 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Reinforcement Learning for Safe Autonomous Driving Under Pedestrian Behavioral Uncertainty
May 18, 2026Simulation-based testing of self-driving cars (SDCs) typically relies on scripted or simplified pedestrian models that do not capture the heterogeneity and uncertainty of real human crossing behavior. This limits the realism of safety assessments, especially in scenarios involving jaywalking, which is governed by latent personality traits that the vehicle cannot observe. We hypothesize that jointly training pedestrians and the SDC with multi-agent reinforcement learning (MARL) produces more realistic interaction scenarios than training the SDC against fixed pedestrian policies, and that the resulting behavior gap between predictable and unpredictable crossings can be measured directly from trajectories. This paper describes a MARL environment in which an SDC and 12 pedestrians are co-trained using Multi-Agent Proximal Policy Optimization (MAPPO). Pedestrian locomotion follows scripted Dijkstra pathfinding, while an RL policy controls high-level go/wait decisions. Jaywalking probability depends on a per-pedestrian personality trait sampled at episode start and hidden from the SDC. In 500-episode evaluations, the co-trained SDC reached 78% of goals with a 14% collision rate, compared to 35% goals and 33% collisions for the best rule-based baseline. A speed differential metric shows that the SDC traveled 2.65 m/s faster near jaywalkers than near crosswalk users at close range (0-3 m), indicating that jaywalking encounters were not anticipated. Jaywalking accounted for 13% of crossing events but was associated with 62% of collisions. Co-training with MARL pedestrians reduced collisions by 30% relative to single-agent RL, as pedestrians learned to wait when the SDC approached at speed.
Bridging Research and Practice in Simulation-based Testing of Industrial Robot Navigation Systems
Oct 10, 2025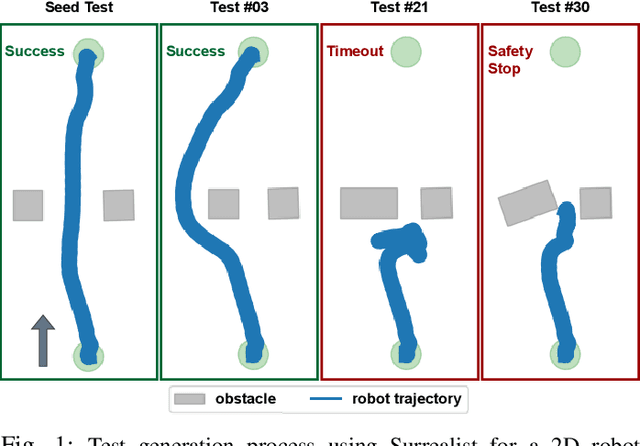
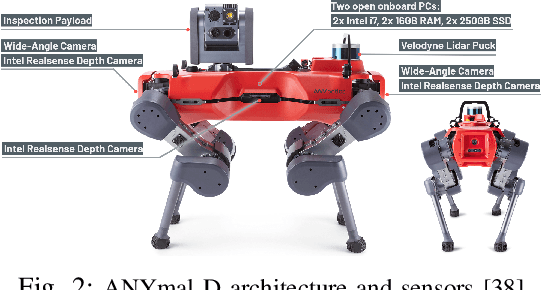
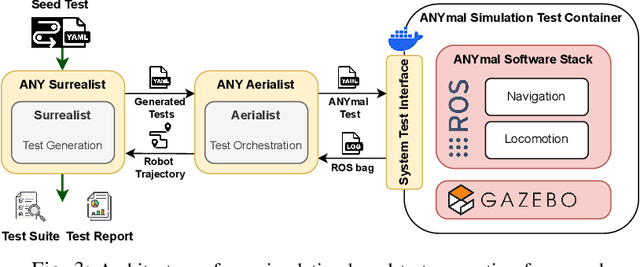
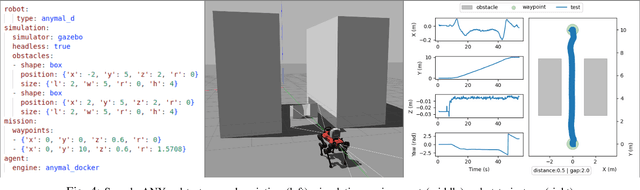
Ensuring robust robotic navigation in dynamic environments is a key challenge, as traditional testing methods often struggle to cover the full spectrum of operational requirements. This paper presents the industrial adoption of Surrealist, a simulation-based test generation framework originally for UAVs, now applied to the ANYmal quadrupedal robot for industrial inspection. Our method uses a search-based algorithm to automatically generate challenging obstacle avoidance scenarios, uncovering failures often missed by manual testing. In a pilot phase, generated test suites revealed critical weaknesses in one experimental algorithm (40.3% success rate) and served as an effective benchmark to prove the superior robustness of another (71.2% success rate). The framework was then integrated into the ANYbotics workflow for a six-month industrial evaluation, where it was used to test five proprietary algorithms. A formal survey confirmed its value, showing it enhances the development process, uncovers critical failures, provides objective benchmarks, and strengthens the overall verification pipeline.
