 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
Promptable Anomaly Segmentation with SAM Through Self-Perception Tuning
Nov 26, 2024



Segment Anything Model (SAM) has made great progress in anomaly segmentation tasks due to its impressive generalization ability. However, existing methods that directly apply SAM through prompting often overlook the domain shift issue, where SAM performs well on natural images but struggles in industrial scenarios. Parameter-Efficient Fine-Tuning (PEFT) offers a promising solution, but it may yield suboptimal performance by not adequately addressing the perception challenges during adaptation to anomaly images. In this paper, we propose a novel Self-Perceptinon Tuning (SPT) method, aiming to enhance SAM's perception capability for anomaly segmentation. The SPT method incorporates a self-drafting tuning strategy, which generates an initial coarse draft of the anomaly mask, followed by a refinement process. Additionally, a visual-relation-aware adapter is introduced to improve the perception of discriminative relational information for mask generation. Extensive experimental results on several benchmark datasets demonstrate that our SPT method can significantly outperform baseline methods, validating its effectiveness. Models and codes will be available online.
A Differential Smoothness-based Compact-Dynamic Graph Convolutional Network for Spatiotemporal Signal Recovery
Aug 06, 2024High quality spatiotemporal signal is vitally important for real application scenarios like energy management, traffic planning and cyber security. Due to the uncontrollable factors like abrupt sensors breakdown or communication fault, the spatiotemporal signal collected by sensors is always incomplete. A dynamic graph convolutional network (DGCN) is effective for processing spatiotemporal signal recovery. However, it adopts a static GCN and a sequence neural network to explore the spatial and temporal patterns, separately. Such a separated two-step processing is loose spatiotemporal, thereby failing to capture the complex inner spatiotemporal correlation. To address this issue, this paper proposes a Compact-Dynamic Graph Convolutional Network (CDGCN) for spatiotemporal signal recovery with the following two-fold ideas: a) leveraging the tensor M-product to build a unified tensor graph convolution framework, which considers both spatial and temporal patterns simultaneously; and b) constructing a differential smoothness-based objective function to reduce the noise interference in spatiotemporal signal, thereby further improve the recovery accuracy. Experiments on real-world spatiotemporal datasets demonstrate that the proposed CDGCN significantly outperforms the state-of-the-art models in terms of recovery accuracy.
