 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState Frequency Estimation for Anomaly Detection
Dec 04, 2024



Many works have studied the efficacy of state machines for detecting anomalies within NetFlows. These works typically learn a model from unlabeled data and compute anomaly scores for arbitrary traces based on their likelihood of occurrence or how well they fit within the model. However, these methods do not dynamically adapt their scores based on the traces seen at test time. This becomes a problem when an adversary produces seemingly common traces in their attack, causing the model to miss the detection by assigning low anomaly scores. We propose SEQUENT, a new approach that uses the state visit frequency to adapt its scoring for anomaly detection dynamically. SEQUENT subsequently uses the scores to generate root causes for anomalies. These allow the grouping of alarms and simplify the analysis of anomalies. Our evaluation of SEQUENT on three NetFlow datasets indicates that our approach outperforms existing methods, demonstrating its effectiveness in detecting anomalies.
Encoding NetFlows for State-Machine Learning
Jul 08, 2022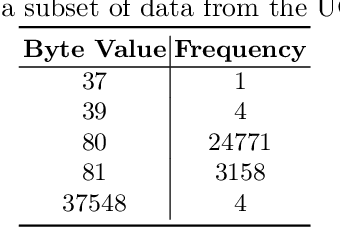
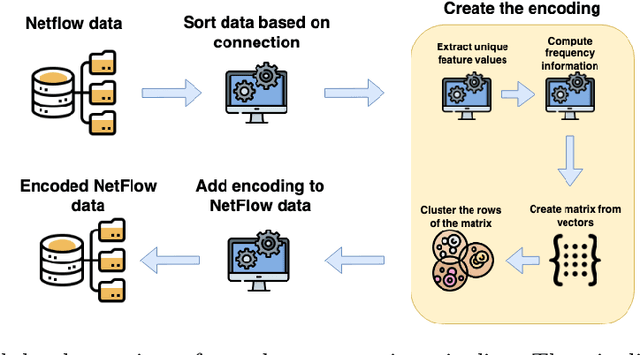
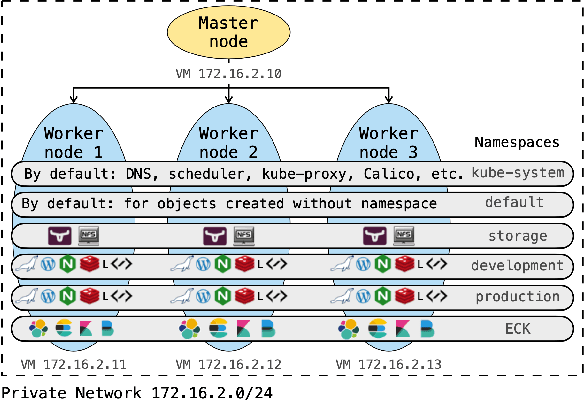
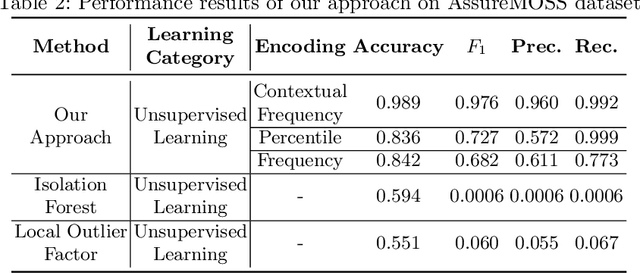
NetFlow data is a well-known network log format used by many network analysts and researchers. The advantages of using this format compared to pcap are that it contains fewer data, is less privacy intrusive, and is easier to collect and process. However, having less data does mean that this format might not be able to capture important network behaviour as all information is summarised into statistics. Much research aims to overcome this disadvantage through the use of machine learning, for instance, to detect attacks within a network. Many approaches can be used to pre-process the NetFlow data before it is used to train the machine learning algorithms. However, many of these approaches simply apply existing methods to the data, not considering the specific properties of network data. We argue that for data originating from software systems, such as NetFlow or software logs, similarities in frequency and contexts of feature values are more important than similarities in the value itself. In this work, we, therefore, propose an encoding algorithm that directly takes the frequency and the context of the feature values into account when the data is being processed. Different types of network behaviours can be clustered using this encoding, thus aiding the process of detecting anomalies within the network. From windows of these clusters obtained from monitoring a clean system, we learn state machine behavioural models for anomaly detection. These models are very well-suited to modelling the cyclic and repetitive patterns present in NetFlow data. We evaluate our encoding on a new dataset that we created for detecting problems in Kubernetes clusters and on two well-known public NetFlow datasets. The obtained performance results of the state machine models are comparable to existing works that use many more features and require both clean and infected data as training input.