 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
EAGLE: Contrastive Learning for Efficient Graph Anomaly Detection
May 12, 2025



Graph anomaly detection is a popular and vital task in various real-world scenarios, which has been studied for several decades. Recently, many studies extending deep learning-based methods have shown preferable performance on graph anomaly detection. However, existing methods are lack of efficiency that is definitely necessary for embedded devices. Towards this end, we propose an Efficient Anomaly detection model on heterogeneous Graphs via contrastive LEarning (EAGLE) by contrasting abnormal nodes with normal ones in terms of their distances to the local context. The proposed method first samples instance pairs on meta path-level for contrastive learning. Then, a graph autoencoder-based model is applied to learn informative node embeddings in an unsupervised way, which will be further combined with the discriminator to predict the anomaly scores of nodes. Experimental results show that EAGLE outperforms the state-of-the-art methods on three heterogeneous network datasets.
STRIVE: Structured Representation Integrating VLM Reasoning for Efficient Object Navigation
May 10, 2025



Vision-Language Models (VLMs) have been increasingly integrated into object navigation tasks for their rich prior knowledge and strong reasoning abilities. However, applying VLMs to navigation poses two key challenges: effectively representing complex environment information and determining \textit{when and how} to query VLMs. Insufficient environment understanding and over-reliance on VLMs (e.g. querying at every step) can lead to unnecessary backtracking and reduced navigation efficiency, especially in continuous environments. To address these challenges, we propose a novel framework that constructs a multi-layer representation of the environment during navigation. This representation consists of viewpoint, object nodes, and room nodes. Viewpoints and object nodes facilitate intra-room exploration and accurate target localization, while room nodes support efficient inter-room planning. Building on this representation, we propose a novel two-stage navigation policy, integrating high-level planning guided by VLM reasoning with low-level VLM-assisted exploration to efficiently locate a goal object. We evaluated our approach on three simulated benchmarks (HM3D, RoboTHOR, and MP3D), and achieved state-of-the-art performance on both the success rate ($\mathord{\uparrow}\, 7.1\%$) and navigation efficiency ($\mathord{\uparrow}\, 12.5\%$). We further validate our method on a real robot platform, demonstrating strong robustness across 15 object navigation tasks in 10 different indoor environments. Project page is available at https://zwandering.github.io/STRIVE.github.io/ .
Design Topological Materials by Reinforcement Fine-Tuned Generative Model
Apr 17, 2025Topological insulators (TIs) and topological crystalline insulators (TCIs) are materials with unconventional electronic properties, making their discovery highly valuable for practical applications. However, such materials, particularly those with a full band gap, remain scarce. Given the limitations of traditional approaches that scan known materials for candidates, we focus on the generation of new topological materials through a generative model. Specifically, we apply reinforcement fine-tuning (ReFT) to a pre-trained generative model, thereby aligning the model's objectives with our material design goals. We demonstrate that ReFT is effective in enhancing the model's ability to generate TIs and TCIs, with minimal compromise on the stability of the generated materials. Using the fine-tuned model, we successfully identify a large number of new topological materials, with Ge$_2$Bi$_2$O$_6$ serving as a representative example--a TI with a full band gap of 0.26 eV, ranking among the largest known in this category.
MOSAIC: Generating Consistent, Privacy-Preserving Scenes from Multiple Depth Views in Multi-Room Environments
Mar 18, 2025We introduce a novel diffusion-based approach for generating privacy-preserving digital twins of multi-room indoor environments from depth images only. Central to our approach is a novel Multi-view Overlapped Scene Alignment with Implicit Consistency (MOSAIC) model that explicitly considers cross-view dependencies within the same scene in the probabilistic sense. MOSAIC operates through a novel inference-time optimization that avoids error accumulation common in sequential or single-room constraint in panorama-based approaches. MOSAIC scales to complex scenes with zero extra training and provably reduces the variance during denoising processes when more overlapping views are added, leading to improved generation quality. Experiments show that MOSAIC outperforms state-of-the-art baselines on image fidelity metrics in reconstructing complex multi-room environments. Project page is available at: https://mosaic-cmubig.github.io
Emergent Response Planning in LLM
Feb 10, 2025



