 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge(PAC-)Learning state machines from data streams: A generic strategy and an improved heuristic (Extended version)
Apr 02, 2026This is an extended version of our publication Learning state machines from data streams: A generic strategy and an improved heuristic, International Conference on Grammatical Inference (ICGI) 2023, Rabat, Morocco. It has been extended with a formal proof on PAC-bounds, and the discussion and analysis of a similar approach has been moved from the appendix and is now a full Section. State machines models are models that simulate the behavior of discrete event systems, capable of representing systems such as software systems, network interactions, and control systems, and have been researched extensively. The nature of most learning algorithms however is the assumption that all data be available at the beginning of the algorithm, and little research has been done in learning state machines from streaming data. In this paper, we want to close this gap further by presenting a generic method for learning state machines from data streams, as well as a merge heuristic that uses sketches to account for incomplete prefix trees. We implement our approach in an open-source state merging library and compare it with existing methods. We show the effectiveness of our approach with respect to run-time, memory consumption, and quality of results on a well known open dataset. Additionally, we provide a formal analysis of our algorithm, showing that it is capable of learning within the PAC framework, and show a theoretical improvement to increase run-time, without sacrificing correctness of the algorithm in larger sample sizes.
Enhancing spatial hearing with cochlear implants: exploring the role of AI, multimodal interaction and perceptual training
Feb 14, 2026Cochlear implants (CIs) have been developed to the point where they can restore hearing and speech understanding in a large proportion of patients. Although spatial hearing is central to controlling and directing attention and to enabling speech understanding in noisy environments, it has been largely neglected in the past. We propose here a multi-disciplinary research framework in which physicians, psychologists and engineers collaborate to improve spatial hearing for CI users.
Short-term cognitive fatigue of spatial selective attention after face-to-face conversations in virtual noisy environments
Sep 11, 2025Spatial selective attention is an important asset for communication in cocktail party situations but may be compromised by short-term cognitive fatigue. Here we tested whether an effortful conversation in a highly ecological setting depletes task performance in an auditory spatial selective attention task. Young participants with normal hearing performed the task before and after (1) having a real dyadic face-to-face conversation on a free topic in a virtual reverberant room with simulated interfering conversations and background babble noise at 72 dB SPL for 30 minutes, (2) passively listening to the interfering conversations and babble noise, or (3) having the conversation in quiet. Self-reported perceived effort and fatigue increased after conversations in noise and passive listening relative to the reports after conversations in quiet. In contrast to our expectations, response times in the attention task decreased, rather than increased, after conversation in noise and accuracy did not change systematically in any of the conditions on the group level. Unexpectedly, we observed strong training effects between the individual sessions in our within-subject design even after one hour of training on a different day.
PDFA Distillation via String Probability Queries {PDFA Distillation via String Probability Queries}
Jun 26, 2024


Probabilistic deterministic finite automata (PDFA) are discrete event systems modeling conditional probabilities over languages: Given an already seen sequence of tokens they return the probability of tokens of interest to appear next. These types of models have gained interest in the domain of explainable machine learning, where they are used as surrogate models for neural networks trained as language models. In this work we present an algorithm to distill PDFA from neural networks. Our algorithm is a derivative of the L# algorithm and capable of learning PDFA from a new type of query, in which the algorithm infers conditional probabilities from the probability of the queried string to occur. We show its effectiveness on a recent public dataset by distilling PDFA from a set of trained neural networks.
