 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetamorphic Testing of Deep Code Models: A Systematic Literature Review
Jul 30, 2025Large language models and deep learning models designed for code intelligence have revolutionized the software engineering field due to their ability to perform various code-related tasks. These models can process source code and software artifacts with high accuracy in tasks such as code completion, defect detection, and code summarization; therefore, they can potentially become an integral part of modern software engineering practices. Despite these capabilities, robustness remains a critical quality attribute for deep-code models as they may produce different results under varied and adversarial conditions (e.g., variable renaming). Metamorphic testing has become a widely used approach to evaluate models' robustness by applying semantic-preserving transformations to input programs and analyzing the stability of model outputs. While prior research has explored testing deep learning models, this systematic literature review focuses specifically on metamorphic testing for deep code models. By studying 45 primary papers, we analyze the transformations, techniques, and evaluation methods used to assess robustness. Our review summarizes the current landscape, identifying frequently evaluated models, programming tasks, datasets, target languages, and evaluation metrics, and highlights key challenges and future directions for advancing the field.
Raiders of the Lost Dependency: Fixing Dependency Conflicts in Python using LLMs
Jan 27, 2025



Fixing Python dependency issues is a tedious and error-prone task for developers, who must manually identify and resolve environment dependencies and version constraints of third-party modules and Python interpreters. Researchers have attempted to automate this process by relying on large knowledge graphs and database lookup tables. However, these traditional approaches face limitations due to the variety of dependency error types, large sets of possible module versions, and conflicts among transitive dependencies. This study explores the potential of using large language models (LLMs) to automatically fix dependency issues in Python programs. We introduce PLLM (pronounced "plum"), a novel technique that employs retrieval-augmented generation (RAG) to help an LLM infer Python versions and required modules for a given Python file. PLLM builds a testing environment that iteratively (1) prompts the LLM for module combinations, (2) tests the suggested changes, and (3) provides feedback (error messages) to the LLM to refine the fix. This feedback cycle leverages natural language processing (NLP) to intelligently parse and interpret build error messages. We benchmark PLLM on the Gistable HG2.9K dataset, a collection of challenging single-file Python gists. We compare PLLM against two state-of-the-art automatic dependency inference approaches, namely PyEGo and ReadPyE, w.r.t. the ability to resolve dependency issues. Our results indicate that PLLM can fix more dependency issues than the two baselines, with +218 (+15.97%) more fixes over ReadPyE and +281 (+21.58%) over PyEGo. Our deeper analyses suggest that PLLM is particularly beneficial for projects with many dependencies and for specific third-party numerical and machine-learning modules. Our findings demonstrate the potential of LLM-based approaches to iteratively resolve Python dependency issues.
State Frequency Estimation for Anomaly Detection
Dec 04, 2024



Many works have studied the efficacy of state machines for detecting anomalies within NetFlows. These works typically learn a model from unlabeled data and compute anomaly scores for arbitrary traces based on their likelihood of occurrence or how well they fit within the model. However, these methods do not dynamically adapt their scores based on the traces seen at test time. This becomes a problem when an adversary produces seemingly common traces in their attack, causing the model to miss the detection by assigning low anomaly scores. We propose SEQUENT, a new approach that uses the state visit frequency to adapt its scoring for anomaly detection dynamically. SEQUENT subsequently uses the scores to generate root causes for anomalies. These allow the grouping of alarms and simplify the analysis of anomalies. Our evaluation of SEQUENT on three NetFlow datasets indicates that our approach outperforms existing methods, demonstrating its effectiveness in detecting anomalies.
