 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Residual Networks with a Fully Connected Recon-struction Layer for Single Image Super-Resolution
Paper and Code
May 24, 2018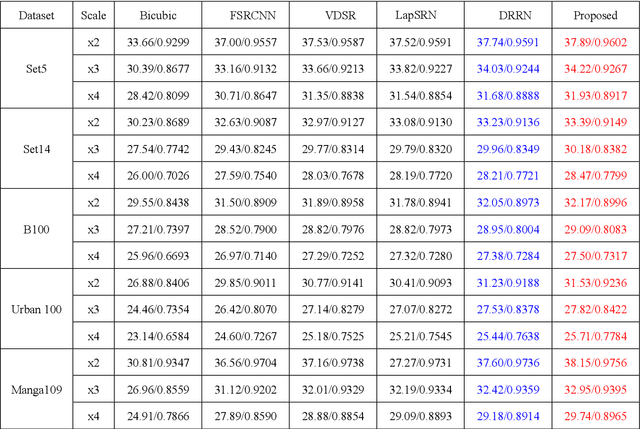
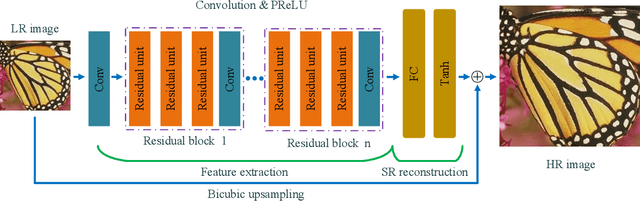
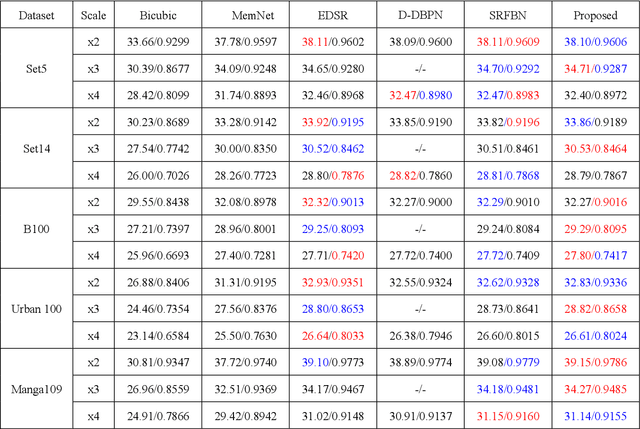
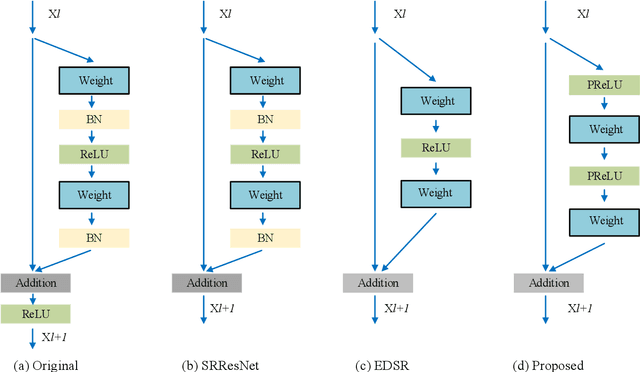
Recently, deep neural networks have achieved impressive performance in terms of both reconstruction accuracy and efficiency for single image super-resolution (SISR). However, the network model of these methods is a fully convolutional neural network, which is limit to exploit contextual information over the global region of the input image. In this paper, we discuss a new SR architecture where features are extracted in the low-resolution (LR) space, and then we use a fully connected layer which learns an array of upsampling weights to reconstruct the desired high-resolution (HR) image from the final LR features. By doing so, we effectively exploit global context information over the input image region, whilst maintaining the low computational complexity for the overall SR operation. In addition, we introduce an edge difference constraint into our loss function to pre-serve edges and texture structures. Extensive experiments validate that our meth-od outperforms the existing state-of-the-art methods