 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Visualization: A Benchmark and Method for Knowledge-Intensive Text-to-Image Generation
Apr 24, 2026Recent text-to-image (T2I) models have demonstrated impressive capabilities in photorealistic synthesis and instruction following. However, their reliability in knowledge-intensive settings remains largely unexplored. Unlike natural image generation, knowledge visualization requires not only semantic alignment but also strict adherence to domain knowledge, structural constraints, and symbolic conventions, exposing a critical gap between visual plausibility and scientific correctness. To systematically study this problem, we introduce KVBench, a curriculum-grounded benchmark for evaluating knowledge-intensive T2I generation. KVBench covers six senior high-school subjects: Biology, Chemistry, Geography, History, Mathematics, and Physics. The benchmark consists of 1,800 expert-curated prompts derived from over 30 authoritative textbooks. Using this benchmark, we evaluate 14 state-of-the-art open- and closed-source models, revealing substantial deficiencies in logical reasoning, symbolic precision, and multilingual robustness, with open-source models consistently underperforming proprietary systems. To address these limitations, we further propose KE-Check, a two-stage framework that improves scientific fidelity via (1) Knowledge Elaboration for structured prompt enrichment, and (2) Checklist-Guided Refinement for explicit constraint enforcement through violation identification and constraint-guided editing. KE-Check effectively mitigates scientific hallucinations, narrowing the performance gap between open-source and leading closed-source models. Data and codes are publicly available at https://github.com/zhaoran66/KVBench.
HippoCamp: Benchmarking Contextual Agents on Personal Computers
Apr 01, 2026We present HippoCamp, a new benchmark designed to evaluate agents' capabilities on multimodal file management. Unlike existing agent benchmarks that focus on tasks like web interaction, tool use, or software automation in generic settings, HippoCamp evaluates agents in user-centric environments to model individual user profiles and search massive personal files for context-aware reasoning. Our benchmark instantiates device-scale file systems over real-world profiles spanning diverse modalities, comprising 42.4 GB of data across over 2K real-world files. Building upon the raw files, we construct 581 QA pairs to assess agents' capabilities in search, evidence perception, and multi-step reasoning. To facilitate fine-grained analysis, we provide 46.1K densely annotated structured trajectories for step-wise failure diagnosis. We evaluate a wide range of state-of-the-art multimodal large language models (MLLMs) and agentic methods on HippoCamp. Our comprehensive experiments reveal a significant performance gap: even the most advanced commercial models achieve only 48.3% accuracy in user profiling, struggling particularly with long-horizon retrieval and cross-modal reasoning within dense personal file systems. Furthermore, our step-wise failure diagnosis identifies multimodal perception and evidence grounding as the primary bottlenecks. Ultimately, HippoCamp exposes the critical limitations of current agents in realistic, user-centric environments and provides a robust foundation for developing next-generation personal AI assistants.
Generalizable Implicit Motion Modeling for Video Frame Interpolation
Jul 11, 2024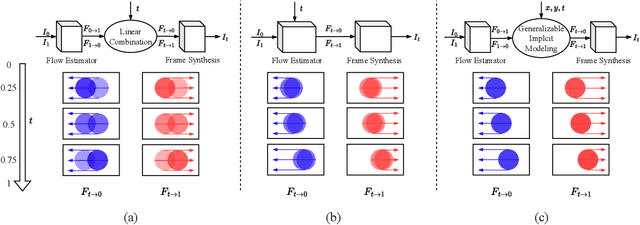

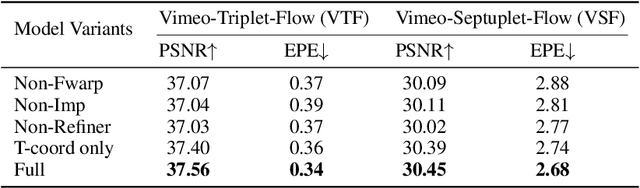
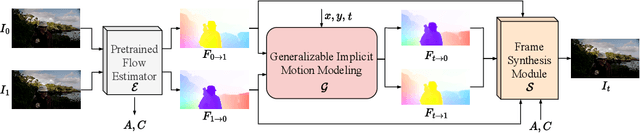
Motion modeling is critical in flow-based Video Frame Interpolation (VFI). Existing paradigms either consider linear combinations of bidirectional flows or directly predict bilateral flows for given timestamps without exploring favorable motion priors, thus lacking the capability of effectively modeling spatiotemporal dynamics in real-world videos. To address this limitation, in this study, we introduce Generalizable Implicit Motion Modeling (GIMM), a novel and effective approach to motion modeling for VFI. Specifically, to enable GIMM as an effective motion modeling paradigm, we design a motion encoding pipeline to model spatiotemporal motion latent from bidirectional flows extracted from pre-trained flow estimators, effectively representing input-specific motion priors. Then, we implicitly predict arbitrary-timestep optical flows within two adjacent input frames via an adaptive coordinate-based neural network, with spatiotemporal coordinates and motion latent as inputs. Our GIMM can be smoothly integrated with existing flow-based VFI works without further modifications. We show that GIMM performs better than the current state of the art on the VFI benchmarks.
