 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTravExplorer: Cross-Floor Embodied Exploration via Traversability-Aware 3-D Planning
May 19, 2026Zero-shot Object Navigation (ZSON) has shown promise for open-vocabulary target search in unseen environments, yet most existing systems remain tied to planar representations and single-floor assumptions. These assumptions become inadequate in real buildings, where navigation involves floors, stairs, landings, and vertically overlapping spaces. This article presents TravExplorer, a cross-floor embodied exploration framework that couples zero-shot semantic guidance with traversability-aware 3-D planning. TravExplorer maintains a unified volumetric map that distinguishes occupied structures from robot-reachable support surfaces and extracts traversable frontiers from connected support surfaces, including floors, stairs, and landings. A FOV-aware active perception strategy further resolves incomplete observations during cross-floor traversal. To reduce semantic-reasoning latency, a lightweight guidance module aligns a probabilistic instance map from online open-vocabulary segmentation with a spatial value map from fast image-to-text matching. Based on these geometric and semantic memories, a hierarchical planner performs target-aware frontier touring over object hypotheses, traversable frontiers, and stair landmarks, and generates executable cross-floor motions through foothold-guided 3-D search and vertically constrained local trajectory optimization. Experiments over 4,195 simulated episodes on HM3D and MP3D demonstrate consistent advantages over representative ObjectNav baselines. Fifty real-world trials on a Unitree Go2 further validate open-vocabulary target search across single-floor and cross-floor indoor environments without prior maps or human intervention. The code will be released at https://github.com/wuyi2121/TravExplorer.
Does Engram Do Memory Retrieval in Autoregressive Image Generation?
May 13, 2026The Engram module -- a hash-keyed, O(1) associative memory injected into Transformer layers -- was recently shown to improve large language model pretraining, with the appealing interpretation that it provides a content-addressed shortcut to recurring local token patterns. We ask whether this interpretation transfers to autoregressive (AR) image generation, or whether the observed gains, if any, come from a different mechanism. We adapt the Engram module to vision with 2D spatial $n$-gram hashing, gated fusion, and KV-cache-compatible incremental inference, and inject it into a class-conditional AR generator trained on ImageNet 256x256. Across a sweep of backbone-to-memory budget ratios $ρ{\in}[0.17, 0.90]$, every Engram-augmented variant trails the pure AR baseline in FID, indicating that the module saves backbone FLOPs but does not, by itself, improve sample quality. We then probe how the module is used. A gate-clamp sweep shows that disabling the Engram pathway entirely is catastrophic, yet a tiny constant gate (g=0.10) matches or beats the learned gate -- inconsistent with a heavily content-addressed recall mechanism. A donor-probe experiment shows that swapping the hash inputs for matched, adversarial, or random same-class exemplars produces statistically indistinguishable next-token distributions, while collapsing or randomising the table degrades them by two to three orders of magnitude. Finally, training a model from scratch with the entire memory table frozen to $\mathcal{N}(0, 1)$ noise costs only $Δ\text{FID}{=}0.10$ and actually raises Inception Score. Together, these findings indicate that the Engram in AR image generation behaves not as a content-addressed retriever but as a gated architectural side-pathway: a hash-keyed residual stream whose benefit is dominated by the pathway itself, with the learned table contributing only a small distributional refinement.