In this work, we argue that large language models (LLMs), though trained to predict only the next token, exhibit emergent planning behaviors: $\textbf{their hidden representations encode future outputs beyond the next token}$. Through simple probing, we demonstrate that LLM prompt representations encode global attributes of their entire responses, including $\textit{structural attributes}$ (response length, reasoning steps), $\textit{content attributes}$ (character choices in storywriting, multiple-choice answers at the end of response), and $\textit{behavioral attributes}$ (answer confidence, factual consistency). In addition to identifying response planning, we explore how it scales with model size across tasks and how it evolves during generation. The findings that LLMs plan ahead for the future in their hidden representations suggests potential applications for improving transparency and generation control.
Inference-Time Language Model Alignment via Integrated Value Guidance
Sep 26, 2024Large language models are typically fine-tuned to align with human preferences, but tuning large models is computationally intensive and complex. In this work, we introduce $\textit{Integrated Value Guidance}$ (IVG), a method that uses implicit and explicit value functions to guide language model decoding at token and chunk-level respectively, efficiently aligning large language models purely at inference time. This approach circumvents the complexities of direct fine-tuning and outperforms traditional methods. Empirically, we demonstrate the versatility of IVG across various tasks. In controlled sentiment generation and summarization tasks, our method significantly improves the alignment of large models using inference-time guidance from $\texttt{gpt2}$-based value functions. Moreover, in a more challenging instruction-following benchmark AlpacaEval 2.0, we show that both specifically tuned and off-the-shelf value functions greatly improve the length-controlled win rates of large models against $\texttt{gpt-4-turbo}$ (e.g., $19.51\% \rightarrow 26.51\%$ for $\texttt{Mistral-7B-Instruct-v0.2}$ and $25.58\% \rightarrow 33.75\%$ for $\texttt{Mixtral-8x7B-Instruct-v0.1}$ with Tulu guidance).
Weak-to-Strong Search: Align Large Language Models via Searching over Small Language Models
May 29, 2024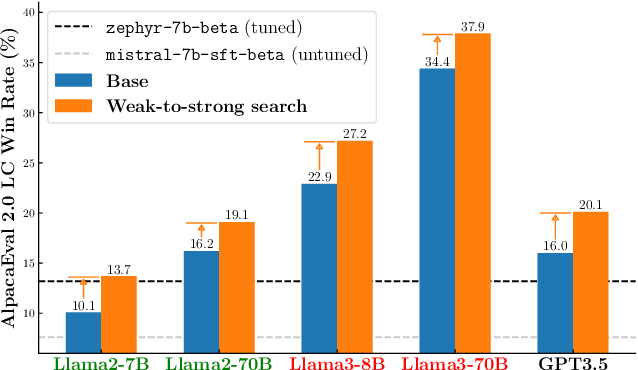
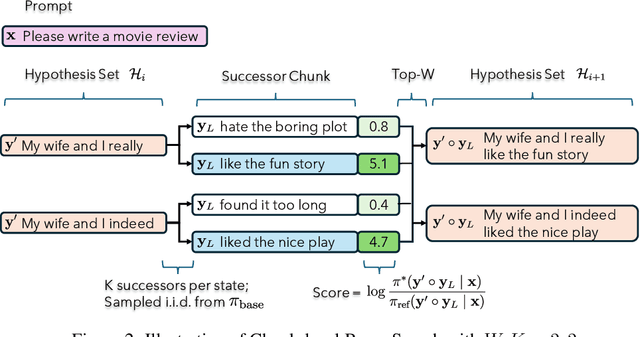
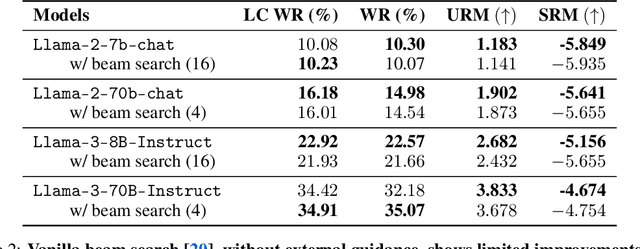
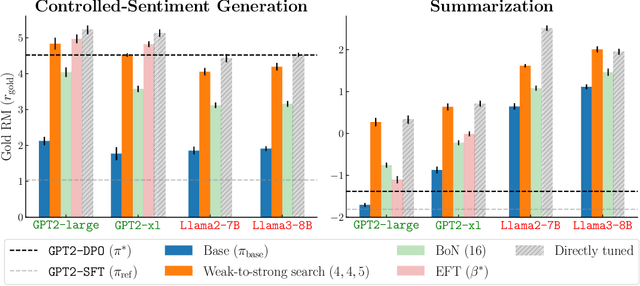
Large language models are usually fine-tuned to align with human preferences. However, fine-tuning a large language model can be challenging. In this work, we introduce $\textit{weak-to-strong search}$, framing the alignment of a large language model as a test-time greedy search to maximize the log-likelihood difference between small tuned and untuned models while sampling from the frozen large model. This method serves both as (i) a compute-efficient model up-scaling strategy that avoids directly tuning the large model and as (ii) an instance of weak-to-strong generalization that enhances a strong model with weak test-time guidance. Empirically, we demonstrate the flexibility of weak-to-strong search across different tasks. In controlled-sentiment generation and summarization, we use tuned and untuned $\texttt{gpt2}$s to effectively improve the alignment of large models without additional training. Crucially, in a more difficult instruction-following benchmark, AlpacaEval 2.0, we show that reusing off-the-shelf small model pairs (e.g., $\texttt{zephyr-7b-beta}$ and its untuned version) can significantly improve the length-controlled win rates of both white-box and black-box large models against $\texttt{gpt-4-turbo}$ (e.g., $34.4 \rightarrow 37.9$ for $\texttt{Llama-3-70B-Instruct}$ and $16.0 \rightarrow 20.1$ for $\texttt{gpt-3.5-turbo-instruct}$), despite the small models' low win rates $\approx 10.0$.
SCoFT: Self-Contrastive Fine-Tuning for Equitable Image Generation
Jan 16, 2024