Large-scale Multi-Modal Pre-trained Models: A Comprehensive Survey
Feb 20, 2023With the urgent demand for generalized deep models, many pre-trained big models are proposed, such as BERT, ViT, GPT, etc. Inspired by the success of these models in single domains (like computer vision and natural language processing), the multi-modal pre-trained big models have also drawn more and more attention in recent years. In this work, we give a comprehensive survey of these models and hope this paper could provide new insights and helps fresh researchers to track the most cutting-edge works. Specifically, we firstly introduce the background of multi-modal pre-training by reviewing the conventional deep learning, pre-training works in natural language process, computer vision, and speech. Then, we introduce the task definition, key challenges, and advantages of multi-modal pre-training models (MM-PTMs), and discuss the MM-PTMs with a focus on data, objectives, network architectures, and knowledge enhanced pre-training. After that, we introduce the downstream tasks used for the validation of large-scale MM-PTMs, including generative, classification, and regression tasks. We also give visualization and analysis of the model parameters and results on representative downstream tasks. Finally, we point out possible research directions for this topic that may benefit future works. In addition, we maintain a continuously updated paper list for large-scale pre-trained multi-modal big models: https://github.com/wangxiao5791509/MultiModal_BigModels_Survey
FEAFA+: An Extended Well-Annotated Dataset for Facial Expression Analysis and 3D Facial Animation
Nov 04, 2021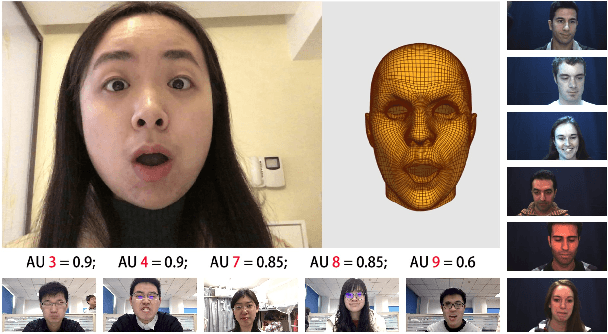
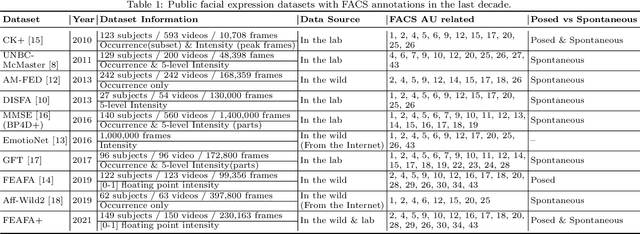
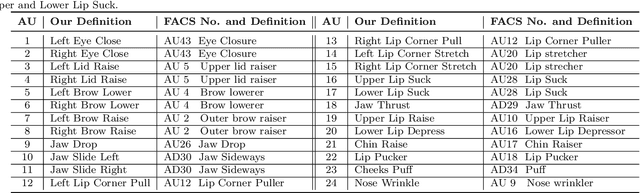
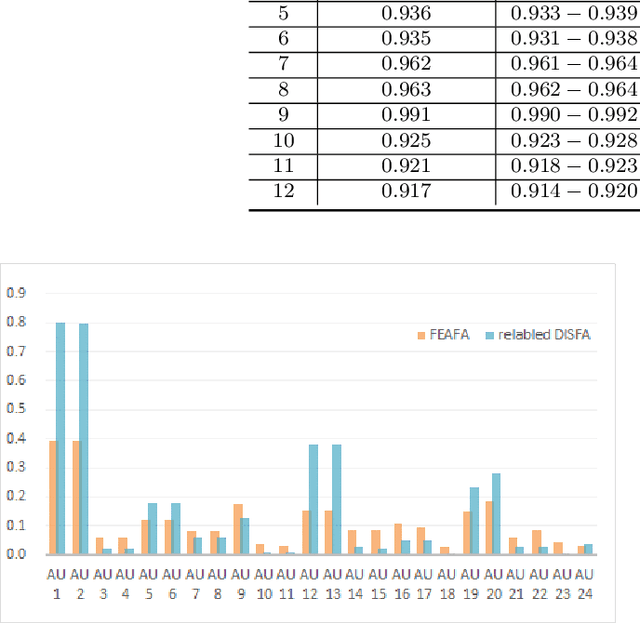
Nearly all existing Facial Action Coding System-based datasets that include facial action unit (AU) intensity information annotate the intensity values hierarchically using A--E levels. However, facial expressions change continuously and shift smoothly from one state to another. Therefore, it is more effective to regress the intensity value of local facial AUs to represent whole facial expression changes, particularly in the fields of expression transfer and facial animation. We introduce an extension of FEAFA in combination with the relabeled DISFA database, which is available at https://www.iiplab.net/feafa+/ now. Extended FEAFA (FEAFA+) includes 150 video sequences from FEAFA and DISFA, with a total of 230,184 frames being manually annotated on floating-point intensity value of 24 redefined AUs using the Expression Quantitative Tool. We also list crude numerical results for posed and spontaneous subsets and provide a baseline comparison for the AU intensity regression task.