Automated Test-Case Generation for REST APIs Using Model Inference Search Heuristic
Dec 04, 2024
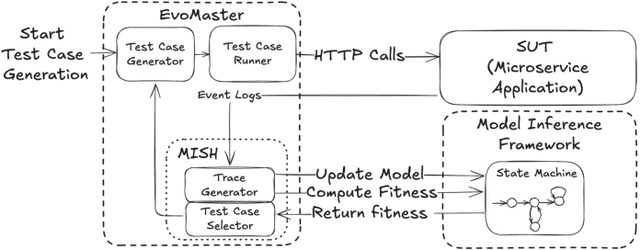
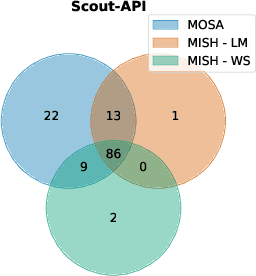
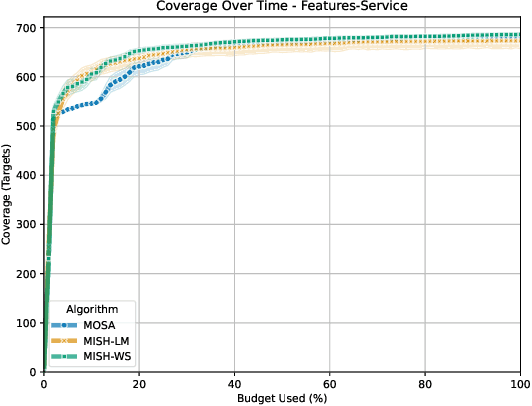
The rising popularity of the microservice architectural style has led to a growing demand for automated testing approaches tailored to these systems. EvoMaster is a state-of-the-art tool that uses Evolutionary Algorithms (EAs) to automatically generate test cases for microservices' REST APIs. One limitation of these EAs is the use of unit-level search heuristics, such as branch distances, which focus on fine-grained code coverage and may not effectively capture the complex, interconnected behaviors characteristic of system-level testing. To address this limitation, we propose a new search heuristic (MISH) that uses real-time automaton learning to guide the test case generation process. We capture the sequential call patterns exhibited by a test case by learning an automaton from the stream of log events outputted by different microservices within the same system. Therefore, MISH learns a representation of the systemwide behavior, allowing us to define the fitness of a test case based on the path it traverses within the inferred automaton. We empirically evaluate MISH's effectiveness on six real-world benchmark microservice applications and compare it against a state-of-the-art technique, MOSA, for testing REST APIs. Our evaluation shows promising results for using MISH to guide the automated test case generation within EvoMaster.
Breaking the Silence: the Threats of Using LLMs in Software Engineering
Dec 13, 2023Large Language Models (LLMs) have gained considerable traction within the Software Engineering (SE) community, impacting various SE tasks from code completion to test generation, from program repair to code summarization. Despite their promise, researchers must still be careful as numerous intricate factors can influence the outcomes of experiments involving LLMs. This paper initiates an open discussion on potential threats to the validity of LLM-based research including issues such as closed-source models, possible data leakage between LLM training data and research evaluation, and the reproducibility of LLM-based findings. In response, this paper proposes a set of guidelines tailored for SE researchers and Language Model (LM) providers to mitigate these concerns. The implications of the guidelines are illustrated using existing good practices followed by LLM providers and a practical example for SE researchers in the context of test case generation.
Encoding NetFlows for State-Machine Learning
Jul 08, 2022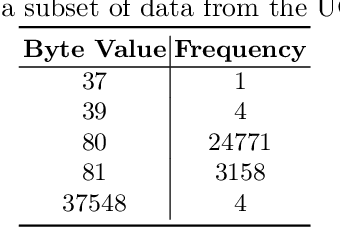
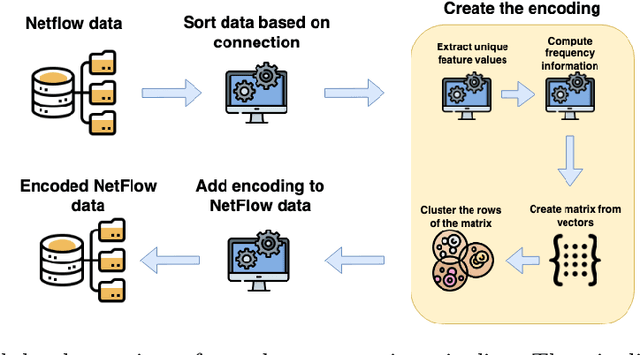
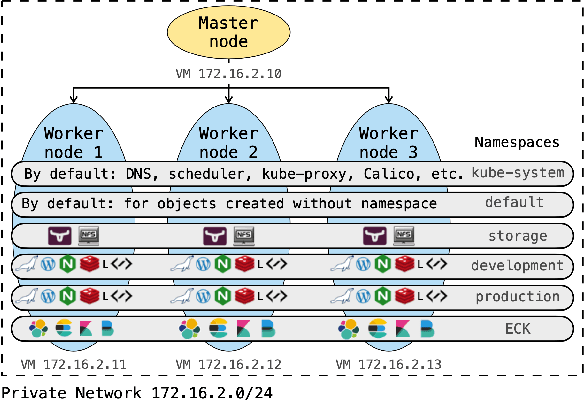
NetFlow data is a well-known network log format used by many network analysts and researchers. The advantages of using this format compared to pcap are that it contains fewer data, is less privacy intrusive, and is easier to collect and process. However, having less data does mean that this format might not be able to capture important network behaviour as all information is summarised into statistics. Much research aims to overcome this disadvantage through the use of machine learning, for instance, to detect attacks within a network. Many approaches can be used to pre-process the NetFlow data before it is used to train the machine learning algorithms. However, many of these approaches simply apply existing methods to the data, not considering the specific properties of network data. We argue that for data originating from software systems, such as NetFlow or software logs, similarities in frequency and contexts of feature values are more important than similarities in the value itself. In this work, we, therefore, propose an encoding algorithm that directly takes the frequency and the context of the feature values into account when the data is being processed. Different types of network behaviours can be clustered using this encoding, thus aiding the process of detecting anomalies within the network. From windows of these clusters obtained from monitoring a clean system, we learn state machine behavioural models for anomaly detection. These models are very well-suited to modelling the cyclic and repetitive patterns present in NetFlow data. We evaluate our encoding on a new dataset that we created for detecting problems in Kubernetes clusters and on two well-known public NetFlow datasets. The obtained performance results of the state machine models are comparable to existing works that use many more features and require both clean and infected data as training input.
