 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSA-Trans: Code Structure Aware Transformer for AST
Apr 07, 2024When applying the Transformer architecture to source code, designing a good self-attention mechanism is critical as it affects how node relationship is extracted from the Abstract Syntax Trees (ASTs) of the source code. We present Code Structure Aware Transformer (CSA-Trans), which uses Code Structure Embedder (CSE) to generate specific PE for each node in AST. CSE generates node Positional Encoding (PE) using disentangled attention. To further extend the self-attention capability, we adopt Stochastic Block Model (SBM) attention. Our evaluation shows that our PE captures the relationships between AST nodes better than other graph-related PE techniques. We also show through quantitative and qualitative analysis that SBM attention is able to generate more node specific attention coefficients. We demonstrate that CSA-Trans outperforms 14 baselines in code summarization tasks for both Python and Java, while being 41.92% faster and 25.31% memory efficient in Java dataset compared to AST-Trans and SG-Trans respectively.
Equivariant Hypergraph Neural Networks
Aug 22, 2022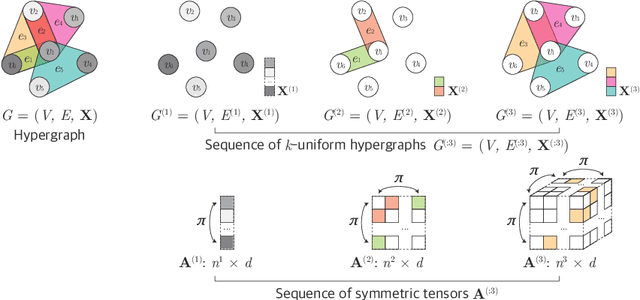

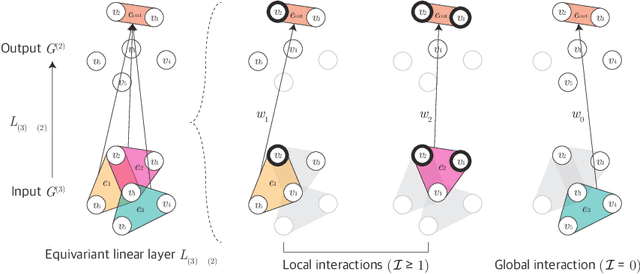

Many problems in computer vision and machine learning can be cast as learning on hypergraphs that represent higher-order relations. Recent approaches for hypergraph learning extend graph neural networks based on message passing, which is simple yet fundamentally limited in modeling long-range dependencies and expressive power. On the other hand, tensor-based equivariant neural networks enjoy maximal expressiveness, but their application has been limited in hypergraphs due to heavy computation and strict assumptions on fixed-order hyperedges. We resolve these problems and present Equivariant Hypergraph Neural Network (EHNN), the first attempt to realize maximally expressive equivariant layers for general hypergraph learning. We also present two practical realizations of our framework based on hypernetworks (EHNN-MLP) and self-attention (EHNN-Transformer), which are easy to implement and theoretically more expressive than most message passing approaches. We demonstrate their capability in a range of hypergraph learning problems, including synthetic k-edge identification, semi-supervised classification, and visual keypoint matching, and report improved performances over strong message passing baselines. Our implementation is available at https://github.com/jw9730/ehnn.
Transformers Generalize DeepSets and Can be Extended to Graphs and Hypergraphs
Oct 27, 2021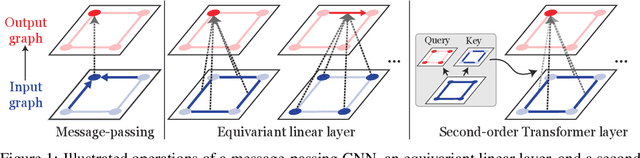
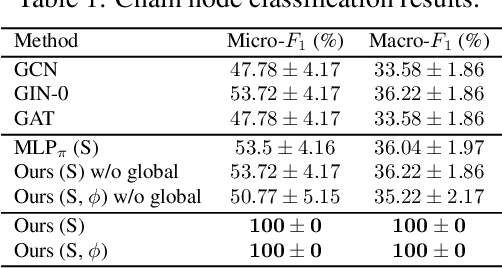
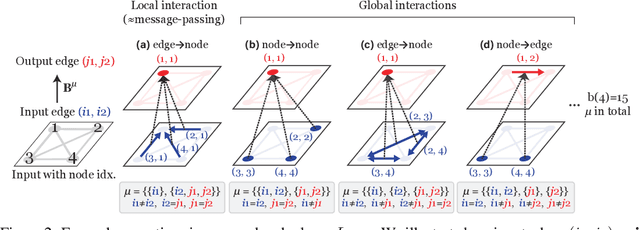

We present a generalization of Transformers to any-order permutation invariant data (sets, graphs, and hypergraphs). We begin by observing that Transformers generalize DeepSets, or first-order (set-input) permutation invariant MLPs. Then, based on recently characterized higher-order invariant MLPs, we extend the concept of self-attention to higher orders and propose higher-order Transformers for order-$k$ data ($k=2$ for graphs and $k>2$ for hypergraphs). Unfortunately, higher-order Transformers turn out to have prohibitive complexity $\mathcal{O}(n^{2k})$ to the number of input nodes $n$. To address this problem, we present sparse higher-order Transformers that have quadratic complexity to the number of input hyperedges, and further adopt the kernel attention approach to reduce the complexity to linear. In particular, we show that the sparse second-order Transformers with kernel attention are theoretically more expressive than message passing operations while having an asymptotically identical complexity. Our models achieve significant performance improvement over invariant MLPs and message-passing graph neural networks in large-scale graph regression and set-to-(hyper)graph prediction tasks. Our implementation is available at https://github.com/jw9730/hot.