SoK: Explainable Machine Learning for Computer Security Applications
Aug 22, 2022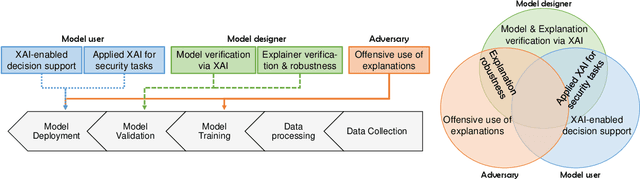

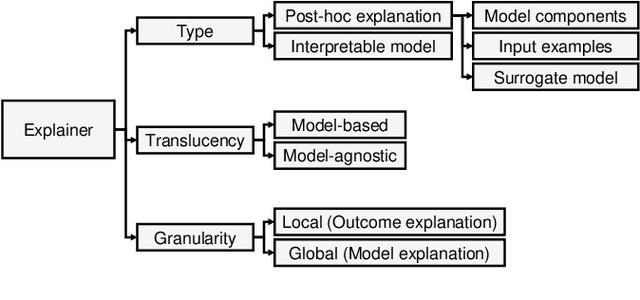
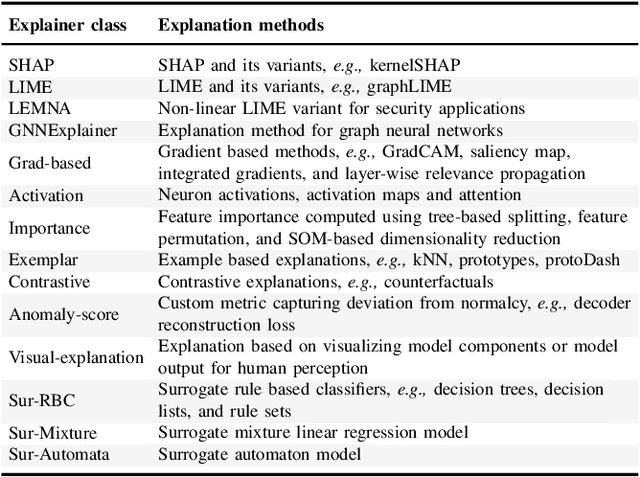
Explainable Artificial Intelligence (XAI) is a promising solution to improve the transparency of machine learning (ML) pipelines. We systematize the increasingly growing (but fragmented) microcosm of studies that develop and utilize XAI methods for defensive and offensive cybersecurity tasks. We identify 3 cybersecurity stakeholders, i.e., model users, designers, and adversaries, that utilize XAI for 5 different objectives within an ML pipeline, namely 1) XAI-enabled decision support, 2) applied XAI for security tasks, 3) model verification via XAI, 4) explanation verification & robustness, and 5) offensive use of explanations. We further classify the literature w.r.t. the targeted security domain. Our analysis of the literature indicates that many of the XAI applications are designed with little understanding of how they might be integrated into analyst workflows -- user studies for explanation evaluation are conducted in only 14% of the cases. The literature also rarely disentangles the role of the various stakeholders. Particularly, the role of the model designer is minimized within the security literature. To this end, we present an illustrative use case accentuating the role of model designers. We demonstrate cases where XAI can help in model verification and cases where it may lead to erroneous conclusions instead. The systematization and use case enable us to challenge several assumptions and present open problems that can help shape the future of XAI within cybersecurity
Learning state machines via efficient hashing of future traces
Jul 04, 2022

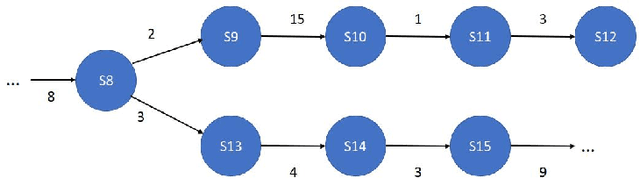
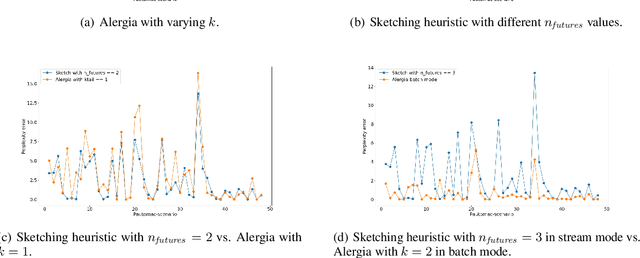
State machines are popular models to model and visualize discrete systems such as software systems, and to represent regular grammars. Most algorithms that passively learn state machines from data assume all the data to be available from the beginning and they load this data into memory. This makes it hard to apply them to continuously streaming data and results in large memory requirements when dealing with large datasets. In this paper we propose a method to learn state machines from data streams using the count-min-sketch data structure to reduce memory requirements. We apply state merging using the well-known red-blue-framework to reduce the search space. We implemented our approach in an established framework for learning state machines, and evaluated it on a well know dataset to provide experimental data, showing the effectiveness of our approach with respect to quality of the results and run-time.
