 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulator Ensembles for Trustworthy Autonomous Driving Testing
Mar 11, 2025Scenario-based testing with driving simulators is extensively used to identify failing conditions of automated driving assistance systems (ADAS) and reduce the amount of in-field road testing. However, existing studies have shown that repeated test execution in the same as well as in distinct simulators can yield different outcomes, which can be attributed to sources of flakiness or different implementations of the physics, among other factors. In this paper, we present MultiSim, a novel approach to multi-simulation ADAS testing based on a search-based testing approach that leverages an ensemble of simulators to identify failure-inducing, simulator-agnostic test scenarios. During the search, each scenario is evaluated jointly on multiple simulators. Scenarios that produce consistent results across simulators are prioritized for further exploration, while those that fail on only a subset of simulators are given less priority, as they may reflect simulator-specific issues rather than generalizable failures. Our case study, which involves testing a deep neural network-based ADAS on different pairs of three widely used simulators, demonstrates that MultiSim outperforms single-simulator testing by achieving on average a higher rate of simulator-agnostic failures by 51%. Compared to a state-of-the-art multi-simulator approach that combines the outcome of independent test generation campaigns obtained in different simulators, MultiSim identifies 54% more simulator-agnostic failing tests while showing a comparable validity rate. An enhancement of MultiSim that leverages surrogate models to predict simulator disagreements and bypass executions does not only increase the average number of valid failures but also improves efficiency in finding the first valid failure.
Benchmarking Generative AI Models for Deep Learning Test Input Generation
Dec 23, 2024



Test Input Generators (TIGs) are crucial to assess the ability of Deep Learning (DL) image classifiers to provide correct predictions for inputs beyond their training and test sets. Recent advancements in Generative AI (GenAI) models have made them a powerful tool for creating and manipulating synthetic images, although these advancements also imply increased complexity and resource demands for training. In this work, we benchmark and combine different GenAI models with TIGs, assessing their effectiveness, efficiency, and quality of the generated test images, in terms of domain validity and label preservation. We conduct an empirical study involving three different GenAI architectures (VAEs, GANs, Diffusion Models), five classification tasks of increasing complexity, and 364 human evaluations. Our results show that simpler architectures, such as VAEs, are sufficient for less complex datasets like MNIST. However, when dealing with feature-rich datasets, such as ImageNet, more sophisticated architectures like Diffusion Models achieve superior performance by generating a higher number of valid, misclassification-inducing inputs.
Reinforcement Learning for Online Testing of Autonomous Driving Systems: a Replication and Extension Study
Mar 20, 2024In a recent study, Reinforcement Learning (RL) used in combination with many-objective search, has been shown to outperform alternative techniques (random search and many-objective search) for online testing of Deep Neural Network-enabled systems. The empirical evaluation of these techniques was conducted on a state-of-the-art Autonomous Driving System (ADS). This work is a replication and extension of that empirical study. Our replication shows that RL does not outperform pure random test generation in a comparison conducted under the same settings of the original study, but with no confounding factor coming from the way collisions are measured. Our extension aims at eliminating some of the possible reasons for the poor performance of RL observed in our replication: (1) the presence of reward components providing contrasting or useless feedback to the RL agent; (2) the usage of an RL algorithm (Q-learning) which requires discretization of an intrinsically continuous state space. Results show that our new RL agent is able to converge to an effective policy that outperforms random testing. Results also highlight other possible improvements, which open to further investigations on how to best leverage RL for online ADS testing.
Boundary State Generation for Testing and Improvement of Autonomous Driving Systems
Jul 20, 2023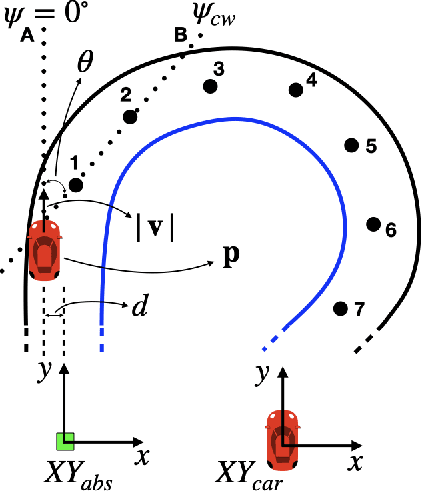
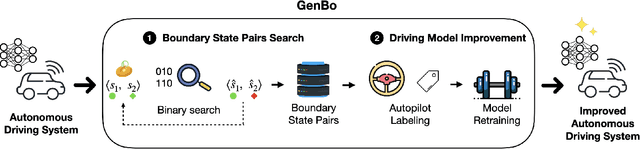
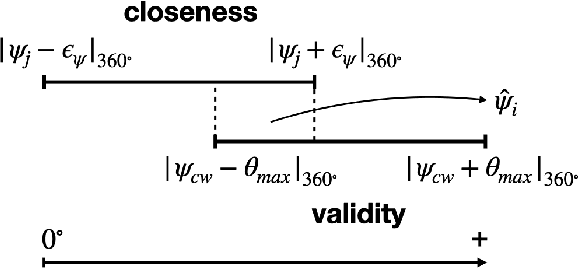
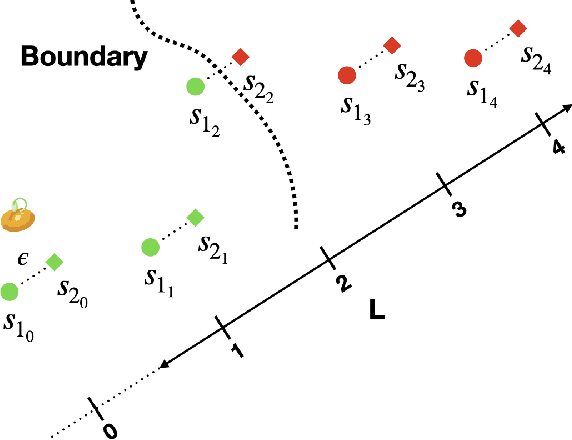
Recent advances in Deep Neural Networks (DNNs) and sensor technologies are enabling autonomous driving systems (ADSs) with an ever-increasing level of autonomy. However, assessing their dependability remains a critical concern. State-of-the-art ADS testing approaches modify the controllable attributes of a simulated driving environment until the ADS misbehaves. Such approaches have two main drawbacks: (1) modifications to the simulated environment might not be easily transferable to the in-field test setting (e.g., changing the road shape); (2) environment instances in which the ADS is successful are discarded, despite the possibility that they could contain hidden driving conditions in which the ADS may misbehave. In this paper, we present GenBo (GENerator of BOundary state pairs), a novel test generator for ADS testing. GenBo mutates the driving conditions of the ego vehicle (position, velocity and orientation), collected in a failure-free environment instance, and efficiently generates challenging driving conditions at the behavior boundary (i.e., where the model starts to misbehave) in the same environment. We use such boundary conditions to augment the initial training dataset and retrain the DNN model under test. Our evaluation results show that the retrained model has up to 16 higher success rate on a separate set of evaluation tracks with respect to the original DNN model.
