 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKTV: Keyframes and Key Tokens Selection for Efficient Training-Free Video LLMs
Feb 03, 2026Training-free video understanding leverages the strong image comprehension capabilities of pre-trained vision language models (VLMs) by treating a video as a sequence of static frames, thus obviating the need for costly video-specific training. However, this paradigm often suffers from severe visual redundancy and high computational overhead, especially when processing long videos. Crucially, existing keyframe selection strategies, especially those based on CLIP similarity, are prone to biases and may inadvertently overlook critical frames, resulting in suboptimal video comprehension. To address these significant challenges, we propose \textbf{KTV}, a novel two-stage framework for efficient and effective training-free video understanding. In the first stage, KTV performs question-agnostic keyframe selection by clustering frame-level visual features, yielding a compact, diverse, and representative subset of frames that mitigates temporal redundancy. In the second stage, KTV applies key visual token selection, pruning redundant or less informative tokens from each selected keyframe based on token importance and redundancy, which significantly reduces the number of tokens fed into the LLM. Extensive experiments on the Multiple-Choice VideoQA task demonstrate that KTV outperforms state-of-the-art training-free baselines while using significantly fewer visual tokens, \emph{e.g.}, only 504 visual tokens for a 60-min video with 10800 frames, achieving $44.8\%$ accuracy on the MLVU-Test benchmark. In particular, KTV also exceeds several training-based approaches on certain benchmarks.
Decoupling Template Bias in CLIP: Harnessing Empty Prompts for Enhanced Few-Shot Learning
Dec 10, 2025The Contrastive Language-Image Pre-Training (CLIP) model excels in few-shot learning by aligning visual and textual representations. Our study shows that template-sample similarity (TSS), defined as the resemblance between a text template and an image sample, introduces bias. This bias leads the model to rely on template proximity rather than true sample-to-category alignment, reducing both accuracy and robustness in classification. We present a framework that uses empty prompts, textual inputs that convey the idea of "emptiness" without category information. These prompts capture unbiased template features and offset TSS bias. The framework employs two stages. During pre-training, empty prompts reveal and reduce template-induced bias within the CLIP encoder. During few-shot fine-tuning, a bias calibration loss enforces correct alignment between images and their categories, ensuring the model focuses on relevant visual cues. Experiments across multiple benchmarks demonstrate that our template correction method significantly reduces performance fluctuations caused by TSS, yielding higher classification accuracy and stronger robustness. The repository of this project is available at https://github.com/zhenyuZ-HUST/Decoupling-Template-Bias-in-CLIP.
Start Small, Think Big: Curriculum-based Relative Policy Optimization for Visual Grounding
Nov 17, 2025Chain-of-Thought (CoT) prompting has recently shown significant promise across various NLP and computer vision tasks by explicitly generating intermediate reasoning steps. However, we find that reinforcement learning (RL)-based fine-tuned CoT reasoning can paradoxically degrade performance in Visual Grounding tasks, particularly as CoT outputs become lengthy or complex. Additionally, our analysis reveals that increased dataset size does not always enhance performance due to varying data complexities. Motivated by these findings, we propose Curriculum-based Relative Policy Optimization (CuRPO), a novel training strategy that leverages CoT length and generalized Intersection over Union (gIoU) rewards as complexity indicators to progressively structure training data from simpler to more challenging examples. Extensive experiments on RefCOCO, RefCOCO+, RefCOCOg, and LISA datasets demonstrate the effectiveness of our approach. CuRPO consistently outperforms existing methods, including Visual-RFT, with notable improvements of up to +12.52 mAP on RefCOCO. Moreover, CuRPO exhibits exceptional efficiency and robustness, delivering strong localization performance even in few-shot learning scenarios, particularly benefiting tasks characterized by ambiguous and intricate textual descriptions.The code is released on https://github.com/qyoung-yan/CuRPO.
