 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Test-Case Generation for REST APIs Using Model Inference Search Heuristic
Dec 04, 2024
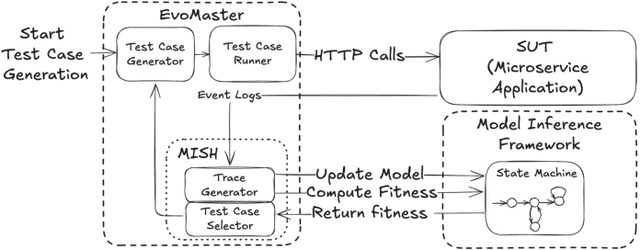
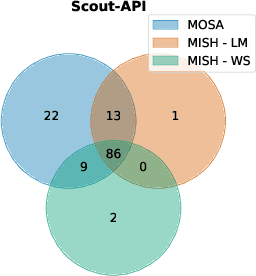
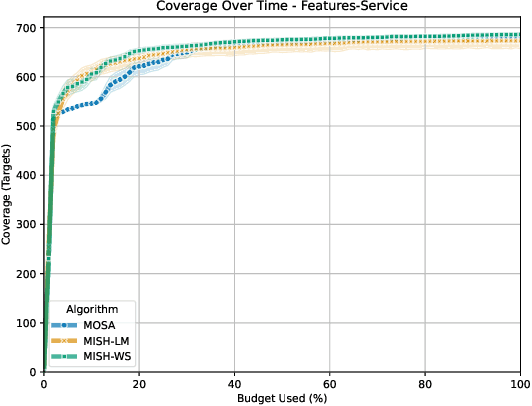
The rising popularity of the microservice architectural style has led to a growing demand for automated testing approaches tailored to these systems. EvoMaster is a state-of-the-art tool that uses Evolutionary Algorithms (EAs) to automatically generate test cases for microservices' REST APIs. One limitation of these EAs is the use of unit-level search heuristics, such as branch distances, which focus on fine-grained code coverage and may not effectively capture the complex, interconnected behaviors characteristic of system-level testing. To address this limitation, we propose a new search heuristic (MISH) that uses real-time automaton learning to guide the test case generation process. We capture the sequential call patterns exhibited by a test case by learning an automaton from the stream of log events outputted by different microservices within the same system. Therefore, MISH learns a representation of the systemwide behavior, allowing us to define the fitness of a test case based on the path it traverses within the inferred automaton. We empirically evaluate MISH's effectiveness on six real-world benchmark microservice applications and compare it against a state-of-the-art technique, MOSA, for testing REST APIs. Our evaluation shows promising results for using MISH to guide the automated test case generation within EvoMaster.
State Frequency Estimation for Anomaly Detection
Dec 04, 2024



Many works have studied the efficacy of state machines for detecting anomalies within NetFlows. These works typically learn a model from unlabeled data and compute anomaly scores for arbitrary traces based on their likelihood of occurrence or how well they fit within the model. However, these methods do not dynamically adapt their scores based on the traces seen at test time. This becomes a problem when an adversary produces seemingly common traces in their attack, causing the model to miss the detection by assigning low anomaly scores. We propose SEQUENT, a new approach that uses the state visit frequency to adapt its scoring for anomaly detection dynamically. SEQUENT subsequently uses the scores to generate root causes for anomalies. These allow the grouping of alarms and simplify the analysis of anomalies. Our evaluation of SEQUENT on three NetFlow datasets indicates that our approach outperforms existing methods, demonstrating its effectiveness in detecting anomalies.
SoK: Explainable Machine Learning for Computer Security Applications
Aug 22, 2022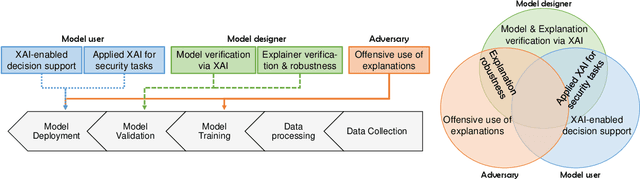

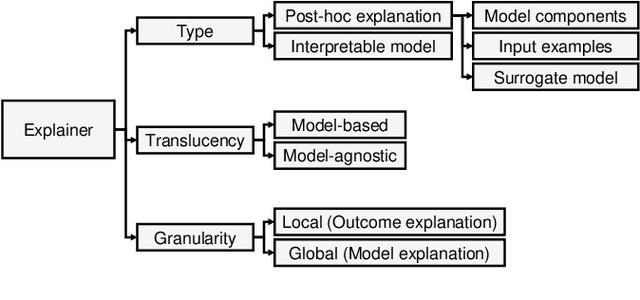
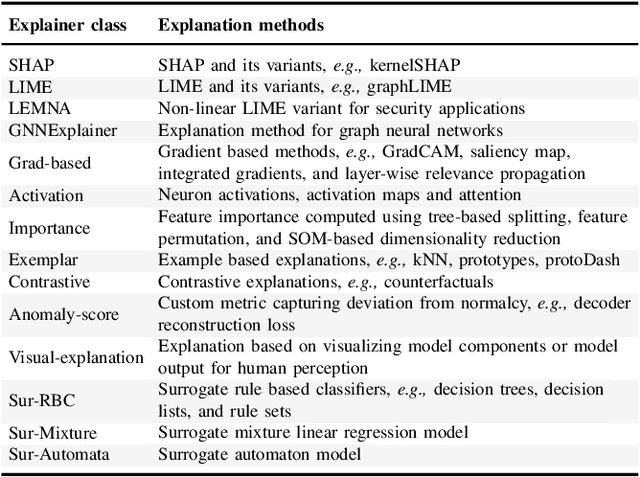