Testing of Deep Reinforcement Learning Agents with Surrogate Models
May 22, 2023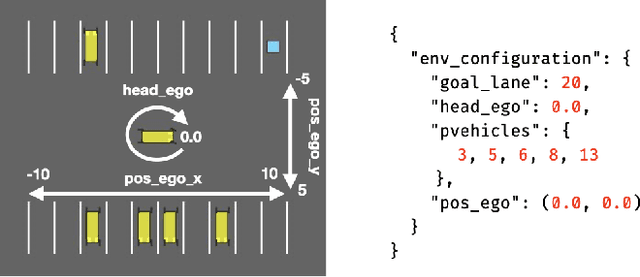
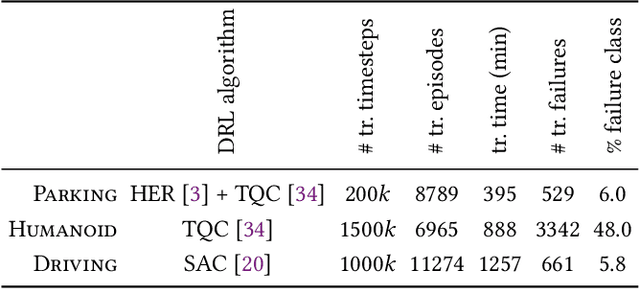
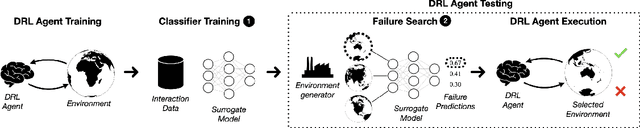
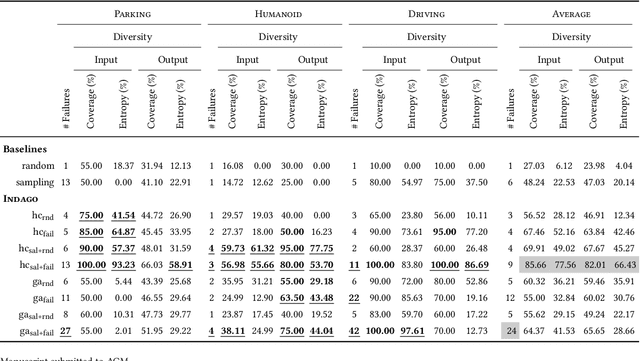
Deep Reinforcement Learning (DRL) has received a lot of attention from the research community in recent years. As the technology moves away from game playing to practical contexts, such as autonomous vehicles and robotics, it is crucial to evaluate the quality of DRL agents. In this paper, we propose a search-based approach to test such agents. Our approach, implemented in a tool called Indago, trains a classifier on failure and non-failure environment configurations resulting from the DRL training process. The classifier is used at testing time as a surrogate model for the DRL agent execution in the environment, predicting the extent to which a given environment configuration induces a failure of the DRL agent under test. Indeed, the failure prediction acts as a fitness function, in order to guide the generation towards failure environment configurations, while saving computation time by deferring the execution of the DRL agent in the environment to those configurations that are more likely to expose failures. Experimental results show that our search-based approach finds 50% more failures of the DRL agent than state-of-the-art techniques. Moreover, such failure environment configurations, as well as the behaviours of the DRL agent induced by them, are significantly more diverse.
Two is Better Than One: Digital Siblings to Improve Autonomous Driving Testing
May 14, 2023Simulation-based testing represents an important step to ensure the reliability of autonomous driving software. In practice, when companies rely on third-party general-purpose simulators, either for in-house or outsourced testing, the generalizability of testing results to real autonomous vehicles is at stake. In this paper, we strengthen simulation-based testing by introducing the notion of digital siblings, a novel framework in which the AV is tested on multiple general-purpose simulators, built with different technologies. First, test cases are automatically generated for each individual simulator. Then, tests are migrated between simulators, using feature maps to characterize of the exercised driving conditions. Finally, the joint predicted failure probability is computed and a failure is reported only in cases of agreement among the siblings. We implemented our framework using two open-source simulators and we empirically compared it against a digital twin of a physical scaled autonomous vehicle on a large set of test cases. Our study shows that the ensemble failure predictor by the digital siblings is superior to each individual simulator at predicting the failures of the digital twin. We discuss several ways in which our framework can help researchers interested in automated testing of autonomous driving software.