Adapter Naturally Serves as Decoupler for Cross-Domain Few-Shot Semantic Segmentation
Jun 09, 2025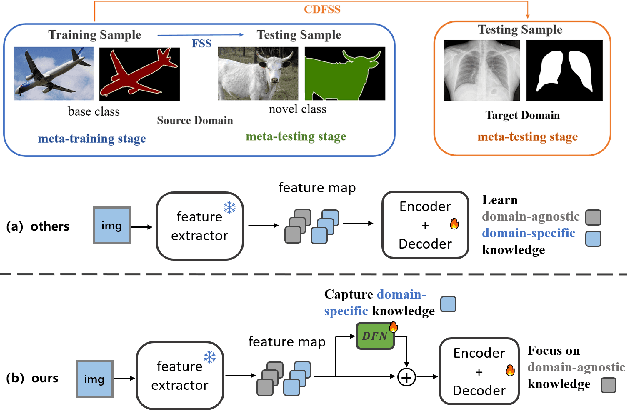
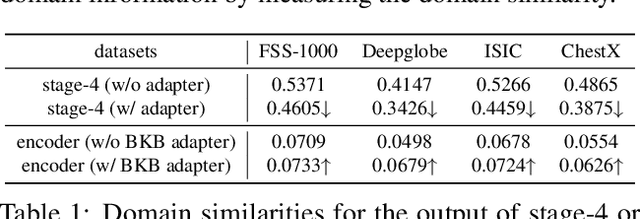
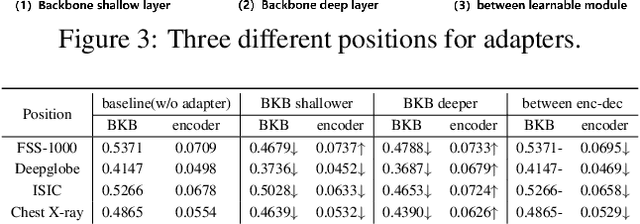
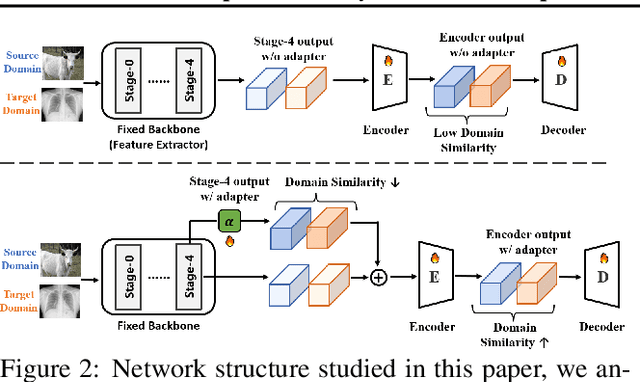
Cross-domain few-shot segmentation (CD-FSS) is proposed to pre-train the model on a source-domain dataset with sufficient samples, and then transfer the model to target-domain datasets where only a few samples are available for efficient fine-tuning. There are majorly two challenges in this task: (1) the domain gap and (2) fine-tuning with scarce data. To solve these challenges, we revisit the adapter-based methods, and discover an intriguing insight not explored in previous works: the adapter not only helps the fine-tuning of downstream tasks but also naturally serves as a domain information decoupler. Then, we delve into this finding for an interpretation, and find the model's inherent structure could lead to a natural decoupling of domain information. Building upon this insight, we propose the Domain Feature Navigator (DFN), which is a structure-based decoupler instead of loss-based ones like current works, to capture domain-specific information, thereby directing the model's attention towards domain-agnostic knowledge. Moreover, to prevent the potential excessive overfitting of DFN during the source-domain training, we further design the SAM-SVN method to constrain DFN from learning sample-specific knowledge. On target domains, we freeze the model and fine-tune the DFN to learn target-specific knowledge specific. Extensive experiments demonstrate that our method surpasses the state-of-the-art method in CD-FSS significantly by 2.69% and 4.68% MIoU in 1-shot and 5-shot scenarios, respectively.