Intelligent Self-Repairable Web Wrappers
Jun 20, 2011
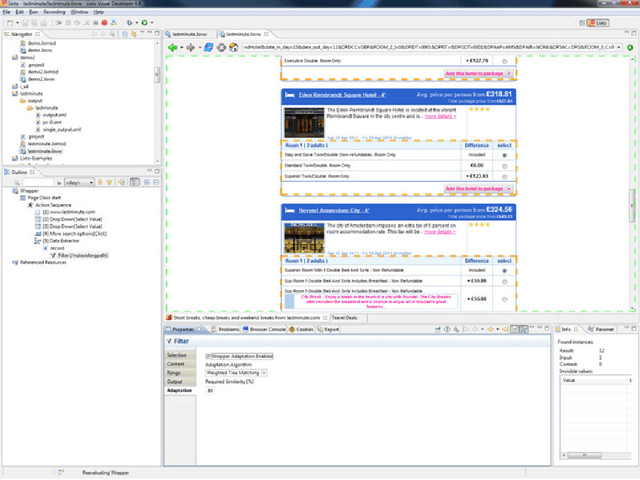

The amount of information available on the Web grows at an incredible high rate. Systems and procedures devised to extract these data from Web sources already exist, and different approaches and techniques have been investigated during the last years. On the one hand, reliable solutions should provide robust algorithms of Web data mining which could automatically face possible malfunctioning or failures. On the other, in literature there is a lack of solutions about the maintenance of these systems. Procedures that extract Web data may be strictly interconnected with the structure of the data source itself; thus, malfunctioning or acquisition of corrupted data could be caused, for example, by structural modifications of data sources brought by their owners. Nowadays, verification of data integrity and maintenance are mostly manually managed, in order to ensure that these systems work correctly and reliably. In this paper we propose a novel approach to create procedures able to extract data from Web sources -- the so called Web wrappers -- which can face possible malfunctioning caused by modifications of the structure of the data source, and can automatically repair themselves.
* 12 pages, 4 figures; Proceedings of the 12th International Conference of the Italian Association for Artificial Intelligence, 2011
Design of Automatically Adaptable Web Wrappers
Mar 07, 2011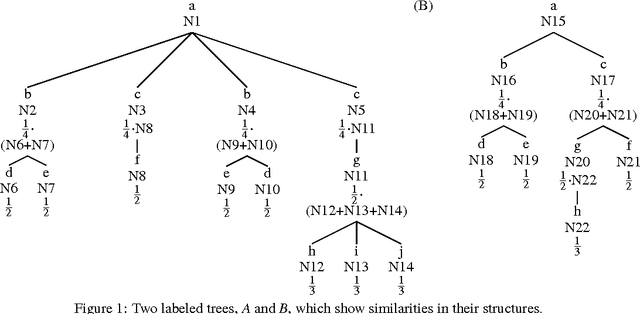
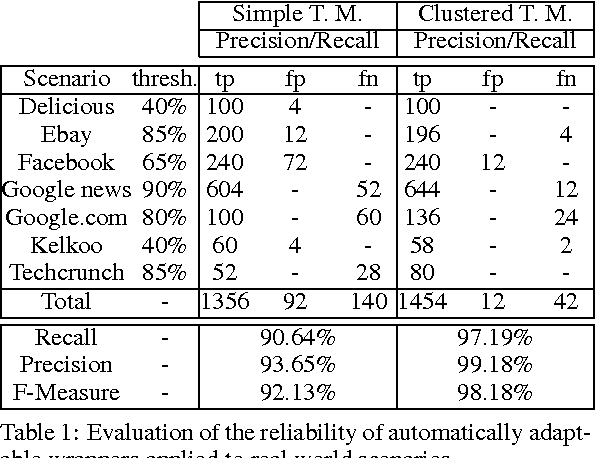
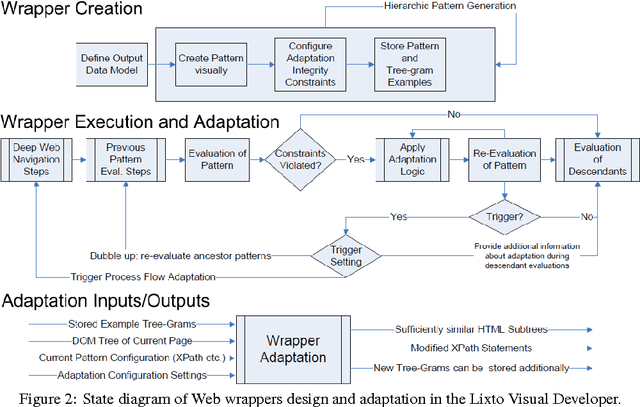
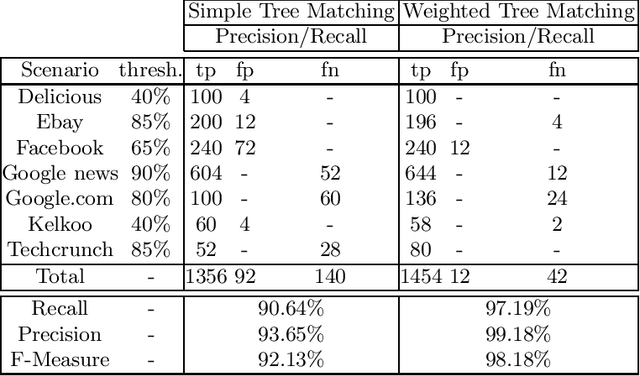
Nowadays, the huge amount of information distributed through the Web motivates studying techniques to be adopted in order to extract relevant data in an efficient and reliable way. Both academia and enterprises developed several approaches of Web data extraction, for example using techniques of artificial intelligence or machine learning. Some commonly adopted procedures, namely wrappers, ensure a high degree of precision