 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoila: Voice-Language Foundation Models for Real-Time Autonomous Interaction and Voice Role-Play
May 05, 2025A voice AI agent that blends seamlessly into daily life would interact with humans in an autonomous, real-time, and emotionally expressive manner. Rather than merely reacting to commands, it would continuously listen, reason, and respond proactively, fostering fluid, dynamic, and emotionally resonant interactions. We introduce Voila, a family of large voice-language foundation models that make a step towards this vision. Voila moves beyond traditional pipeline systems by adopting a new end-to-end architecture that enables full-duplex, low-latency conversations while preserving rich vocal nuances such as tone, rhythm, and emotion. It achieves a response latency of just 195 milliseconds, surpassing the average human response time. Its hierarchical multi-scale Transformer integrates the reasoning capabilities of large language models (LLMs) with powerful acoustic modeling, enabling natural, persona-aware voice generation -- where users can simply write text instructions to define the speaker's identity, tone, and other characteristics. Moreover, Voila supports over one million pre-built voices and efficient customization of new ones from brief audio samples as short as 10 seconds. Beyond spoken dialogue, Voila is designed as a unified model for a wide range of voice-based applications, including automatic speech recognition (ASR), Text-to-Speech (TTS), and, with minimal adaptation, multilingual speech translation. Voila is fully open-sourced to support open research and accelerate progress toward next-generation human-machine interactions.
AutoAgents: A Framework for Automatic Agent Generation
Oct 15, 2023



Large language models (LLMs) have enabled remarkable advances in automated task-solving with multi-agent systems. However, most existing LLM-based multi-agent approaches rely on predefined agents to handle simple tasks, limiting the adaptability of multi-agent collaboration to different scenarios. Therefore, we introduce AutoAgents, an innovative framework that adaptively generates and coordinates multiple specialized agents to build an AI team according to different tasks. Specifically, AutoAgents couples the relationship between tasks and roles by dynamically generating multiple required agents based on task content and planning solutions for the current task based on the generated expert agents. Multiple specialized agents collaborate with each other to efficiently accomplish tasks. Concurrently, an observer role is incorporated into the framework to reflect on the designated plans and agents' responses and improve upon them. Our experiments on various benchmarks demonstrate that AutoAgents generates more coherent and accurate solutions than the existing multi-agent methods. This underscores the significance of assigning different roles to different tasks and of team cooperation, offering new perspectives for tackling complex tasks. The repository of this project is available at https://github.com/Link-AGI/AutoAgents.
LLaSM: Large Language and Speech Model
Sep 16, 2023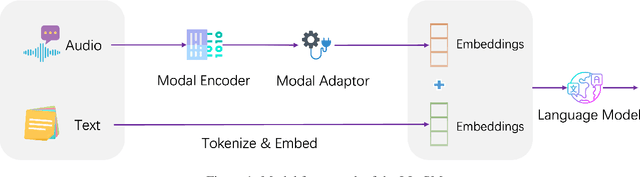
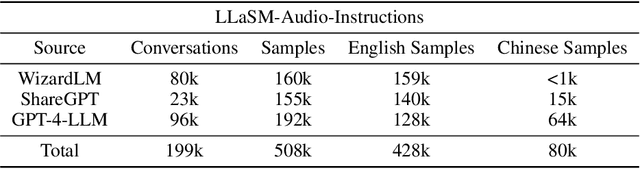
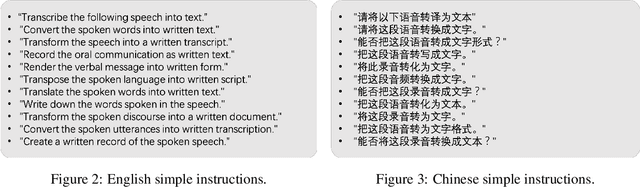

Multi-modal large language models have garnered significant interest recently. Though, most of the works focus on vision-language multi-modal models providing strong capabilities in following vision-and-language instructions. However, we claim that speech is also an important modality through which humans interact with the world. Hence, it is crucial for a general-purpose assistant to be able to follow multi-modal speech-and-language instructions. In this work, we propose Large Language and Speech Model (LLaSM). LLaSM is an end-to-end trained large multi-modal speech-language model with cross-modal conversational abilities, capable of following speech-and-language instructions. Our early experiments show that LLaSM demonstrates a more convenient and natural way for humans to interact with artificial intelligence. Specifically, we also release a large Speech Instruction Following dataset LLaSM-Audio-Instructions. Code and demo are available at https://github.com/LinkSoul-AI/LLaSM and https://huggingface.co/spaces/LinkSoul/LLaSM. The LLaSM-Audio-Instructions dataset is available at https://huggingface.co/datasets/LinkSoul/LLaSM-Audio-Instructions.
Chinese Open Instruction Generalist: A Preliminary Release
Apr 25, 2023



