 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpend Search Where It Pays: Value-Guided Structured Sampling and Optimization for Generative Recommendation
Feb 12, 2026Generative recommendation via autoregressive models has unified retrieval and ranking into a single conditional generation framework. However, fine-tuning these models with Reinforcement Learning (RL) often suffers from a fundamental probability-reward mismatch. Conventional likelihood-dominated decoding (e.g., beam search) exhibits a myopic bias toward locally probable prefixes, which causes two critical failures: (1) insufficient exploration, where high-reward items in low-probability branches are prematurely pruned and rarely sampled, and (2) advantage compression, where trajectories sharing high-probability prefixes receive highly correlated rewards with low within-group variance, yielding a weak comparative signal for RL. To address these challenges, we propose V-STAR, a Value-guided Sampling and Tree-structured Advantage Reinforcement framework. V-STAR forms a self-evolving loop via two synergistic components. First, a Value-Guided Efficient Decoding (VED) is developed to identify decisive nodes and selectively deepen high-potential prefixes. This improves exploration efficiency without exhaustive tree search. Second, we propose Sibling-GRPO, which exploits the induced tree topology to compute sibling-relative advantages and concentrates learning signals on decisive branching decisions. Extensive experiments on both offline and online datasets demonstrate that V-STAR outperforms state-of-the-art baselines, delivering superior accuracy and candidate-set diversity under strict latency constraints.
S-GRec: Personalized Semantic-Aware Generative Recommendation with Asymmetric Advantage
Feb 12, 2026Generative recommendation models sequence generation to produce items end-to-end, but training from behavioral logs often provides weak supervision on underlying user intent. Although Large Language Models (LLMs) offer rich semantic priors that could supply such supervision, direct adoption in industrial recommendation is hindered by two obstacles: semantic signals can conflict with platform business objectives, and LLM inference is prohibitively expensive at scale. This paper presents S-GRec, a semantic-aware framework that decouples an online lightweight generator from an offline LLM-based semantic judge for train-time supervision. S-GRec introduces a two-stage Personalized Semantic Judge (PSJ) that produces interpretable aspect evidence and learns user-conditional aggregation from pairwise feedback, yielding stable semantic rewards. To prevent semantic supervision from deviating from business goals, Asymmetric Advantage Policy Optimization (A2PO) anchors optimization on business rewards (e.g., eCPM) and injects semantic advantages only when they are consistent. Extensive experiments on public benchmarks and a large-scale production system validate both effectiveness and scalability, including statistically significant gains in CTR and a 1.19\% lift in GMV in online A/B tests, without requiring real-time LLM inference.
Adaptive Discovering and Merging for Incremental Novel Class Discovery
Mar 06, 2024One important desideratum of lifelong learning aims to discover novel classes from unlabelled data in a continuous manner. The central challenge is twofold: discovering and learning novel classes while mitigating the issue of catastrophic forgetting of established knowledge. To this end, we introduce a new paradigm called Adaptive Discovering and Merging (ADM) to discover novel categories adaptively in the incremental stage and integrate novel knowledge into the model without affecting the original knowledge. To discover novel classes adaptively, we decouple representation learning and novel class discovery, and use Triple Comparison (TC) and Probability Regularization (PR) to constrain the probability discrepancy and diversity for adaptive category assignment. To merge the learned novel knowledge adaptively, we propose a hybrid structure with base and novel branches named Adaptive Model Merging (AMM), which reduces the interference of the novel branch on the old classes to preserve the previous knowledge, and merges the novel branch to the base model without performance loss and parameter growth. Extensive experiments on several datasets show that ADM significantly outperforms existing class-incremental Novel Class Discovery (class-iNCD) approaches. Moreover, our AMM also benefits the class-incremental Learning (class-IL) task by alleviating the catastrophic forgetting problem.
Domain Adaptive Attention Model for Unsupervised Cross-Domain Person Re-Identification
May 25, 2019
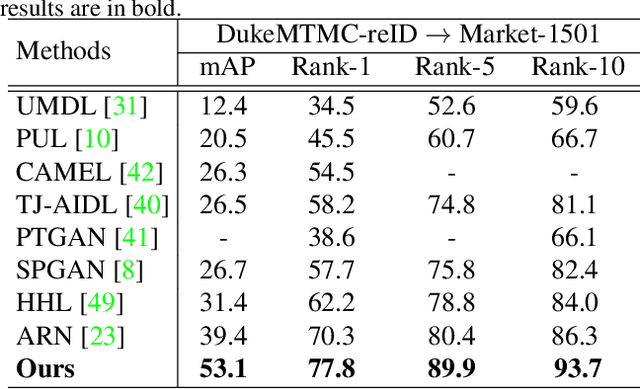
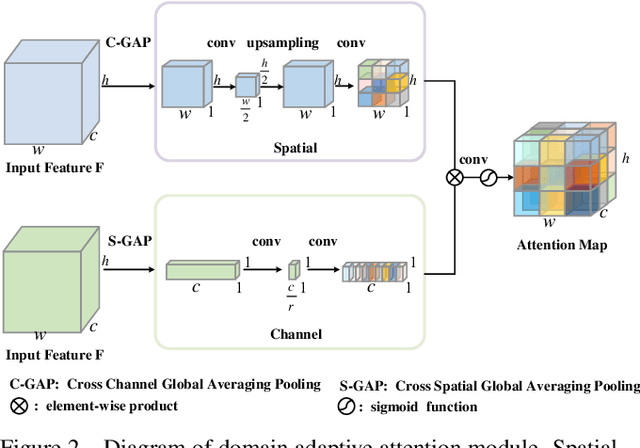
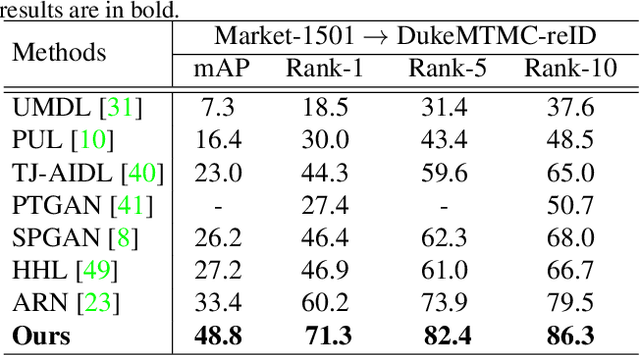
Person re-identification (Re-ID) across multiple datasets is a challenging yet important task due to the possibly large distinctions between different datasets and the lack of training samples in practical applications. This work proposes a novel unsupervised domain adaption framework which transfers discriminative representations from the labeled source domain (dataset) to the unlabeled target domain (dataset). We propose to formulate the domain adaption task as an one-class classification problem with a novel domain similarity loss. Given the feature map of any image from a backbone network, a novel domain adaptive attention model (DAAM) first automatically learns to separate the feature map of an image to a domain-shared feature (DSH) map and a domain-specific feature (DSP) map simultaneously. Specially, the residual attention mechanism is designed to model DSP feature map for avoiding negative transfer. Then, a DSH branch and a DSP branch are introduced to learn DSH and DSP feature maps respectively. To reduce domain divergence caused by that the source and target datasets are collected from different environments, we force to project the DSH feature maps from different domains to a new nominal domain, and a novel domain similarity loss is proposed based on one-class classification. In addition, a novel unsupervised person Re-ID loss is proposed to take full use of unlabeled target data. Extensive experiments on the Market-1501 and DukeMTMC-reID benchmarks demonstrate state-of-the-art performance of the proposed method. Code will be released to facilitate further studies on the cross-domain person re-identification task.