 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign of Automatically Adaptable Web Wrappers
Paper and Code
Mar 07, 2011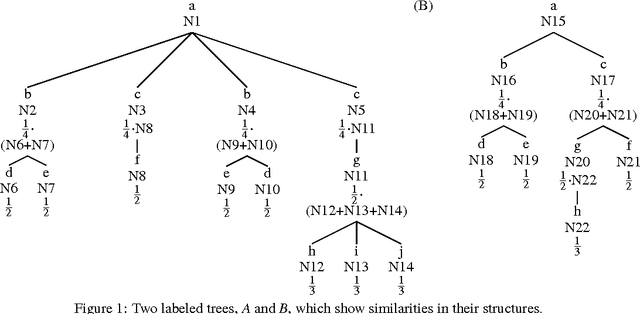
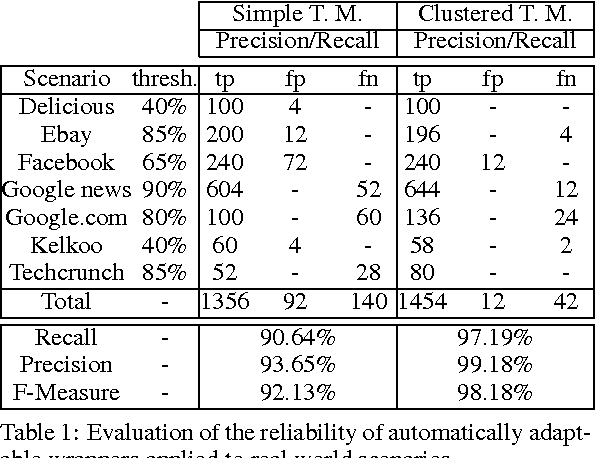
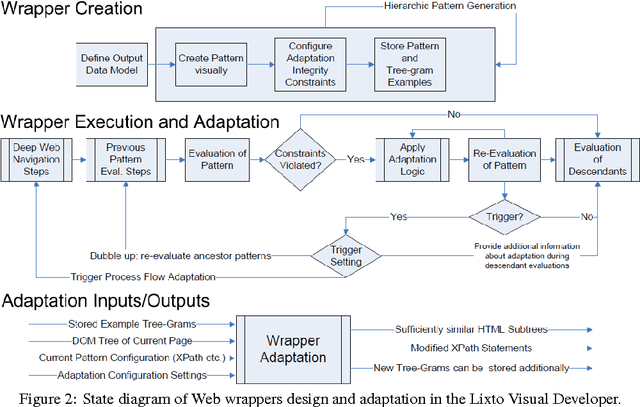
Nowadays, the huge amount of information distributed through the Web motivates studying techniques to be adopted in order to extract relevant data in an efficient and reliable way. Both academia and enterprises developed several approaches of Web data extraction, for example using techniques of artificial intelligence or machine learning. Some commonly adopted procedures, namely wrappers, ensure a high degree of precision of information extracted from Web pages, and, at the same time, have to prove robustness in order not to compromise quality and reliability of data themselves. In this paper we focus on some experimental aspects related to the robustness of the data extraction process and the possibility of automatically adapting wrappers. We discuss the implementation of algorithms for finding similarities between two different version of a Web page, in order to handle modifications, avoiding the failure of data extraction tasks and ensuring reliability of information extracted. Our purpose is to evaluate performances, advantages and draw-backs of our novel system of automatic wrapper adaptation.