 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptable Anomaly Segmentation with SAM Through Self-Perception Tuning
Nov 26, 2024



Segment Anything Model (SAM) has made great progress in anomaly segmentation tasks due to its impressive generalization ability. However, existing methods that directly apply SAM through prompting often overlook the domain shift issue, where SAM performs well on natural images but struggles in industrial scenarios. Parameter-Efficient Fine-Tuning (PEFT) offers a promising solution, but it may yield suboptimal performance by not adequately addressing the perception challenges during adaptation to anomaly images. In this paper, we propose a novel Self-Perceptinon Tuning (SPT) method, aiming to enhance SAM's perception capability for anomaly segmentation. The SPT method incorporates a self-drafting tuning strategy, which generates an initial coarse draft of the anomaly mask, followed by a refinement process. Additionally, a visual-relation-aware adapter is introduced to improve the perception of discriminative relational information for mask generation. Extensive experimental results on several benchmark datasets demonstrate that our SPT method can significantly outperform baseline methods, validating its effectiveness. Models and codes will be available online.
Deep Residual Networks with a Fully Connected Recon-struction Layer for Single Image Super-Resolution
May 24, 2018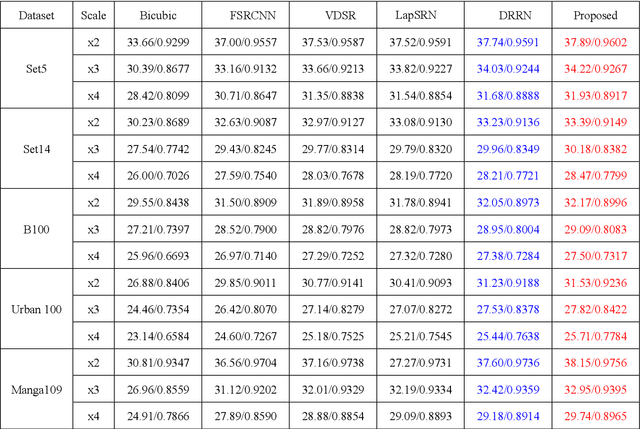
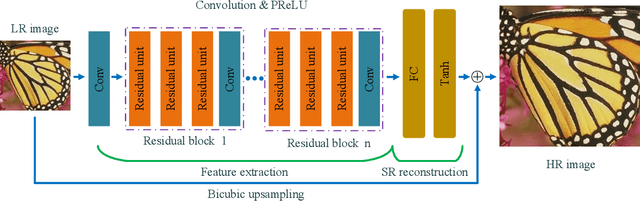
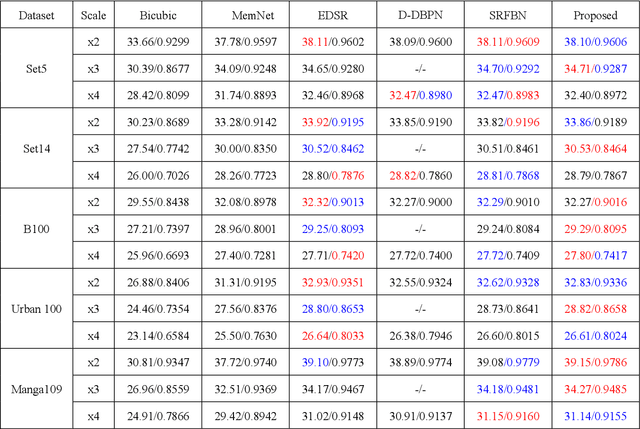
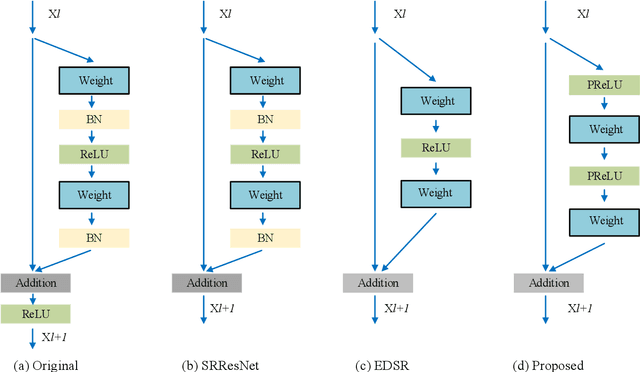
Recently, deep neural networks have achieved impressive performance in terms of both reconstruction accuracy and efficiency for single image super-resolution (SISR). However, the network model of these methods is a fully convolutional neural network, which is limit to exploit contextual information over the global region of the input image. In this paper, we discuss a new SR architecture where features are extracted in the low-resolution (LR) space, and then we use a fully connected layer which learns an array of upsampling weights to reconstruct the desired