Training-free Anomaly Event Detection via LLM-guided Symbolic Pattern Discovery
Feb 09, 2025



Anomaly event detection plays a crucial role in various real-world applications. However, current approaches predominantly rely on supervised learning, which faces significant challenges: the requirement for extensive labeled training data and lack of interpretability in decision-making processes. To address these limitations, we present a training-free framework that integrates open-set object detection with symbolic regression, powered by Large Language Models (LLMs) for efficient symbolic pattern discovery. The LLMs guide the symbolic reasoning process, establishing logical relationships between detected entities. Through extensive experiments across multiple domains, our framework demonstrates several key advantages: (1) achieving superior detection accuracy through direct reasoning without any training process; (2) providing highly interpretable logical expressions that are readily comprehensible to humans; and (3) requiring minimal annotation effort - approximately 1% of the data needed by traditional training-based methods.To facilitate comprehensive evaluation and future research, we introduce two datasets: a large-scale private dataset containing over 110,000 annotated images covering various anomaly scenarios including construction site safety violations, illegal fishing activities, and industrial hazards, along with a public benchmark dataset of 5,000 samples with detailed anomaly event annotations. Code is available at here.
MICM: Rethinking Unsupervised Pretraining for Enhanced Few-shot Learning
Aug 23, 2024



Humans exhibit a remarkable ability to learn quickly from a limited number of labeled samples, a capability that starkly contrasts with that of current machine learning systems. Unsupervised Few-Shot Learning (U-FSL) seeks to bridge this divide by reducing reliance on annotated datasets during initial training phases. In this work, we first quantitatively assess the impacts of Masked Image Modeling (MIM) and Contrastive Learning (CL) on few-shot learning tasks. Our findings highlight the respective limitations of MIM and CL in terms of discriminative and generalization abilities, which contribute to their underperformance in U-FSL contexts. To address these trade-offs between generalization and discriminability in unsupervised pretraining, we introduce a novel paradigm named Masked Image Contrastive Modeling (MICM). MICM creatively combines the targeted object learning strength of CL with the generalized visual feature learning capability of MIM, significantly enhancing its efficacy in downstream few-shot learning inference. Extensive experimental analyses confirm the advantages of MICM, demonstrating significant improvements in both generalization and discrimination capabilities for few-shot learning. Our comprehensive quantitative evaluations further substantiate the superiority of MICM, showing that our two-stage U-FSL framework based on MICM markedly outperforms existing leading baselines.
Learning Unknowns from Unknowns: Diversified Negative Prototypes Generator for Few-Shot Open-Set Recognition
Aug 23, 2024



Few-shot open-set recognition (FSOR) is a challenging task that requires a model to recognize known classes and identify unknown classes with limited labeled data. Existing approaches, particularly Negative-Prototype-Based methods, generate negative prototypes based solely on known class data. However, as the unknown space is infinite while the known space is limited, these methods suffer from limited representation capability. To address this limitation, we propose a novel approach, termed \textbf{D}iversified \textbf{N}egative \textbf{P}rototypes \textbf{G}enerator (DNPG), which adopts the principle of "learning unknowns from unknowns." Our method leverages the unknown space information learned from base classes to generate more representative negative prototypes for novel classes. During the pre-training phase, we learn the unknown space representation of the base classes. This representation, along with inter-class relationships, is then utilized in the meta-learning process to construct negative prototypes for novel classes. To prevent prototype collapse and ensure adaptability to varying data compositions, we introduce the Swap Alignment (SA) module. Our DNPG model, by learning from the unknown space, generates negative prototypes that cover a broader unknown space, thereby achieving state-of-the-art performance on three standard FSOR datasets.