Improving Test Case Generation for REST APIs Through Hierarchical Clustering
Sep 14, 2021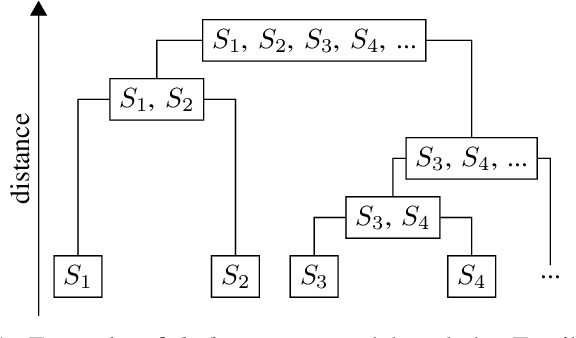
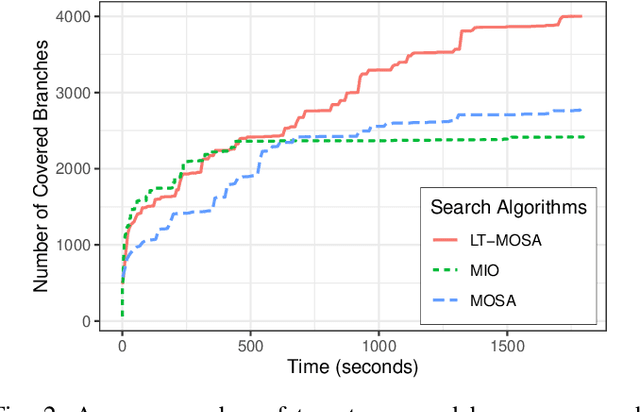
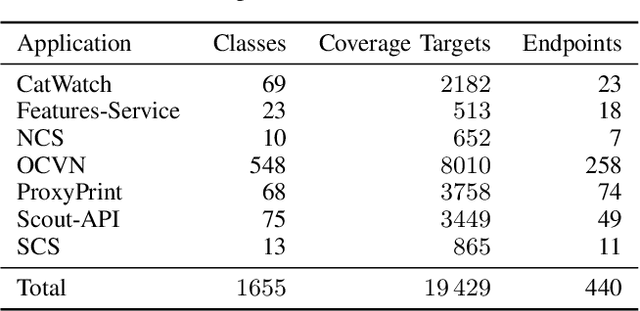
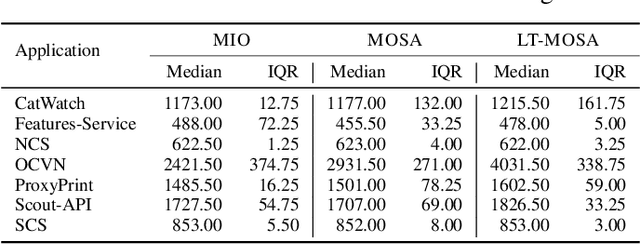
With the ever-increasing use of web APIs in modern-day applications, it is becoming more important to test the system as a whole. In the last decade, tools and approaches have been proposed to automate the creation of system-level test cases for these APIs using evolutionary algorithms (EAs). One of the limiting factors of EAs is that the genetic operators (crossover and mutation) are fully randomized, potentially breaking promising patterns in the sequences of API requests discovered during the search. Breaking these patterns has a negative impact on the effectiveness of the test case generation process. To address this limitation, this paper proposes a new approach that uses agglomerative hierarchical clustering (AHC) to infer a linkage tree model, which captures, replicates, and preserves these patterns in new test cases. We evaluate our approach, called LT-MOSA, by performing an empirical study on 7 real-world benchmark applications w.r.t. branch coverage and real-fault detection capability. We also compare LT-MOSA with the two existing state-of-the-art white-box techniques (MIO, MOSA) for REST API testing. Our results show that LT-MOSA achieves a statistically significant increase in test target coverage (i.e., lines and branches) compared to MIO and MOSA in 4 and 5 out of 7 applications, respectively. Furthermore, LT-MOSA discovers 27 and 18 unique real-faults that are left undetected by MIO and MOSA, respectively.
