 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Emergent Response Planning in LLM
Feb 10, 2025



In this work, we argue that large language models (LLMs), though trained to predict only the next token, exhibit emergent planning behaviors: $\textbf{their hidden representations encode future outputs beyond the next token}$. Through simple probing, we demonstrate that LLM prompt representations encode global attributes of their entire responses, including $\textit{structural attributes}$ (response length, reasoning steps), $\textit{content attributes}$ (character choices in storywriting, multiple-choice answers at the end of response), and $\textit{behavioral attributes}$ (answer confidence, factual consistency). In addition to identifying response planning, we explore how it scales with model size across tasks and how it evolves during generation. The findings that LLMs plan ahead for the future in their hidden representations suggests potential applications for improving transparency and generation control.
Weak-to-Strong Search: Align Large Language Models via Searching over Small Language Models
May 29, 2024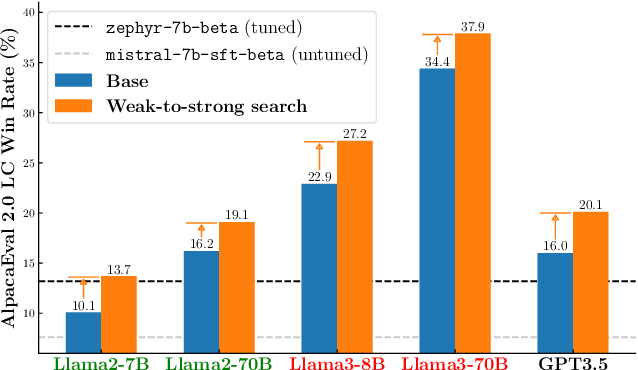
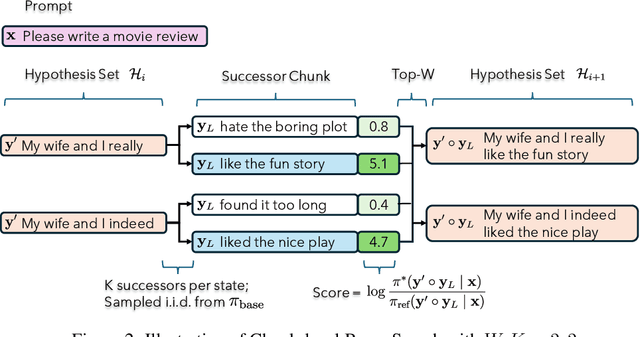
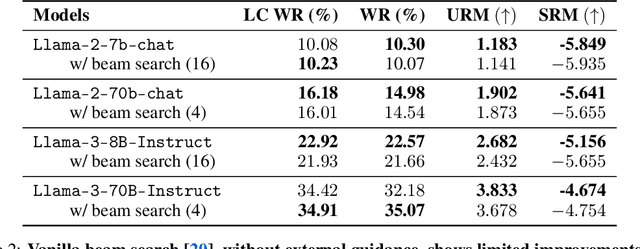
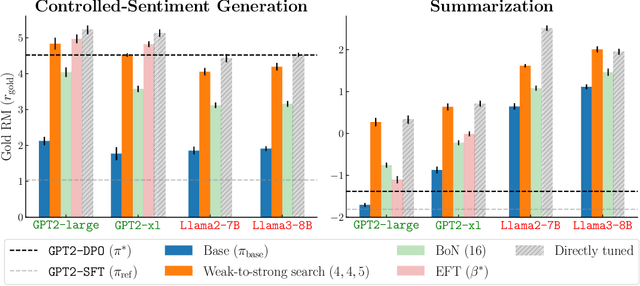
Large language models are usually fine-tuned to align with human preferences. However, fine-tuning a large language model can be challenging. In this work, we introduce $\textit{weak-to-strong search}$, framing the alignment of a large language model as a test-time greedy search to maximize the log-likelihood difference between small tuned and untuned models while sampling from the frozen large model. This method serves both as (i) a compute-efficient model up-scaling strategy that avoids directly tuning the large model and as (ii) an instance of weak-to-strong generalization that enhances a strong model with weak test-time guidance. Empirically, we demonstrate the flexibility of weak-to-strong search across different tasks. In controlled-sentiment generation and summarization, we use tuned and untuned $\texttt{gpt2}$s to effectively improve the alignment of large models without additional training. Crucially, in a more difficult instruction-following benchmark, AlpacaEval 2.0, we show that reusing off-the-shelf small model pairs (e.g., $\texttt{zephyr-7b-beta}$ and its untuned version) can significantly improve the length-controlled win rates of both white-box and black-box large models against $\texttt{gpt-4-turbo}$ (e.g., $34.4 \rightarrow 37.9$ for $\texttt{Llama-3-70B-Instruct}$ and $16.0 \rightarrow 20.1$ for $\texttt{gpt-3.5-turbo-instruct}$), despite the small models' low win rates $\approx 10.0$.
Emulated Disalignment: Safety Alignment for Large Language Models May Backfire!
Feb 21, 2024



Large language models (LLMs) need to undergo safety alignment to ensure safe conversations with humans. However, in this work, we introduce an inference-time attack framework, demonstrating that safety alignment can also unintentionally facilitate harmful outcomes under adversarial manipulation. This framework, named Emulated Disalignment (ED), adversely combines a pair of open-source pre-trained and safety-aligned language models in the output space to produce a harmful language model without additional training. Our experiments with ED across three datasets and four model families (Llama-1, Llama-2, Mistral, and Alpaca) show that ED doubles the harmfulness of pre-trained models and outperforms strong baselines, achieving the highest harmful rate in 43 out of 48 evaluation subsets by a large margin. Crucially, our findings highlight the importance of reevaluating the practice of open-sourcing language models even after safety alignment.
Attacks, Defenses and Evaluations for LLM Conversation Safety: A Survey
Feb 14, 2024


Large Language Models (LLMs) are now commonplace in conversation applications. However, their risks of misuse for generating harmful responses have raised serious societal concerns and spurred recent research on LLM conversation safety. Therefore, in this survey, we provide a comprehensive overview of recent studies, covering three critical aspects of LLM conversation safety: attacks, defenses, and evaluations. Our goal is to provide a structured summary that enhances understanding of LLM conversation safety and encourages further investigation into this important subject. For easy reference, we have categorized all the studies mentioned in this survey according to our taxonomy, available at: https://github.com/niconi19/LLM-conversation-safety.