of information extracted from Web pages, and, at the same time, have to prove robustness in order not to compromise quality and reliability of data themselves. In this paper we focus on some experimental aspects related to the robustness of the data extraction process and the possibility of automatically adapting wrappers. We discuss the implementation of algorithms for finding similarities between two different version of a Web page, in order to handle modifications, avoiding the failure of data extraction tasks and ensuring reliability of information extracted. Our purpose is to evaluate performances, advantages and draw-backs of our novel system of automatic wrapper adaptation.
* 7 pages, 2 figures, In Proceedings of the 3rd International Conference on Agents and Artificial Intelligence (ICAART 2011)
Automatic Wrapper Adaptation by Tree Edit Distance Matching
Mar 07, 2011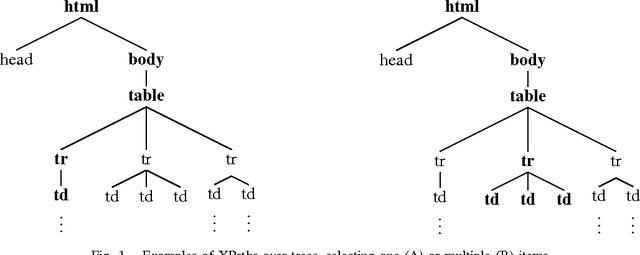
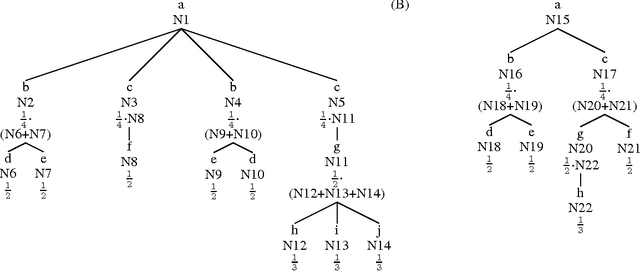


Information distributed through the Web keeps growing faster day by day, and for this reason, several techniques for extracting Web data have been suggested during last years. Often, extraction tasks are performed through so called wrappers, procedures extracting information from Web pages, e.g. implementing logic-based techniques. Many fields of application today require a strong degree of robustness of wrappers, in order not to compromise assets of information or reliability of data extracted. Unfortunately, wrappers may fail in the task of extracting data from a Web page, if its structure changes, sometimes even slightly, thus requiring the exploiting of new techniques to be automatically held so as to adapt the wrapper to the new structure of the page, in case of failure. In this work we present a novel approach of automatic wrapper adaptation based on the measurement of similarity of trees through improved tree edit distance matching techniques.
* 7 pages, 3 figures, In Proceedings of the 2nd International Workshop on Combinations of Intelligent Methods and Applications (CIMA 2010)