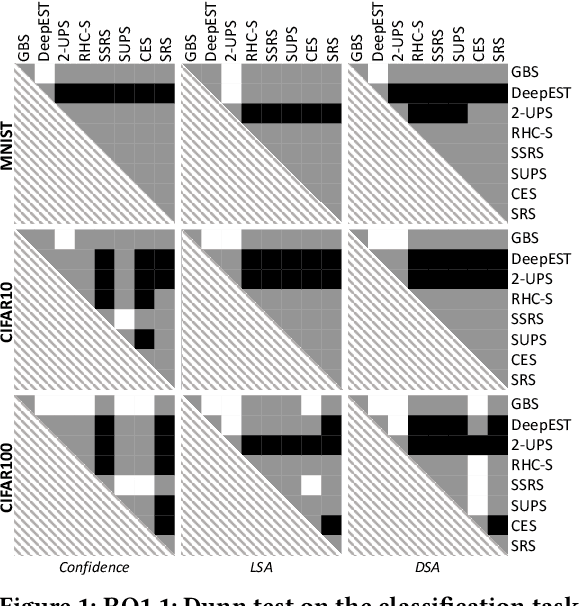
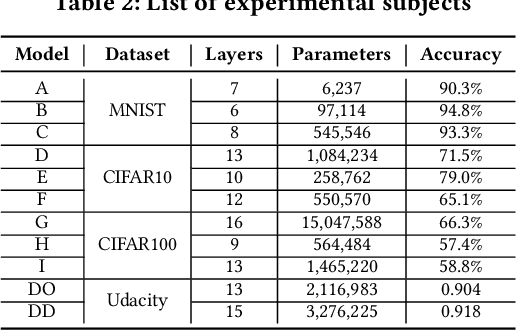
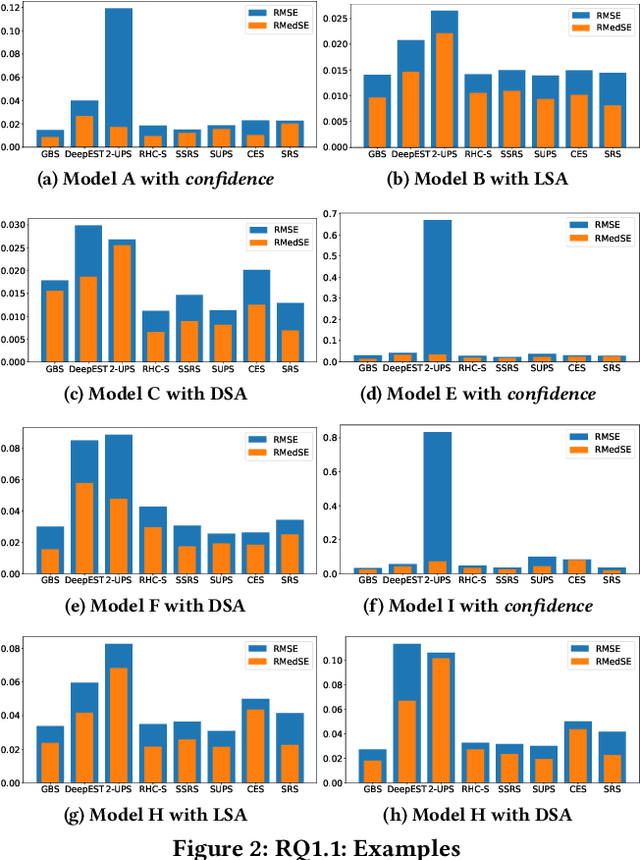
Deep Neural Networks (DNN) are core components for classification and regression tasks of many software systems. Companies incur in high costs for testing DNN with datasets representative of the inputs expected in operation, as these need to be manually labelled. The challenge is to select a representative set of test inputs as small as possible to reduce the labelling cost, while sufficing to yield unbiased high-confidence estimates of the expected DNN accuracy. At the same time, testers are interested in exposing as many DNN mispredictions as possible to improve the DNN, ending up in the need for techniques pursuing a threefold aim: small dataset size, trustworthy estimates, mispredictions exposure. This study presents DeepSample, a family of DNN testing techniques for cost-effective accuracy assessment based on probabilistic sampling. We investigate whether, to what extent, and under which conditions probabilistic sampling can help to tackle the outlined challenge. We implement five new sampling-based testing techniques, and perform a comprehensive comparison of such techniques and of three further state-of-the-art techniques for both DNN classification and regression tasks. Results serve as guidance for best use of sampling-based testing for faithful and high-confidence estimates of DNN accuracy in operation at low cost.
Reinforcement Learning for Online Testing of Autonomous Driving Systems: a Replication and Extension Study
Mar 20, 2024In a recent study, Reinforcement Learning (RL) used in combination with many-objective search, has been shown to outperform alternative techniques (random search and many-objective search) for online testing of Deep Neural Network-enabled systems. The empirical evaluation of these techniques was conducted on a state-of-the-art Autonomous Driving System (ADS). This work is a replication and extension of that empirical study. Our replication shows that RL does not outperform pure random test generation in a comparison conducted under the same settings of the original study, but with no confounding factor coming from the way collisions are measured. Our extension aims at eliminating some of the possible reasons for the poor performance of RL observed in our replication: (1) the presence of reward components providing contrasting or useless feedback to the RL agent; (2) the usage of an RL algorithm (Q-learning) which requires discretization of an intrinsically continuous state space. Results show that our new RL agent is able to converge to an effective policy that outperforms random testing. Results also highlight other possible improvements, which open to further investigations on how to best leverage RL for online ADS testing.
