 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot Every Gift Comes in Gold Paper or with a Red Ribbon: Exploring Color Perception in Text-to-Image Models
Aug 27, 2025Text-to-image generation has recently seen remarkable success, granting users with the ability to create high-quality images through the use of text. However, contemporary methods face challenges in capturing the precise semantics conveyed by complex multi-object prompts. Consequently, many works have sought to mitigate such semantic misalignments, typically via inference-time schemes that modify the attention layers of the denoising networks. However, prior work has mostly utilized coarse metrics, such as the cosine similarity between text and image CLIP embeddings, or human evaluations, which are challenging to conduct on a larger-scale. In this work, we perform a case study on colors -- a fundamental attribute commonly associated with objects in text prompts, which offer a rich test bed for rigorous evaluation. Our analysis reveals that pretrained models struggle to generate images that faithfully reflect multiple color attributes-far more so than with single-color prompts-and that neither inference-time techniques nor existing editing methods reliably resolve these semantic misalignments. Accordingly, we introduce a dedicated image editing technique, mitigating the issue of multi-object semantic alignment for prompts containing multiple colors. We demonstrate that our approach significantly boosts performance over a wide range of metrics, considering images generated by various text-to-image diffusion-based techniques.
NaturalBench: Evaluating Vision-Language Models on Natural Adversarial Samples
Oct 18, 2024
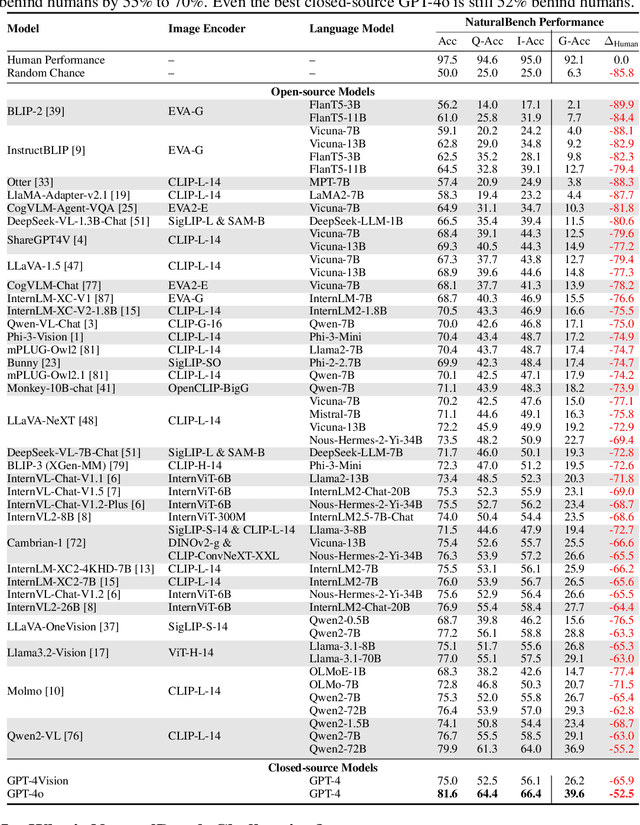

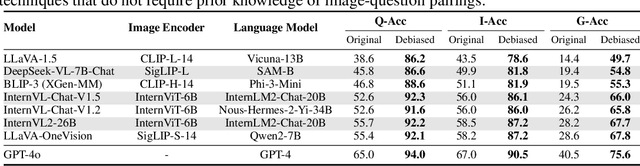
Vision-language models (VLMs) have made significant progress in recent visual-question-answering (VQA) benchmarks that evaluate complex visio-linguistic reasoning. However, are these models truly effective? In this work, we show that VLMs still struggle with natural images and questions that humans can easily answer, which we term natural adversarial samples. We also find it surprisingly easy to generate these VQA samples from natural image-text corpora using off-the-shelf models like CLIP and ChatGPT. We propose a semi-automated approach to collect a new benchmark, NaturalBench, for reliably evaluating VLMs with 10,000 human-verified VQA samples. Crucially, we adopt a $\textbf{vision-centric}$ design by pairing each question with two images that yield different answers, preventing blind solutions from answering without using the images. This makes NaturalBench more challenging than previous benchmarks that can be solved with commonsense priors. We evaluate 53 state-of-the-art VLMs on NaturalBench, showing that models like LLaVA-OneVision, Cambrian-1, Llama3.2-Vision, Molmo, Qwen2-VL, and even GPT-4o lag 50%-70% behind human performance (over 90%). We analyze why NaturalBench is hard from two angles: (1) Compositionality: Solving NaturalBench requires diverse visio-linguistic skills, including understanding attribute bindings, object relationships, and advanced reasoning like logic and counting. To this end, unlike prior work that uses a single tag per sample, we tag each NaturalBench sample with 1 to 8 skill tags for fine-grained evaluation. (2) Biases: NaturalBench exposes severe biases in VLMs, as models often choose the same answer regardless of the image. Lastly, we apply our benchmark curation method to diverse data sources, including long captions (over 100 words) and non-English languages like Chinese and Hindi, highlighting its potential for dynamic evaluations of VLMs.