high-resolution (HR) image from the final LR features. By doing so, we effectively exploit global context information over the input image region, whilst maintaining the low computational complexity for the overall SR operation. In addition, we introduce an edge difference constraint into our loss function to pre-serve edges and texture structures. Extensive experiments validate that our meth-od outperforms the existing state-of-the-art methods
Deep Inception-Residual Laplacian Pyramid Networks for Accurate Single Image Super-Resolution
Nov 15, 2017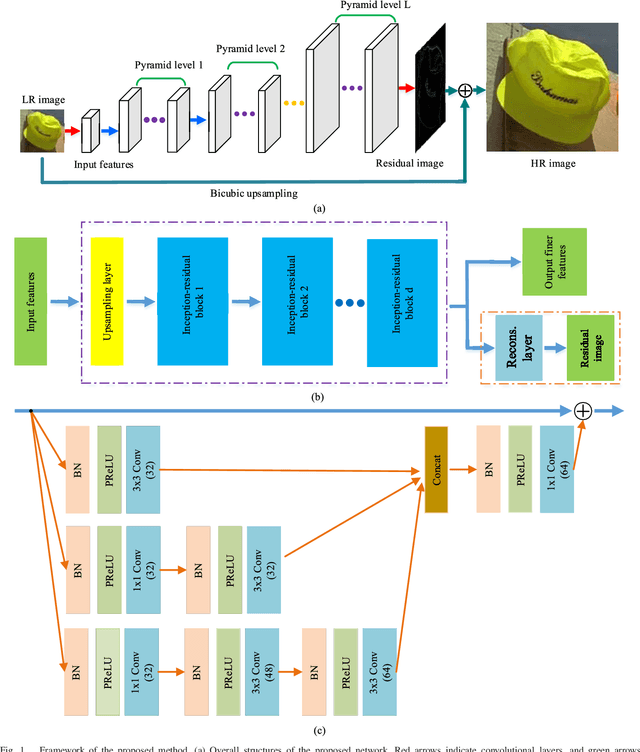



With exploiting contextual information over large image regions in an efficient way, the deep convolutional neural network has shown an impressive performance for single image super-resolution (SR). In this paper, we propose a deep convolutional network by cascading the well-designed inception-residual blocks within the deep Laplacian pyramid framework to progressively restore the missing high-frequency details of high-resolution (HR) images. By optimizing our network structure, the trainable depth of the proposed network gains a significant improvement, which in turn improves super-resolving accuracy. With our network depth increasing, however, the saturation and degradation of training accuracy continues to be a critical problem. As regard to this, we propose an effective two-stage training strategy, in which we firstly use images downsampled from the ground-truth HR images as the optimal objective to train the inception-residual blocks in each pyramid level with an extremely high learning rate enabled by gradient clipping, and then the ground-truth HR images are used to fine-tune all the pre-trained inception-residual blocks for obtaining the final SR model. Furthermore, we present a new loss function operating in both image space and local rank space to optimize our network for exploiting the contextual information among different output components. Extensive experiments on benchmark datasets validate that the proposed method outperforms existing state-of-the-art SR methods in terms of the objective evaluation as well as the visual quality.