Instruction tuning is widely recognized as a key technique for building generalist language models, which has attracted the attention of researchers and the public with the release of InstructGPT~\citep{ouyang2022training} and ChatGPT\footnote{\url{https://chat.openai.com/}}. Despite impressive progress in English-oriented large-scale language models (LLMs), it is still under-explored whether English-based foundation LLMs can perform similarly on multilingual tasks compared to English tasks with well-designed instruction tuning and how we can construct the corpora needed for the tuning. To remedy this gap, we propose the project as an attempt to create a Chinese instruction dataset by various methods adapted to the intrinsic characteristics of 4 sub-tasks. We collect around 200k Chinese instruction tuning samples, which have been manually checked to guarantee high quality. We also summarize the existing English and Chinese instruction corpora and briefly describe some potential applications of the newly constructed Chinese instruction corpora. The resulting \textbf{C}hinese \textbf{O}pen \textbf{I}nstruction \textbf{G}eneralist (\textbf{COIG}) corpora are available in Huggingface\footnote{\url{https://huggingface.co/datasets/BAAI/COIG}} and Github\footnote{\url{https://github.com/BAAI-Zlab/COIG}}, and will be continuously updated.
Picking Up Quantization Steps for Compressed Image Classification
Apr 21, 2023The sensitivity of deep neural networks to compressed images hinders their usage in many real applications, which means classification networks may fail just after taking a screenshot and saving it as a compressed file. In this paper, we argue that neglected disposable coding parameters stored in compressed files could be picked up to reduce the sensitivity of deep neural networks to compressed images. Specifically, we resort to using one of the representative parameters, quantization steps, to facilitate image classification. Firstly, based on quantization steps, we propose a novel quantization aware confidence (QAC), which is utilized as sample weights to reduce the influence of quantization on network training. Secondly, we utilize quantization steps to alleviate the variance of feature distributions, where a quantization aware batch normalization (QABN) is proposed to replace batch normalization of classification networks. Extensive experiments show that the proposed method significantly improves the performance of classification networks on CIFAR-10, CIFAR-100, and ImageNet. The code is released on https://github.com/LiMaPKU/QSAM.git
1000x Faster Camera and Machine Vision with Ordinary Devices
Jan 23, 2022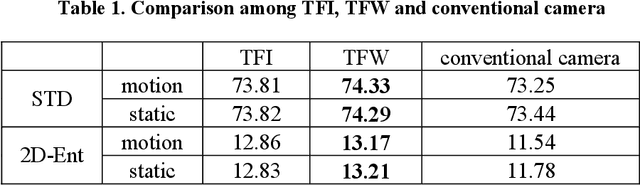
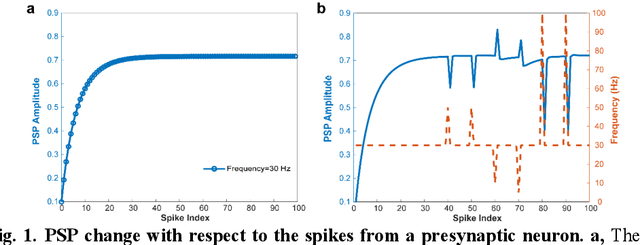


In digital cameras, we find a major limitation: the image and video form inherited from a film camera obstructs it from capturing the rapidly changing photonic world. Here, we present vidar, a bit sequence array where each bit represents whether the accumulation of photons has reached a threshold, to record and reconstruct the scene radiance at any moment. By employing only consumer-level CMOS sensors and integrated circuits, we have developed a vidar camera that is 1,000x faster than conventional cameras. By treating vidar as spike trains in biological vision, we have further developed a spiking neural network-based machine vision system that combines the speed of the machine and the mechanism of biological vision, achieving high-speed object detection and tracking 1,000x faster than human vision. We demonstrate the utility of the vidar camera and the super vision system in an assistant referee and target pointing system. Our study is expected to fundamentally revolutionize the image and video concepts and related industries, including photography, movies, and visual media, and to unseal a new spiking neural network-enabled speed-free machine vision era.
A Retina-inspired Sampling Method for Visual Texture Reconstruction
Jul 20, 2019

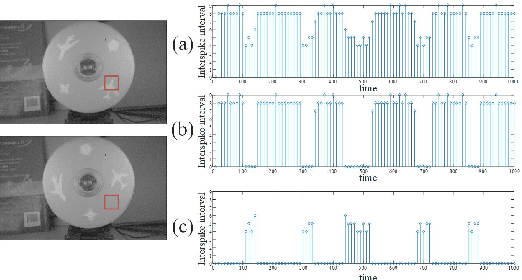

Conventional frame-based camera is not able to meet the demand of rapid reaction for real-time applications, while the emerging dynamic vision sensor (DVS) can realize high speed capturing for moving objects. However, to achieve visual texture reconstruction, DVS need extra information apart from the output spikes. This paper introduces a fovea-like sampling method inspired by the neuron signal processing in retina, which aims at visual texture reconstruction only taking advantage of the properties of spikes. In the proposed method, the pixels independently respond to the luminance changes with temporal asynchronous spikes. Analyzing the arrivals of spikes makes it possible to restore the luminance information, enabling reconstructing the natural scene for visualization. Three decoding methods of spike stream for texture reconstruction are proposed for high-speed motion and stationary scenes. Compared to conventional frame-based camera and DVS, our model can achieve better image quality and higher flexibility, which is capable of changing the way that demanding machine vision applications are built.