When Uncertainty Leads to Unsafety: Empirical Insights into the Role of Uncertainty in Unmanned Aerial Vehicle Safety
Jan 15, 2025



Despite the recent developments in obstacle avoidance and other safety features, autonomous Unmanned Aerial Vehicles (UAVs) continue to face safety challenges. No previous work investigated the relationship between the behavioral uncertainty of a UAV and the unsafety of its flight. By quantifying uncertainty, it is possible to develop a predictor for unsafety, which acts as a flight supervisor. We conducted a large-scale empirical investigation of safety violations using PX4-Autopilot, an open-source UAV software platform. Our dataset of over 5,000 simulated flights, created to challenge obstacle avoidance, allowed us to explore the relation between uncertain UAV decisions and safety violations: up to 89% of unsafe UAV states exhibit significant decision uncertainty, and up to 74% of uncertain decisions lead to unsafe states. Based on these findings, we implemented Superialist (Supervising Autonomous Aerial Vehicles), a runtime uncertainty detector based on autoencoders, the state-of-the-art technology for anomaly detection. Superialist achieved high performance in detecting uncertain behaviors with up to 96% precision and 93% recall. Despite the observed performance degradation when using the same approach for predicting unsafety (up to 74% precision and 87% recall), Superialist enabled early prediction of unsafe states up to 50 seconds in advance.
Predicting Issue Types on GitHub
Jul 21, 2021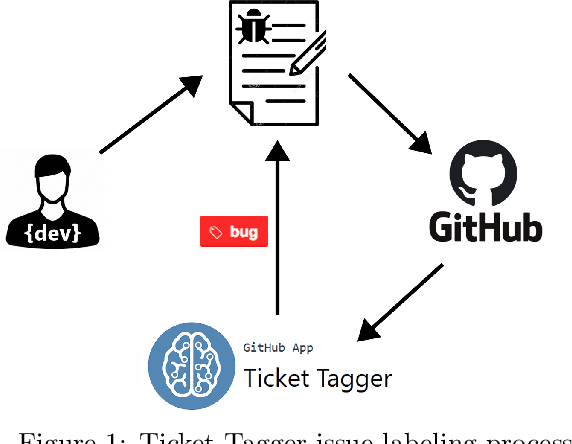

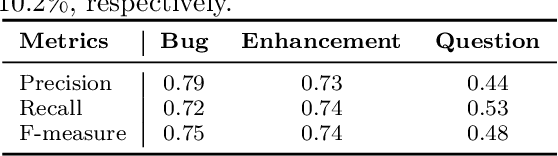
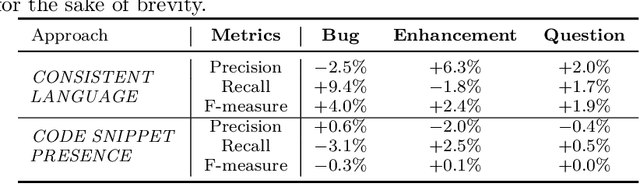
Software maintenance and evolution involves critical activities for the success of software projects. To support such activities and keep code up-to-date and error-free, software communities make use of issue trackers, i.e., tools for signaling, handling, and addressing the issues occurring in software systems. However, in popular projects, tens or hundreds of issue reports are daily submitted. In this context, identifying the type of each submitted report (e.g., bug report, feature request, etc.) would facilitate the management and the prioritization of the issues to address. To support issue handling activities, in this paper, we propose Ticket Tagger, a GitHub app analyzing the issue title and description through machine learning techniques to automatically recognize the types of reports submitted on GitHub and assign labels to each issue accordingly. We empirically evaluated the tool's prediction performance on about 30,000 GitHub issues. Our results show that the Ticket Tagger can identify the correct labels to assign to GitHub issues with reasonably high effectiveness. Considering these results and the fact that the tool is designed to be easily integrated in the GitHub issue management process, Ticket Tagger consists in a useful solution for developers.