Panoptic Video Scene Graph Generation
Nov 28, 2023
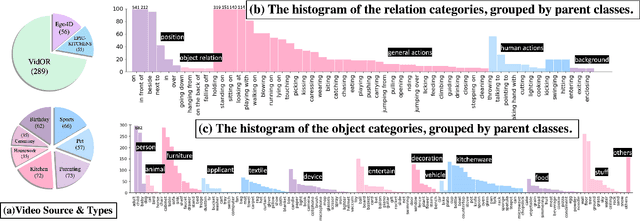
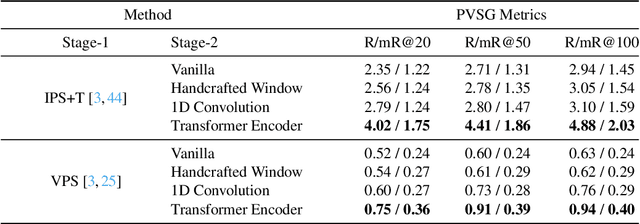
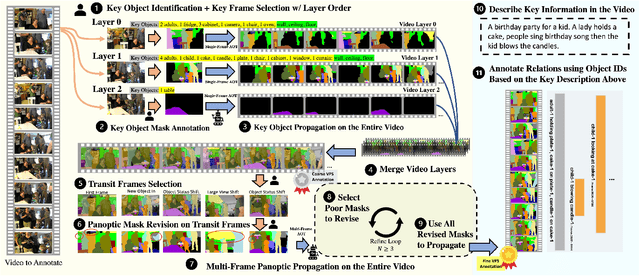
Towards building comprehensive real-world visual perception systems, we propose and study a new problem called panoptic scene graph generation (PVSG). PVSG relates to the existing video scene graph generation (VidSGG) problem, which focuses on temporal interactions between humans and objects grounded with bounding boxes in videos. However, the limitation of bounding boxes in detecting non-rigid objects and backgrounds often causes VidSGG to miss key details crucial for comprehensive video understanding. In contrast, PVSG requires nodes in scene graphs to be grounded by more precise, pixel-level segmentation masks, which facilitate holistic scene understanding. To advance research in this new area, we contribute the PVSG dataset, which consists of 400 videos (289 third-person + 111 egocentric videos) with a total of 150K frames labeled with panoptic segmentation masks as well as fine, temporal scene graphs. We also provide a variety of baseline methods and share useful design practices for future work.
Pair then Relation: Pair-Net for Panoptic Scene Graph Generation
Aug 01, 2023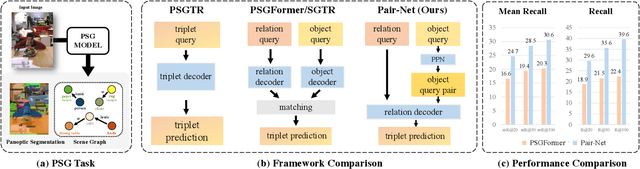

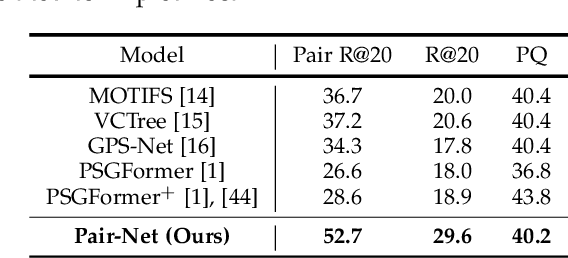
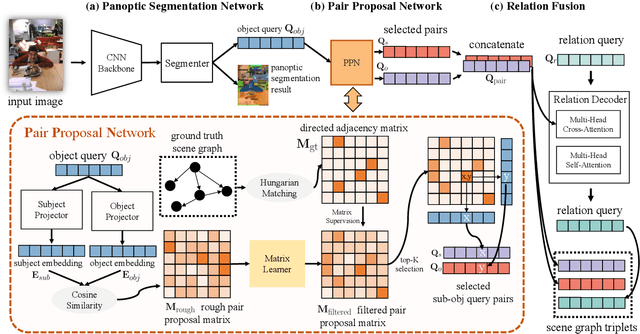
Panoptic Scene Graph (PSG) is a challenging task in Scene Graph Generation (SGG) that aims to create a more comprehensive scene graph representation using panoptic segmentation instead of boxes. Compared to SGG, PSG has several challenging problems: pixel-level segment outputs and full relationship exploration (It also considers thing and stuff relation). Thus, current PSG methods have limited performance, which hinders downstream tasks or applications. The goal of this work aims to design a novel and strong baseline for PSG. To achieve that, we first conduct an in-depth analysis to identify the bottleneck of the current PSG models, finding that inter-object pair-wise recall is a crucial factor that was ignored by previous PSG methods. Based on this and the recent query-based frameworks, we present a novel framework: Pair then Relation (Pair-Net), which uses a Pair Proposal Network (PPN) to learn and filter sparse pair-wise relationships between subjects and objects. Moreover, we also observed the sparse nature of object pairs for both Motivated by this, we design a lightweight Matrix Learner within the PPN, which directly learn pair-wised relationships for pair proposal generation. Through extensive ablation and analysis, our approach significantly improves upon leveraging the segmenter solid baseline. Notably, our method achieves new state-of-the-art results on the PSG benchmark, with over 10\% absolute gains compared to PSGFormer. The code of this paper is publicly available at https://github.com/king159/Pair-Net.