Accurate representation in media is known to improve the well-being of the people who consume it. Generative image models trained on large web-crawled datasets such as LAION are known to produce images with harmful stereotypes and misrepresentations of cultures. We improve inclusive representation in generated images by (1) engaging with communities to collect a culturally representative dataset that we call the Cross-Cultural Understanding Benchmark (CCUB) and (2) proposing a novel Self-Contrastive Fine-Tuning (SCoFT) method that leverages the model's known biases to self-improve. SCoFT is designed to prevent overfitting on small datasets, encode only high-level information from the data, and shift the generated distribution away from misrepresentations encoded in a pretrained model. Our user study conducted on 51 participants from 5 different countries based on their self-selected national cultural affiliation shows that fine-tuning on CCUB consistently generates images with higher cultural relevance and fewer stereotypes when compared to the Stable Diffusion baseline, which is further improved with our SCoFT technique.
Towards Equitable Representation in Text-to-Image Synthesis Models with the Cross-Cultural Understanding Benchmark (CCUB) Dataset
Jan 28, 2023



It has been shown that accurate representation in media improves the well-being of the people who consume it. By contrast, inaccurate representations can negatively affect viewers and lead to harmful perceptions of other cultures. To achieve inclusive representation in generated images, we propose a culturally-aware priming approach for text-to-image synthesis using a small but culturally curated dataset that we collected, known here as Cross-Cultural Understanding Benchmark (CCUB) Dataset, to fight the bias prevalent in giant datasets. Our proposed approach is comprised of two fine-tuning techniques: (1) Adding visual context via fine-tuning a pre-trained text-to-image synthesis model, Stable Diffusion, on the CCUB text-image pairs, and (2) Adding semantic context via automated prompt engineering using the fine-tuned large language model, GPT-3, trained on our CCUB culturally-aware text data. CCUB dataset is curated and our approach is evaluated by people who have a personal relationship with that particular culture. Our experiments indicate that priming using both text and image is effective in improving the cultural relevance and decreasing the offensiveness of generated images while maintaining quality.