Reasoning-Based Software Testing
Mar 02, 2023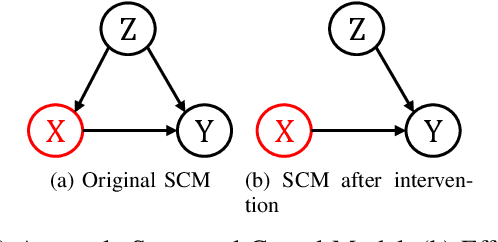
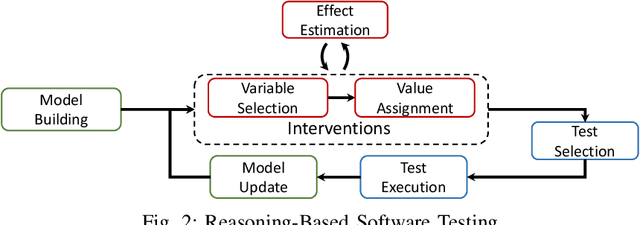
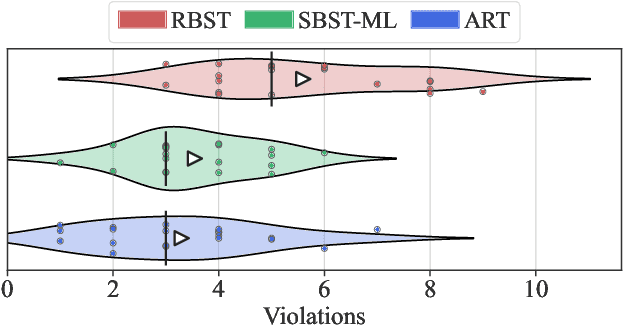
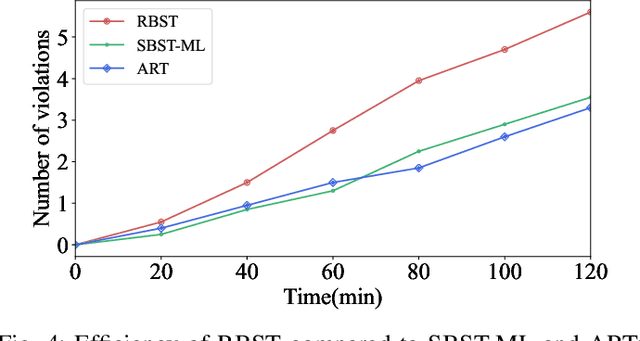
With software systems becoming increasingly pervasive and autonomous, our ability to test for their quality is severely challenged. Many systems are called to operate in uncertain and highly-changing environment, not rarely required to make intelligent decisions by themselves. This easily results in an intractable state space to explore at testing time. The state-of-the-art techniques try to keep the pace, e.g., by augmenting the tester's intuition with some form of (explicit or implicit) learning from observations to search this space efficiently. For instance, they exploit historical data to drive the search (e.g., ML-driven testing) or the tests execution data itself (e.g., adaptive or search-based testing). Despite the indubitable advances, the need for smartening the search in such a huge space keeps to be pressing. We introduce Reasoning-Based Software Testing (RBST), a new way of thinking at the testing problem as a causal reasoning task. Compared to mere intuition-based or state-of-the-art learning-based strategies, we claim that causal reasoning more naturally emulates the process that a human would do to ''smartly" search the space. RBST aims to mimic and amplify, with the power of computation, this ability. The conceptual leap can pave the ground to a new trend of techniques, which can be variously instantiated from the proposed framework, by exploiting the numerous tools for causal discovery and inference. Preliminary results reported in this paper are promising.
Iterative Assessment and Improvement of DNN Operational Accuracy
Mar 02, 2023



Deep Neural Networks (DNN) are nowadays largely adopted in many application domains thanks to their human-like, or even superhuman, performance in specific tasks. However, due to unpredictable/unconsidered operating conditions, unexpected failures show up on field, making the performance of a DNN in operation very different from the one estimated prior to release. In the life cycle of DNN systems, the assessment of accuracy is typically addressed in two ways: offline, via sampling of operational inputs, or online, via pseudo-oracles. The former is considered more expensive due to the need for manual labeling of the sampled inputs. The latter is automatic but less accurate. We believe that emerging iterative industrial-strength life cycle models for Machine Learning systems, like MLOps, offer the possibility to leverage inputs observed in operation not only to provide faithful estimates of a DNN accuracy, but also to improve it through remodeling/retraining actions. We propose DAIC (DNN Assessment and Improvement Cycle), an approach which combines ''low-cost'' online pseudo-oracles and ''high-cost'' offline sampling techniques to estimate and improve the operational accuracy of a DNN in the iterations of its life cycle. Preliminary results show the benefits of combining the two approaches and integrating them in the DNN life cycle.