Panoptic Scene Graph Generation
Jul 22, 2022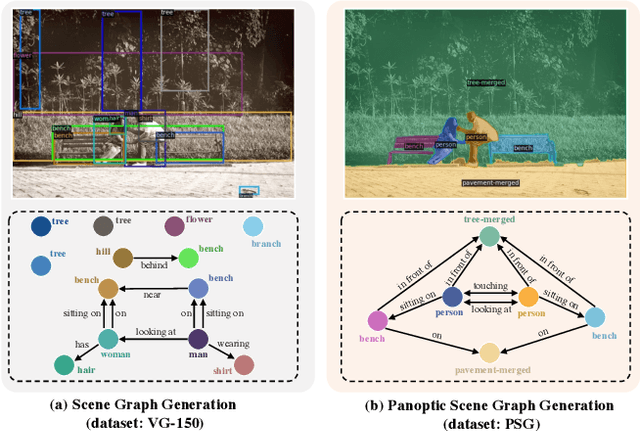
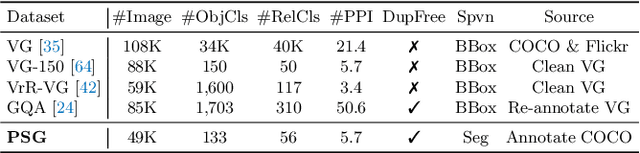
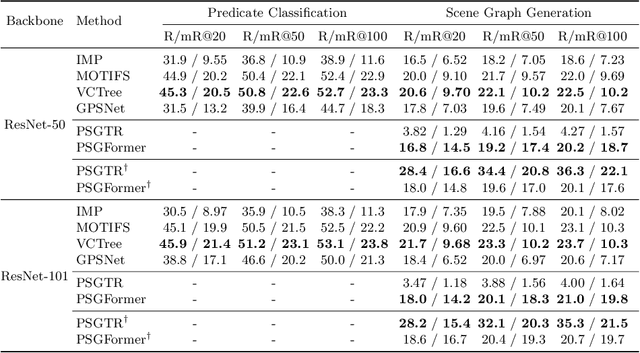
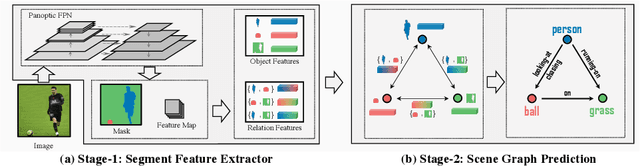
Existing research addresses scene graph generation (SGG) -- a critical technology for scene understanding in images -- from a detection perspective, i.e., objects are detected using bounding boxes followed by prediction of their pairwise relationships. We argue that such a paradigm causes several problems that impede the progress of the field. For instance, bounding box-based labels in current datasets usually contain redundant classes like hairs, and leave out background information that is crucial to the understanding of context. In this work, we introduce panoptic scene graph generation (PSG), a new problem task that requires the model to generate a more comprehensive scene graph representation based on panoptic segmentations rather than rigid bounding boxes. A high-quality PSG dataset, which contains 49k well-annotated overlapping images from COCO and Visual Genome, is created for the community to keep track of its progress. For benchmarking, we build four two-stage baselines, which are modified from classic methods in SGG, and two one-stage baselines called PSGTR and PSGFormer, which are based on the efficient Transformer-based detector, i.e., DETR. While PSGTR uses a set of queries to directly learn triplets, PSGFormer separately models the objects and relations in the form of queries from two Transformer decoders, followed by a prompting-like relation-object matching mechanism. In the end, we share insights on open challenges and future directions.