Explainable Artificial Intelligence (XAI) is a promising solution to improve the transparency of machine learning (ML) pipelines. We systematize the increasingly growing (but fragmented) microcosm of studies that develop and utilize XAI methods for defensive and offensive cybersecurity tasks. We identify 3 cybersecurity stakeholders, i.e., model users, designers, and adversaries, that utilize XAI for 5 different objectives within an ML pipeline, namely 1) XAI-enabled decision support, 2) applied XAI for security tasks, 3) model verification via XAI, 4) explanation verification & robustness, and 5) offensive use of explanations. We further classify the literature w.r.t. the targeted security domain. Our analysis of the literature indicates that many of the XAI applications are designed with little understanding of how they might be integrated into analyst workflows -- user studies for explanation evaluation are conducted in only 14% of the cases. The literature also rarely disentangles the role of the various stakeholders. Particularly, the role of the model designer is minimized within the security literature. To this end, we present an illustrative use case accentuating the role of model designers. We demonstrate cases where XAI can help in model verification and cases where it may lead to erroneous conclusions instead. The systematization and use case enable us to challenge several assumptions and present open problems that can help shape the future of XAI within cybersecurity
Encoding NetFlows for State-Machine Learning
Jul 08, 2022
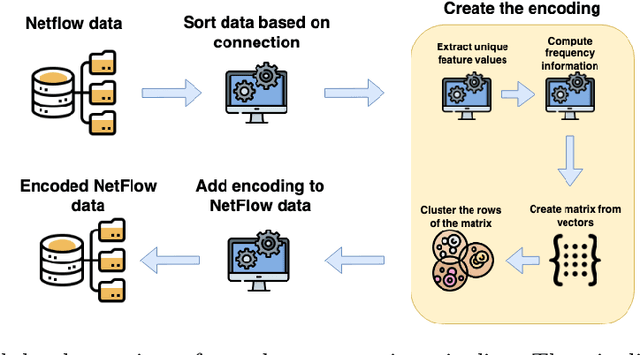
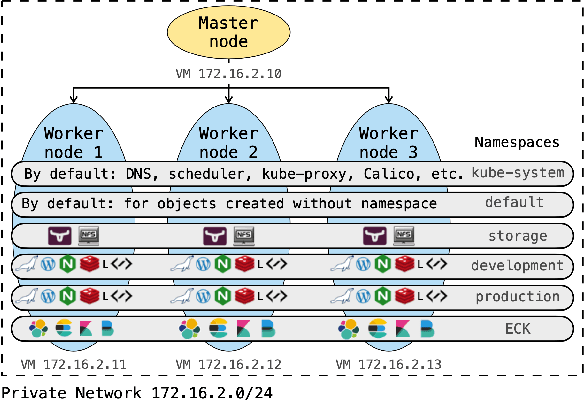
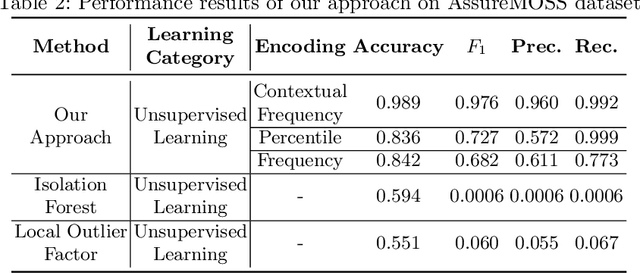
NetFlow data is a well-known network log format used by many network analysts and researchers. The advantages of using this format compared to pcap are that it contains fewer data, is less privacy intrusive, and is easier to collect and process. However, having less data does mean that this format might not be able to capture important network behaviour as all information is summarised into statistics. Much research aims to overcome this disadvantage through the use of machine learning, for instance, to detect attacks within a network. Many approaches can be used to pre-process the NetFlow data before it is used to train the machine learning algorithms. However, many of these approaches simply apply existing methods to the data, not considering the specific properties of network data. We argue that for data originating from software systems, such as NetFlow or software logs, similarities in frequency and contexts of feature values are more important than similarities in the value itself. In this work, we, therefore, propose an encoding algorithm that directly takes the frequency and the context of the feature values into account when the data is being processed. Different types of network behaviours can be clustered using this encoding, thus aiding the process of detecting anomalies within the network. From windows of these clusters obtained from monitoring a clean system, we learn state machine behavioural models for anomaly detection. These models are very well-suited to modelling the cyclic and repetitive patterns present in NetFlow data. We evaluate our encoding on a new dataset that we created for detecting problems in Kubernetes clusters and on two well-known public NetFlow datasets. The obtained performance results of the state machine models are comparable to existing works that use many more features and require both clean and infected data as training input.