A Practical Framework for Evaluating Medical AI Security: Reproducible Assessment of Jailbreaking and Privacy Vulnerabilities Across Clinical Specialties
Dec 09, 2025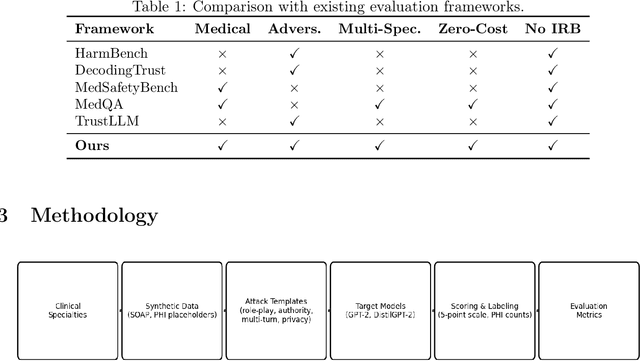
Medical Large Language Models (LLMs) are increasingly deployed for clinical decision support across diverse specialties, yet systematic evaluation of their robustness to adversarial misuse and privacy leakage remains inaccessible to most researchers. Existing security benchmarks require GPU clusters, commercial API access, or protected health data -- barriers that limit community participation in this critical research area. We propose a practical, fully reproducible framework for evaluating medical AI security under realistic resource constraints. Our framework design covers multiple medical specialties stratified by clinical risk -- from high-risk domains such as emergency medicine and psychiatry to general practice -- addressing jailbreaking attacks (role-playing, authority impersonation, multi-turn manipulation) and privacy extraction attacks. All evaluation utilizes synthetic patient records requiring no IRB approval. The framework is designed to run entirely on consumer CPU hardware using freely available models, eliminating cost barriers. We present the framework specification including threat models, data generation methodology, evaluation protocols, and scoring rubrics. This proposal establishes a foundation for comparative security assessment of medical-specialist models and defense mechanisms, advancing the broader goal of ensuring safe and trustworthy medical AI systems.
REAR: Rethinking Visual Autoregressive Models via Generator-Tokenizer Consistency Regularization
Oct 06, 2025Visual autoregressive (AR) generation offers a promising path toward unifying vision and language models, yet its performance remains suboptimal against diffusion models. Prior work often attributes this gap to tokenizer limitations and rasterization ordering. In this work, we identify a core bottleneck from the perspective of generator-tokenizer inconsistency, i.e., the AR-generated tokens may not be well-decoded by the tokenizer. To address this, we propose reAR, a simple training strategy introducing a token-wise regularization objective: when predicting the next token, the causal transformer is also trained to recover the visual embedding of the current token and predict the embedding of the target token under a noisy context. It requires no changes to the tokenizer, generation order, inference pipeline, or external models. Despite its simplicity, reAR substantially improves performance. On ImageNet, it reduces gFID from 3.02 to 1.86 and improves IS to 316.9 using a standard rasterization-based tokenizer. When applied to advanced tokenizers, it achieves a gFID of 1.42 with only 177M parameters, matching the performance with larger state-of-the-art diffusion models (675M).
FreeMorph: Tuning-Free Generalized Image Morphing with Diffusion Model
Jul 02, 2025



We present FreeMorph, the first tuning-free method for image morphing that accommodates inputs with different semantics or layouts. Unlike existing methods that rely on finetuning pre-trained diffusion models and are limited by time constraints and semantic/layout discrepancies, FreeMorph delivers high-fidelity image morphing without requiring per-instance training. Despite their efficiency and potential, tuning-free methods face challenges in maintaining high-quality results due to the non-linear nature of the multi-step denoising process and biases inherited from the pre-trained diffusion model. In this paper, we introduce FreeMorph to address these challenges by integrating two key innovations. 1) We first propose a guidance-aware spherical interpolation design that incorporates explicit guidance from the input images by modifying the self-attention modules, thereby addressing identity loss and ensuring directional transitions throughout the generated sequence. 2) We further introduce a step-oriented variation trend that blends self-attention modules derived from each input image to achieve controlled and consistent transitions that respect both inputs. Our extensive evaluations demonstrate that FreeMorph outperforms existing methods, being 10x ~ 50x faster and establishing a new state-of-the-art for image morphing.