Multi-objective Test Case Selection Through Linkage Learning-based Crossover
Jul 20, 2021
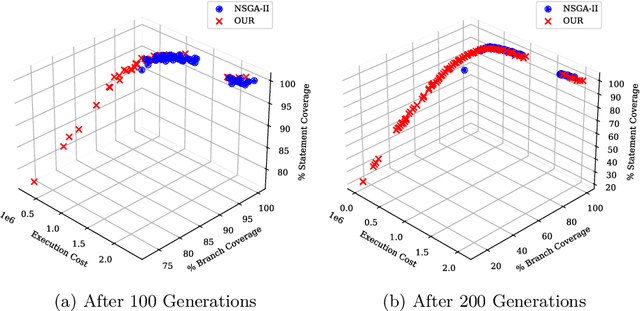
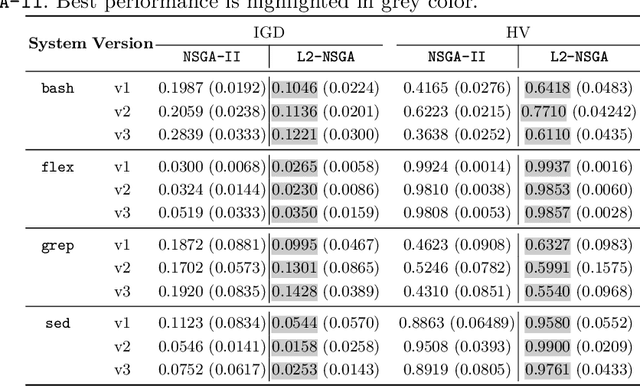
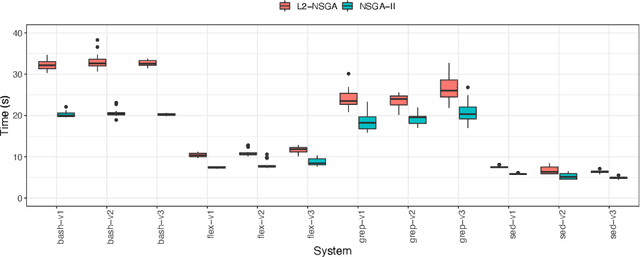
Test Case Selection (TCS) aims to select a subset of the test suite to run for regression testing. The selection is typically based on past coverage and execution cost data. Researchers have successfully used multi-objective evolutionary algorithms (MOEAs), such as NSGA-II and its variants, to solve this problem. These MOEAs use traditional crossover operators to create new candidate solutions through genetic recombination. Recent studies in numerical optimization have shown that better recombinations can be made using machine learning, in particular link-age learning. Inspired by these recent advances in this field, we propose a new variant of NSGA-II, called L2-NSGA, that uses linkage learning to optimize test case selection. In particular, we use an unsupervised clustering algorithm to infer promising patterns among the solutions (subset of test suites). Then, these patterns are used in the next iterations of L2-NSGA to create solutions that preserve these inferred patterns. Our results show that our customizations make NSGA-II more effective for test case selection. The test suite sub-sets generated by L2-NSGA are less expensive and detect more faults than those generated by MOEAs used in the literature for regression testing.