Adaptive Discovering and Merging for Incremental Novel Class Discovery
Mar 06, 2024One important desideratum of lifelong learning aims to discover novel classes from unlabelled data in a continuous manner. The central challenge is twofold: discovering and learning novel classes while mitigating the issue of catastrophic forgetting of established knowledge. To this end, we introduce a new paradigm called Adaptive Discovering and Merging (ADM) to discover novel categories adaptively in the incremental stage and integrate novel knowledge into the model without affecting the original knowledge. To discover novel classes adaptively, we decouple representation learning and novel class discovery, and use Triple Comparison (TC) and Probability Regularization (PR) to constrain the probability discrepancy and diversity for adaptive category assignment. To merge the learned novel knowledge adaptively, we propose a hybrid structure with base and novel branches named Adaptive Model Merging (AMM), which reduces the interference of the novel branch on the old classes to preserve the previous knowledge, and merges the novel branch to the base model without performance loss and parameter growth. Extensive experiments on several datasets show that ADM significantly outperforms existing class-incremental Novel Class Discovery (class-iNCD) approaches. Moreover, our AMM also benefits the class-incremental Learning (class-IL) task by alleviating the catastrophic forgetting problem.
AutoAgents: A Framework for Automatic Agent Generation
Oct 15, 2023



Large language models (LLMs) have enabled remarkable advances in automated task-solving with multi-agent systems. However, most existing LLM-based multi-agent approaches rely on predefined agents to handle simple tasks, limiting the adaptability of multi-agent collaboration to different scenarios. Therefore, we introduce AutoAgents, an innovative framework that adaptively generates and coordinates multiple specialized agents to build an AI team according to different tasks. Specifically, AutoAgents couples the relationship between tasks and roles by dynamically generating multiple required agents based on task content and planning solutions for the current task based on the generated expert agents. Multiple specialized agents collaborate with each other to efficiently accomplish tasks. Concurrently, an observer role is incorporated into the framework to reflect on the designated plans and agents' responses and improve upon them. Our experiments on various benchmarks demonstrate that AutoAgents generates more coherent and accurate solutions than the existing multi-agent methods. This underscores the significance of assigning different roles to different tasks and of team cooperation, offering new perspectives for tackling complex tasks. The repository of this project is available at https://github.com/Link-AGI/AutoAgents.
LLaSM: Large Language and Speech Model
Sep 16, 2023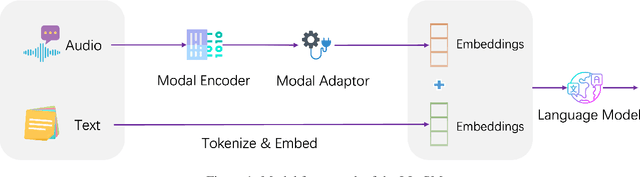
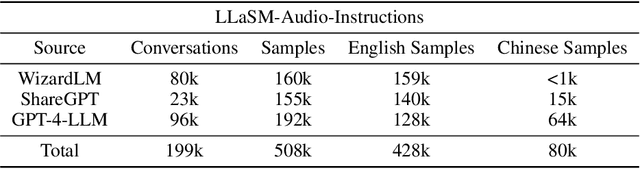
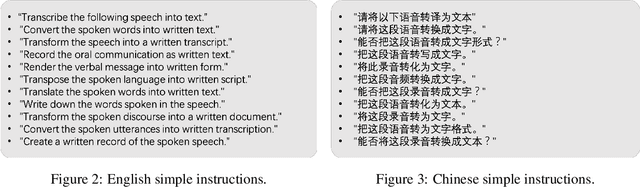

Multi-modal large language models have garnered significant interest recently. Though, most of the works focus on vision-language multi-modal models providing strong capabilities in following vision-and-language instructions. However, we claim that speech is also an important modality through which humans interact with the world. Hence, it is crucial for a general-purpose assistant to be able to follow multi-modal speech-and-language instructions. In this work, we propose Large Language and Speech Model (LLaSM). LLaSM is an end-to-end trained large multi-modal speech-language model with cross-modal conversational abilities, capable of following speech-and-language instructions. Our early experiments show that LLaSM demonstrates a more convenient and natural way for humans to interact with artificial intelligence. Specifically, we also release a large Speech Instruction Following dataset LLaSM-Audio-Instructions. Code and demo are available at https://github.com/LinkSoul-AI/LLaSM and https://huggingface.co/spaces/LinkSoul/LLaSM. The LLaSM-Audio-Instructions dataset is available at https://huggingface.co/datasets/LinkSoul/LLaSM-Audio-Instructions.