FEAFA: A Well-Annotated Dataset for Facial Expression Analysis and 3D Facial Animation
Apr 02, 2019
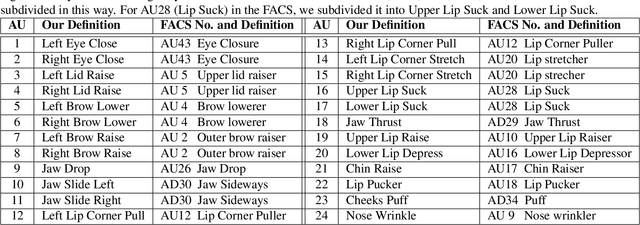
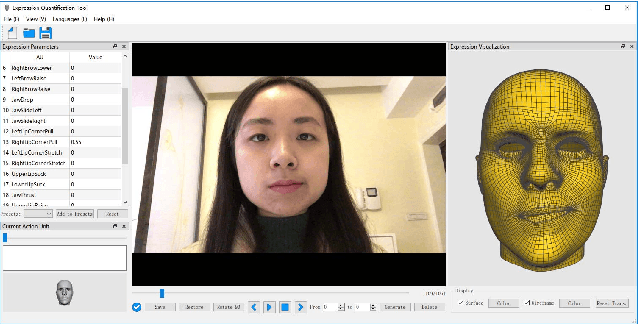
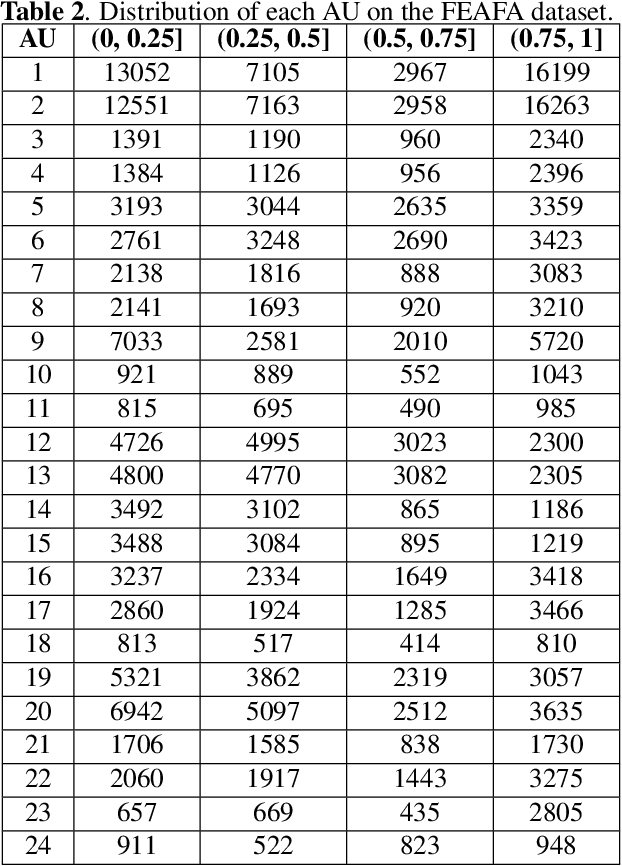
Facial expression analysis based on machine learning requires large number of well-annotated data to reflect different changes in facial motion. Publicly available datasets truly help to accelerate research in this area by providing a benchmark resource, but all of these datasets, to the best of our knowledge, are limited to rough annotations for action units, including only their absence, presence, or a five-level intensity according to the Facial Action Coding System. To meet the need for videos labeled in great detail, we present a well-annotated dataset named FEAFA for Facial Expression Analysis and 3D Facial Animation. One hundred and twenty-two participants, including children, young adults and elderly people, were recorded in real-world conditions. In addition, 99,356 frames were manually labeled using Expression Quantitative Tool developed by us to quantify 9 symmetrical FACS action units, 10 asymmetrical (unilateral) FACS action units, 2 symmetrical FACS action descriptors and 2 asymmetrical FACS action descriptors, and each action unit or action descriptor is well-annotated with a floating point number between 0 and 1. To provide a baseline for use in future research, a benchmark for the regression of action unit values based on Convolutional Neural Networks are presented. We also demonstrate the potential of our FEAFA dataset for 3D facial animation. Almost all state-of-the-art algorithms for facial animation are achieved based on 3D face reconstruction. We hence propose a novel method that drives virtual characters only based on action unit value regression of the 2D video frames of source actors.