ReproducedPapers.org: Openly teaching and structuring machine learning reproducibility
Dec 01, 2020

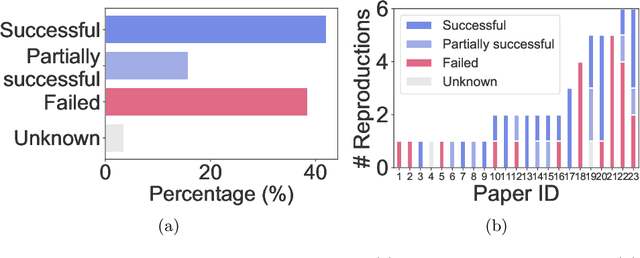
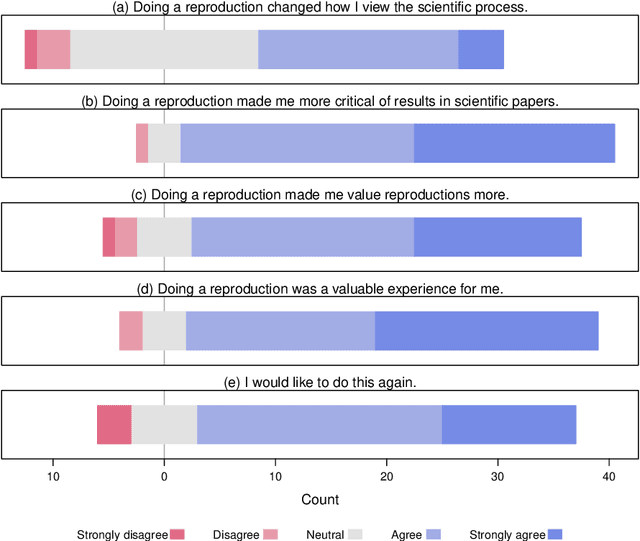
We present ReproducedPapers.org: an open online repository for teaching and structuring machine learning reproducibility. We evaluate doing a reproduction project among students and the added value of an online reproduction repository among AI researchers. We use anonymous self-assessment surveys and obtained 144 responses. Results suggest that students who do a reproduction project place more value on scientific reproductions and become more critical thinkers. Students and AI researchers agree that our online reproduction repository is valuable.
Testing with Fewer Resources: An Adaptive Approach to Performance-Aware Test Case Generation
Jul 26, 2019
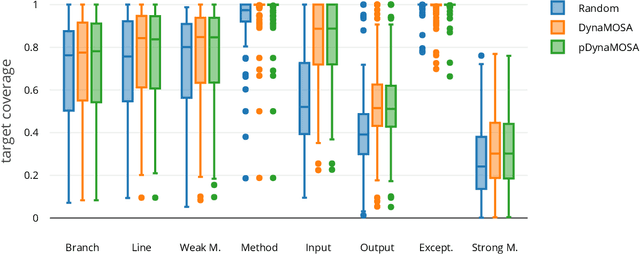
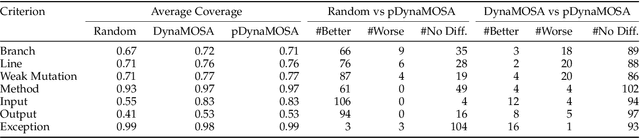
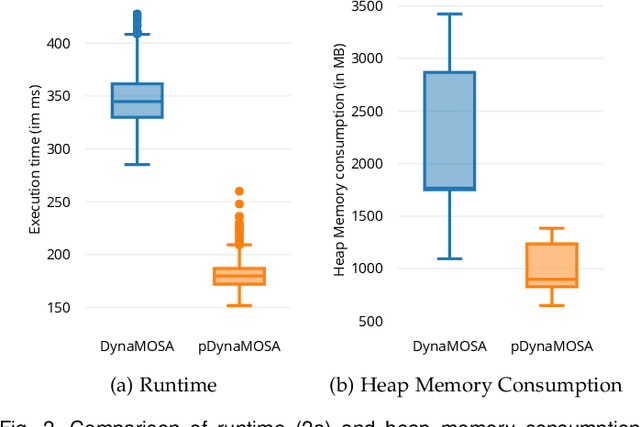
Automated test case generation is an effective technique to yield high-coverage test suites. While the majority of research effort has been devoted to satisfying coverage criteria, a recent trend emerged towards optimizing other non-coverage aspects. In this regard, runtime and memory usage are two essential dimensions: less expensive tests reduce the resource demands for the generation process and for later regression testing phases. This study shows that performance-aware test case generation requires solving two main challenges: providing accurate measurements of resource usage with minimal overhead and avoiding detrimental effects on both final coverage and fault detection effectiveness. To tackle these challenges we conceived a set of performance proxies (inspired by previous work on performance testing) that provide an approximation of the test execution costs (i.e., runtime and memory usage). Thus, we propose an adaptive strategy, called pDynaMOSA, which leverages these proxies by extending DynaMOSA, a state-of-the-art evolutionary algorithm in unit testing. Our empirical study --involving 110 non-trivial Java classes--reveals that our adaptive approach has comparable results to DynaMOSA over seven different coverage criteria (including branch, line, and weak mutation coverage) and similar fault detection effectiveness (measured via strong mutation coverage). Additionally, we observe statistically significant improvements regarding runtime and memory usage for test suites with a similar level of target coverage. Our quantitative and qualitative analyses highlight that our adaptive approach facilitates selecting better test inputs, which is an essential factor to test production code with fewer resources.