4D Panoptic Scene Graph Generation
May 16, 2024


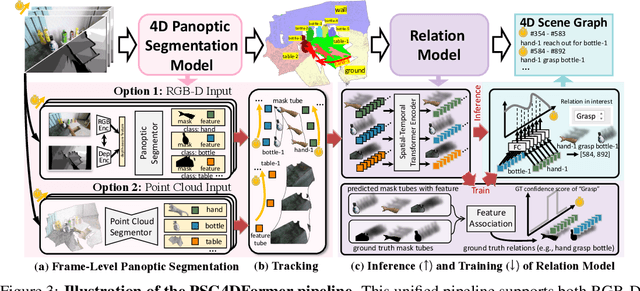
We are living in a three-dimensional space while moving forward through a fourth dimension: time. To allow artificial intelligence to develop a comprehensive understanding of such a 4D environment, we introduce 4D Panoptic Scene Graph (PSG-4D), a new representation that bridges the raw visual data perceived in a dynamic 4D world and high-level visual understanding. Specifically, PSG-4D abstracts rich 4D sensory data into nodes, which represent entities with precise location and status information, and edges, which capture the temporal relations. To facilitate research in this new area, we build a richly annotated PSG-4D dataset consisting of 3K RGB-D videos with a total of 1M frames, each of which is labeled with 4D panoptic segmentation masks as well as fine-grained, dynamic scene graphs. To solve PSG-4D, we propose PSG4DFormer, a Transformer-based model that can predict panoptic segmentation masks, track masks along the time axis, and generate the corresponding scene graphs via a relation component. Extensive experiments on the new dataset show that our method can serve as a strong baseline for future research on PSG-4D. In the end, we provide a real-world application example to demonstrate how we can achieve dynamic scene understanding by integrating a large language model into our PSG-4D system.
SCoFT: Self-Contrastive Fine-Tuning for Equitable Image Generation
Jan 16, 2024



Accurate representation in media is known to improve the well-being of the people who consume it. Generative image models trained on large web-crawled datasets such as LAION are known to produce images with harmful stereotypes and misrepresentations of cultures. We improve inclusive representation in generated images by (1) engaging with communities to collect a culturally representative dataset that we call the Cross-Cultural Understanding Benchmark (CCUB) and (2) proposing a novel Self-Contrastive Fine-Tuning (SCoFT) method that leverages the model's known biases to self-improve. SCoFT is designed to prevent overfitting on small datasets, encode only high-level information from the data, and shift the generated distribution away from misrepresentations encoded in a pretrained model. Our user study conducted on 51 participants from 5 different countries based on their self-selected national cultural affiliation shows that fine-tuning on CCUB consistently generates images with higher cultural relevance and fewer stereotypes when compared to the Stable Diffusion baseline, which is further improved with our SCoFT technique.