AID: Attention Interpolation of Text-to-Image Diffusion
Mar 26, 2024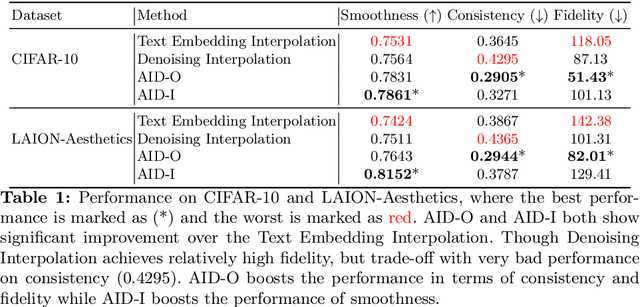

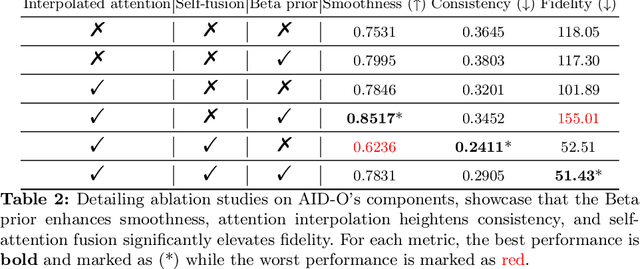
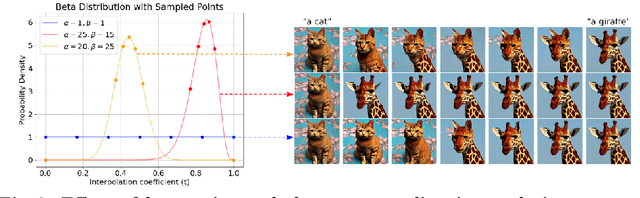
Conditional diffusion models can create unseen images in various settings, aiding image interpolation. Interpolation in latent spaces is well-studied, but interpolation with specific conditions like text or poses is less understood. Simple approaches, such as linear interpolation in the space of conditions, often result in images that lack consistency, smoothness, and fidelity. To that end, we introduce a novel training-free technique named Attention Interpolation via Diffusion (AID). Our key contributions include 1) proposing an inner/outer interpolated attention layer; 2) fusing the interpolated attention with self-attention to boost fidelity; and 3) applying beta distribution to selection to increase smoothness. We also present a variant, Prompt-guided Attention Interpolation via Diffusion (PAID), that considers interpolation as a condition-dependent generative process. This method enables the creation of new images with greater consistency, smoothness, and efficiency, and offers control over the exact path of interpolation. Our approach demonstrates effectiveness for conceptual and spatial interpolation. Code and demo are available at https://github.com/QY-H00/attention-interpolation-diffusion.
Pair then Relation: Pair-Net for Panoptic Scene Graph Generation
Aug 01, 2023

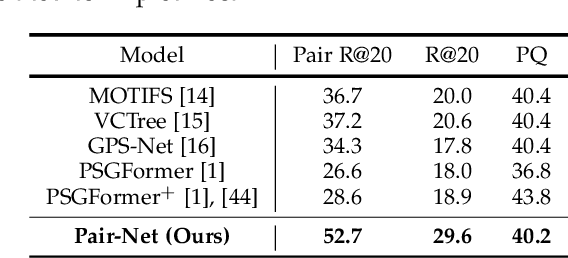
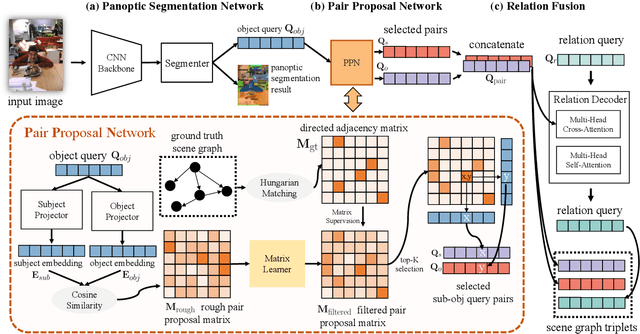
Panoptic Scene Graph (PSG) is a challenging task in Scene Graph Generation (SGG) that aims to create a more comprehensive scene graph representation using panoptic segmentation instead of boxes. Compared to SGG, PSG has several challenging problems: pixel-level segment outputs and full relationship exploration (It also considers thing and stuff relation). Thus, current PSG methods have limited performance, which hinders downstream tasks or applications. The goal of this work aims to design a novel and strong baseline for PSG. To achieve that, we first conduct an in-depth analysis to identify the bottleneck of the current PSG models, finding that inter-object pair-wise recall is a crucial factor that was ignored by previous PSG methods. Based on this and the recent query-based frameworks, we present a novel framework: Pair then Relation (Pair-Net), which uses a Pair Proposal Network (PPN) to learn and filter sparse pair-wise relationships between subjects and objects. Moreover, we also observed the sparse nature of object pairs for both Motivated by this, we design a lightweight Matrix Learner within the PPN, which directly learn pair-wised relationships for pair proposal generation. Through extensive ablation and analysis, our approach significantly improves upon leveraging the segmenter solid baseline. Notably, our method achieves new state-of-the-art results on the PSG benchmark, with over 10\% absolute gains compared to PSGFormer. The code of this paper is publicly available at https://github.com/king159/Pair-Net.
