 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaSM: Large Language and Speech Model
Sep 16, 2023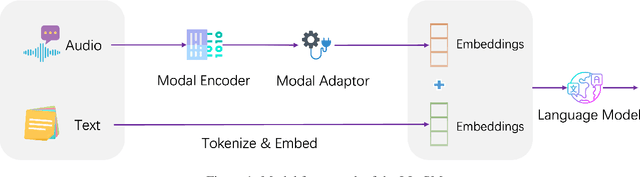
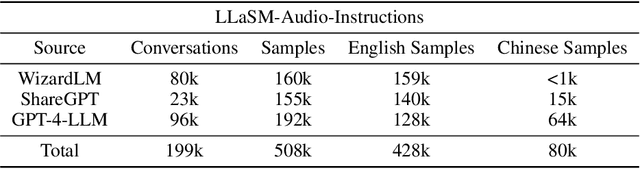
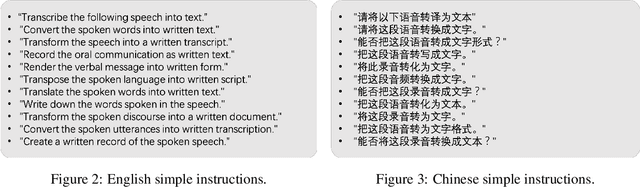

Multi-modal large language models have garnered significant interest recently. Though, most of the works focus on vision-language multi-modal models providing strong capabilities in following vision-and-language instructions. However, we claim that speech is also an important modality through which humans interact with the world. Hence, it is crucial for a general-purpose assistant to be able to follow multi-modal speech-and-language instructions. In this work, we propose Large Language and Speech Model (LLaSM). LLaSM is an end-to-end trained large multi-modal speech-language model with cross-modal conversational abilities, capable of following speech-and-language instructions. Our early experiments show that LLaSM demonstrates a more convenient and natural way for humans to interact with artificial intelligence. Specifically, we also release a large Speech Instruction Following dataset LLaSM-Audio-Instructions. Code and demo are available at https://github.com/LinkSoul-AI/LLaSM and https://huggingface.co/spaces/LinkSoul/LLaSM. The LLaSM-Audio-Instructions dataset is available at https://huggingface.co/datasets/LinkSoul/LLaSM-Audio-Instructions.