 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaiders of the Lost Dependency: Fixing Dependency Conflicts in Python using LLMs
Jan 27, 2025



Fixing Python dependency issues is a tedious and error-prone task for developers, who must manually identify and resolve environment dependencies and version constraints of third-party modules and Python interpreters. Researchers have attempted to automate this process by relying on large knowledge graphs and database lookup tables. However, these traditional approaches face limitations due to the variety of dependency error types, large sets of possible module versions, and conflicts among transitive dependencies. This study explores the potential of using large language models (LLMs) to automatically fix dependency issues in Python programs. We introduce PLLM (pronounced "plum"), a novel technique that employs retrieval-augmented generation (RAG) to help an LLM infer Python versions and required modules for a given Python file. PLLM builds a testing environment that iteratively (1) prompts the LLM for module combinations, (2) tests the suggested changes, and (3) provides feedback (error messages) to the LLM to refine the fix. This feedback cycle leverages natural language processing (NLP) to intelligently parse and interpret build error messages. We benchmark PLLM on the Gistable HG2.9K dataset, a collection of challenging single-file Python gists. We compare PLLM against two state-of-the-art automatic dependency inference approaches, namely PyEGo and ReadPyE, w.r.t. the ability to resolve dependency issues. Our results indicate that PLLM can fix more dependency issues than the two baselines, with +218 (+15.97%) more fixes over ReadPyE and +281 (+21.58%) over PyEGo. Our deeper analyses suggest that PLLM is particularly beneficial for projects with many dependencies and for specific third-party numerical and machine-learning modules. Our findings demonstrate the potential of LLM-based approaches to iteratively resolve Python dependency issues.
Position Paper: Against Spurious Sparks $-$ Dovelating Inflated AI Claims
Feb 07, 2024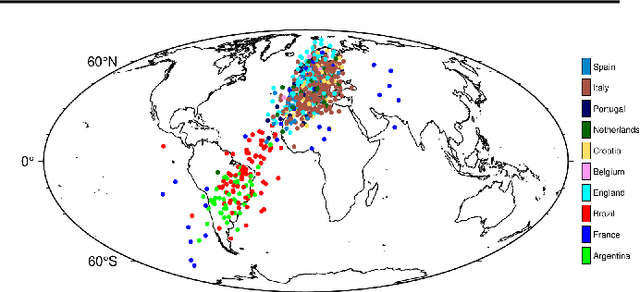

Humans have a tendency to see 'human'-like qualities in objects around them. We name our cars, and talk to pets and even household appliances, as if they could understand us as other humans do. This behavior, called anthropomorphism, is also seeing traction in Machine Learning (ML), where human-like intelligence is claimed to be perceived in Large Language Models (LLMs). In this position paper, considering professional incentives, human biases, and general methodological setups, we discuss how the current search for Artificial General Intelligence (AGI) is a perfect storm for over-attributing human-like qualities to LLMs. In several experiments, we demonstrate that the discovery of human-interpretable patterns in latent spaces should not be a surprising outcome. Also in consideration of common AI portrayal in the media, we call for the academic community to exercise extra caution, and to be extra aware of principles of academic integrity, in interpreting and communicating about AI research outcomes.