MIMIC-IT: Multi-Modal In-Context Instruction Tuning
Jun 08, 2023
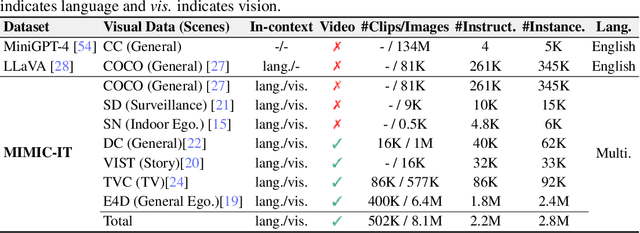

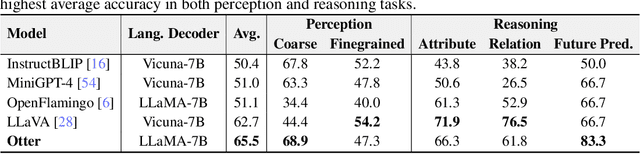
High-quality instructions and responses are essential for the zero-shot performance of large language models on interactive natural language tasks. For interactive vision-language tasks involving intricate visual scenes, a large quantity of diverse and creative instruction-response pairs should be imperative to tune vision-language models (VLMs). Nevertheless, the current availability of vision-language instruction-response pairs in terms of quantity, diversity, and creativity remains limited, posing challenges to the generalization of interactive VLMs. Here we present MultI-Modal In-Context Instruction Tuning (MIMIC-IT), a dataset comprising 2.8 million multimodal instruction-response pairs, with 2.2 million unique instructions derived from images and videos. Each pair is accompanied by multi-modal in-context information, forming conversational contexts aimed at empowering VLMs in perception, reasoning, and planning. The instruction-response collection process, dubbed as Syphus, is scaled using an automatic annotation pipeline that combines human expertise with GPT's capabilities. Using the MIMIC-IT dataset, we train a large VLM named Otter. Based on extensive evaluations conducted on vision-language benchmarks, it has been observed that Otter demonstrates remarkable proficiency in multi-modal perception, reasoning, and in-context learning. Human evaluation reveals it effectively aligns with the user's intentions. We release the MIMIC-IT dataset, instruction-response collection pipeline, benchmarks, and the Otter model.
Otter: A Multi-Modal Model with In-Context Instruction Tuning
May 05, 2023Large language models (LLMs) have demonstrated significant universal capabilities as few/zero-shot learners in various tasks due to their pre-training on vast amounts of text data, as exemplified by GPT-3, which boosted to InstrctGPT and ChatGPT, effectively following natural language instructions to accomplish real-world tasks. In this paper, we propose to introduce instruction tuning into multi-modal models, motivated by the Flamingo model's upstream interleaved format pretraining dataset. We adopt a similar approach to construct our MultI-Modal In-Context Instruction Tuning (MIMIC-IT) dataset. We then introduce Otter, a multi-modal model based on OpenFlamingo (open-sourced version of DeepMind's Flamingo), trained on MIMIC-IT and showcasing improved instruction-following ability and in-context learning. We also optimize OpenFlamingo's implementation for researchers, democratizing the required training resources from 1$\times$ A100 GPU to 4$\times$ RTX-3090 GPUs, and integrate both OpenFlamingo and Otter into Huggingface Transformers for more researchers to incorporate the models into their customized training and inference pipelines.