Panoptic Video Scene Graph Generation
Nov 28, 2023
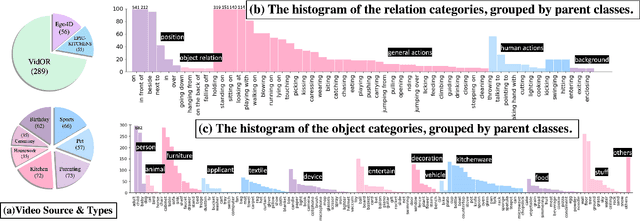
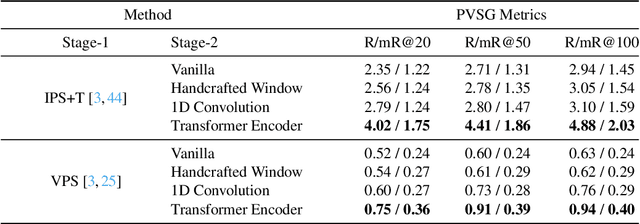
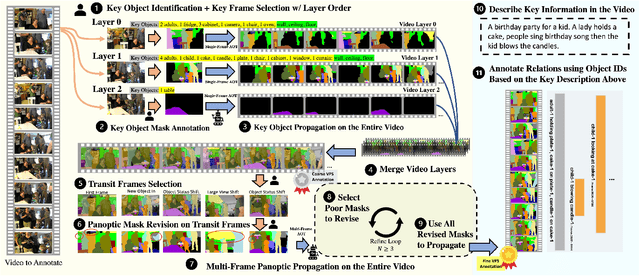
Towards building comprehensive real-world visual perception systems, we propose and study a new problem called panoptic scene graph generation (PVSG). PVSG relates to the existing video scene graph generation (VidSGG) problem, which focuses on temporal interactions between humans and objects grounded with bounding boxes in videos. However, the limitation of bounding boxes in detecting non-rigid objects and backgrounds often causes VidSGG to miss key details crucial for comprehensive video understanding. In contrast, PVSG requires nodes in scene graphs to be grounded by more precise, pixel-level segmentation masks, which facilitate holistic scene understanding. To advance research in this new area, we contribute the PVSG dataset, which consists of 400 videos (289 third-person + 111 egocentric videos) with a total of 150K frames labeled with panoptic segmentation masks as well as fine, temporal scene graphs. We also provide a variety of baseline methods and share useful design practices for future work.
OpenOOD: Benchmarking Generalized Out-of-Distribution Detection
Oct 13, 2022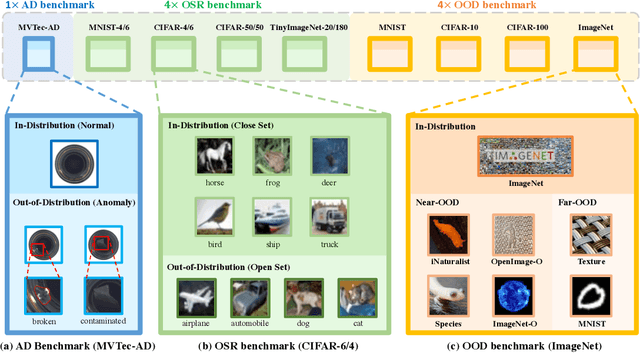
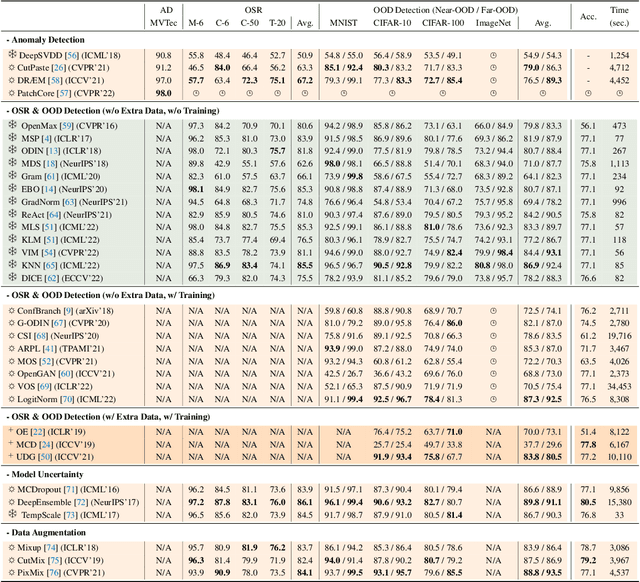
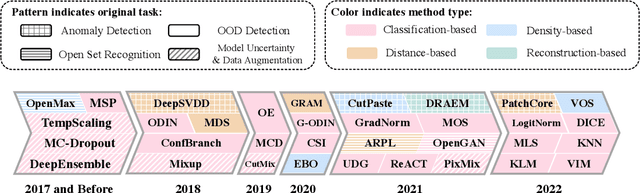
Out-of-distribution (OOD) detection is vital to safety-critical machine learning applications and has thus been extensively studied, with a plethora of methods developed in the literature. However, the field currently lacks a unified, strictly formulated, and comprehensive benchmark, which often results in unfair comparisons and inconclusive results. From the problem setting perspective, OOD detection is closely related to neighboring fields including anomaly detection (AD), open set recognition (OSR), and model uncertainty, since methods developed for one domain are often applicable to each other. To help the community to improve the evaluation and advance, we build a unified, well-structured codebase called OpenOOD, which implements over 30 methods developed in relevant fields and provides a comprehensive benchmark under the recently proposed generalized OOD detection framework. With a comprehensive comparison of these methods, we are gratified that the field has progressed significantly over the past few years, where both preprocessing methods and the orthogonal post-hoc methods show strong potential.