 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Test Case Generation for REST APIs Through Hierarchical Clustering
Sep 14, 2021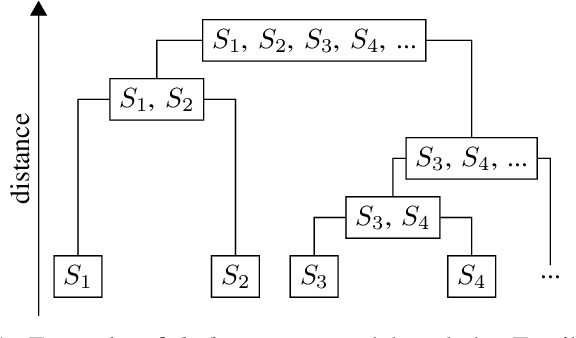
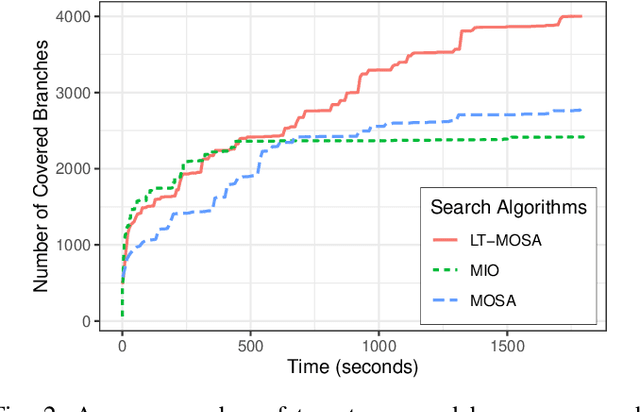
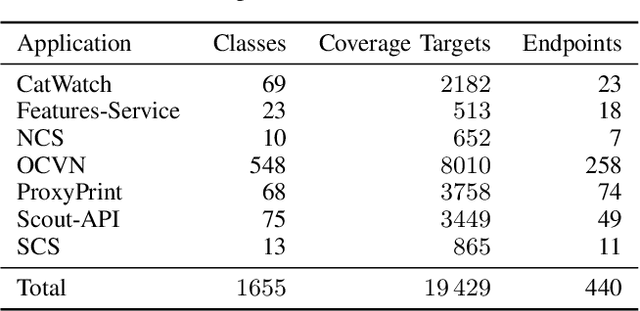
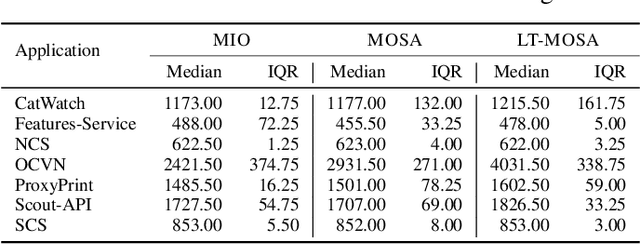
With the ever-increasing use of web APIs in modern-day applications, it is becoming more important to test the system as a whole. In the last decade, tools and approaches have been proposed to automate the creation of system-level test cases for these APIs using evolutionary algorithms (EAs). One of the limiting factors of EAs is that the genetic operators (crossover and mutation) are fully randomized, potentially breaking promising patterns in the sequences of API requests discovered during the search. Breaking these patterns has a negative impact on the effectiveness of the test case generation process. To address this limitation, this paper proposes a new approach that uses agglomerative hierarchical clustering (AHC) to infer a linkage tree model, which captures, replicates, and preserves these patterns in new test cases. We evaluate our approach, called LT-MOSA, by performing an empirical study on 7 real-world benchmark applications w.r.t. branch coverage and real-fault detection capability. We also compare LT-MOSA with the two existing state-of-the-art white-box techniques (MIO, MOSA) for REST API testing. Our results show that LT-MOSA achieves a statistically significant increase in test target coverage (i.e., lines and branches) compared to MIO and MOSA in 4 and 5 out of 7 applications, respectively. Furthermore, LT-MOSA discovers 27 and 18 unique real-faults that are left undetected by MIO and MOSA, respectively.
Multi-objective Test Case Selection Through Linkage Learning-based Crossover
Jul 20, 2021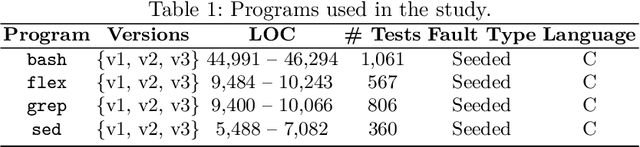
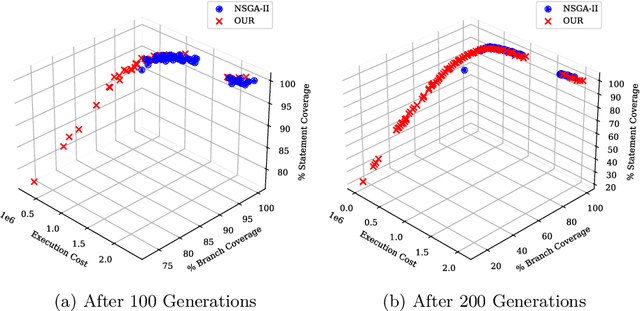
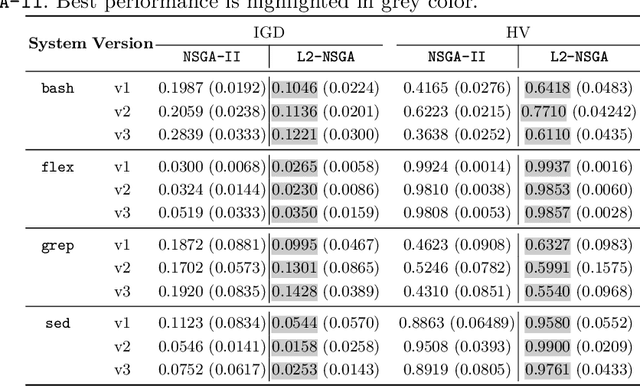
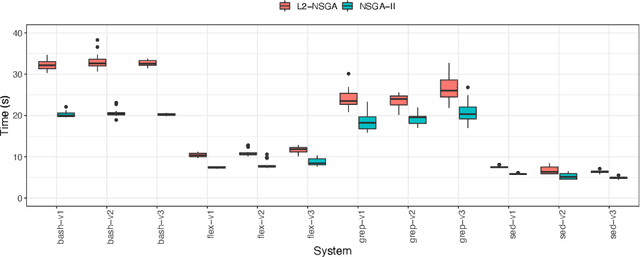
Test Case Selection (TCS) aims to select a subset of the test suite to run for regression testing. The selection is typically based on past coverage and execution cost data. Researchers have successfully used multi-objective evolutionary algorithms (MOEAs), such as NSGA-II and its variants, to solve this problem. These MOEAs use traditional crossover operators to create new candidate solutions through genetic recombination. Recent studies in numerical optimization have shown that better recombinations can be made using machine learning, in particular link-age learning. Inspired by these recent advances in this field, we propose a new variant of NSGA-II, called L2-NSGA, that uses linkage learning to optimize test case selection. In particular, we use an unsupervised clustering algorithm to infer promising patterns among the solutions (subset of test suites). Then, these patterns are used in the next iterations of L2-NSGA to create solutions that preserve these inferred patterns. Our results show that our customizations make NSGA-II more effective for test case selection. The test suite sub-sets generated by L2-NSGA are less expensive and detect more faults than those generated by MOEAs used in the literature for regression testing.