Testing with Fewer Resources: An Adaptive Approach to Performance-Aware Test Case Generation
Jul 26, 2019
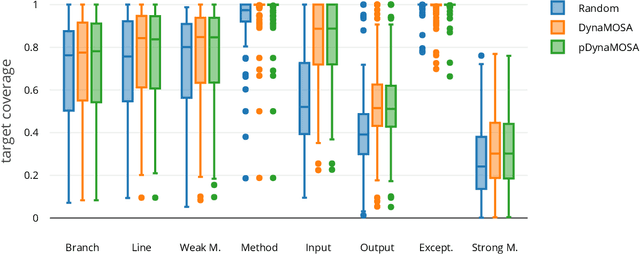
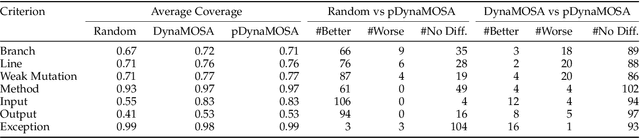
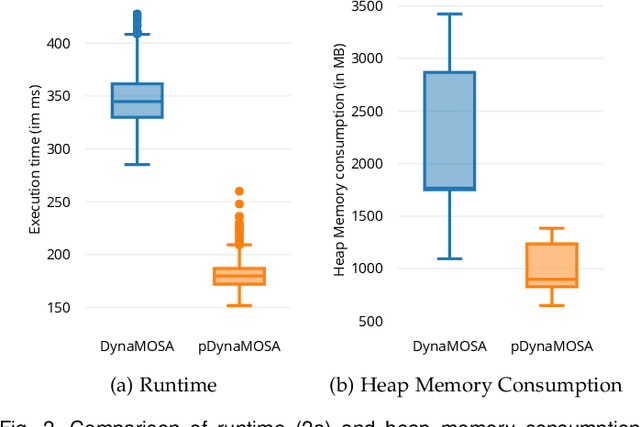
Automated test case generation is an effective technique to yield high-coverage test suites. While the majority of research effort has been devoted to satisfying coverage criteria, a recent trend emerged towards optimizing other non-coverage aspects. In this regard, runtime and memory usage are two essential dimensions: less expensive tests reduce the resource demands for the generation process and for later regression testing phases. This study shows that performance-aware test case generation requires solving two main challenges: providing accurate measurements of resource usage with minimal overhead and avoiding detrimental effects on both final coverage and fault detection effectiveness. To tackle these challenges we conceived a set of performance proxies (inspired by previous work on performance testing) that provide an approximation of the test execution costs (i.e., runtime and memory usage). Thus, we propose an adaptive strategy, called pDynaMOSA, which leverages these proxies by extending DynaMOSA, a state-of-the-art evolutionary algorithm in unit testing. Our empirical study --involving 110 non-trivial Java classes--reveals that our adaptive approach has comparable results to DynaMOSA over seven different coverage criteria (including branch, line, and weak mutation coverage) and similar fault detection effectiveness (measured via strong mutation coverage). Additionally, we observe statistically significant improvements regarding runtime and memory usage for test suites with a similar level of target coverage. Our quantitative and qualitative analyses highlight that our adaptive approach facilitates selecting better test inputs, which is an essential factor to test production code with fewer resources.