 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
Argumentation Computation with Large Language Models : A Benchmark Study
Dec 21, 2024



In recent years, large language models (LLMs) have made significant advancements in neuro-symbolic computing. However, the combination of LLM with argumentation computation remains an underexplored domain, despite its considerable potential for real-world applications requiring defeasible reasoning. In this paper, we aim to investigate the capability of LLMs in determining the extensions of various abstract argumentation semantics. To achieve this, we develop and curate a benchmark comprising diverse abstract argumentation frameworks, accompanied by detailed explanations of algorithms for computing extensions. Subsequently, we fine-tune LLMs on the proposed benchmark, focusing on two fundamental extension-solving tasks. As a comparative baseline, LLMs are evaluated using a chain-of-thought approach, where they struggle to accurately compute semantics. In the experiments, we demonstrate that the process explanation plays a crucial role in semantics computation learning. Models trained with explanations show superior generalization accuracy compared to those trained solely with question-answer pairs. Furthermore, by leveraging the self-explanation capabilities of LLMs, our approach provides detailed illustrations that mitigate the lack of transparency typically associated with neural networks. Our findings contribute to the broader understanding of LLMs' potential in argumentation computation, offering promising avenues for further research in this domain.
SGNet: Folding Symmetrical Protein Complex with Deep Learning
Mar 07, 2024Deep learning has made significant progress in protein structure prediction, advancing the development of computational biology. However, despite the high accuracy achieved in predicting single-chain structures, a significant number of large homo-oligomeric assemblies exhibit internal symmetry, posing a major challenge in structure determination. The performances of existing deep learning methods are limited since the symmetrical protein assembly usually has a long sequence, making structural computation infeasible. In addition, multiple identical subunits in symmetrical protein complex cause the issue of supervision ambiguity in label assignment, requiring a consistent structure modeling for the training. To tackle these problems, we propose a protein folding framework called SGNet to model protein-protein interactions in symmetrical assemblies. SGNet conducts feature extraction on a single subunit and generates the whole assembly using our proposed symmetry module, which largely mitigates computational problems caused by sequence length. Thanks to the elaborate design of modeling symmetry consistently, we can model all global symmetry types in quaternary protein structure prediction. Extensive experimental results on a benchmark of symmetrical protein complexes further demonstrate the effectiveness of our method.
CIF-Bench: A Chinese Instruction-Following Benchmark for Evaluating the Generalizability of Large Language Models
Feb 20, 2024
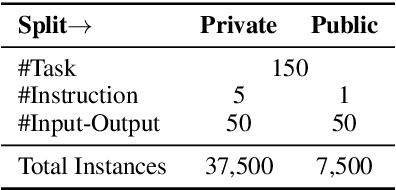
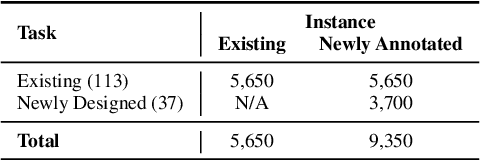

The advancement of large language models (LLMs) has enhanced the ability to generalize across a wide range of unseen natural language processing (NLP) tasks through instruction-following. Yet, their effectiveness often diminishes in low-resource languages like Chinese, exacerbated by biased evaluations from data leakage, casting doubt on their true generalizability to new linguistic territories. In response, we introduce the Chinese Instruction-Following Benchmark (CIF-Bench), designed to evaluate the zero-shot generalizability of LLMs to the Chinese language. CIF-Bench comprises 150 tasks and 15,000 input-output pairs, developed by native speakers to test complex reasoning and Chinese cultural nuances across 20 categories. To mitigate evaluation bias, we release only half of the dataset publicly, with the remainder kept private, and introduce diversified instructions to minimize score variance, totaling 45,000 data instances. Our evaluation of 28 selected LLMs reveals a noticeable performance gap, with the best model scoring only 52.9%, highlighting the limitations of LLMs in less familiar language and task contexts. This work aims to uncover the current limitations of LLMs in handling Chinese tasks, pushing towards the development of more culturally informed and linguistically diverse models with the released data and benchmark (https://yizhilll.github.io/CIF-Bench/).
Chinese Open Instruction Generalist: A Preliminary Release
Apr 25, 2023



Instruction tuning is widely recognized as a key technique for building generalist language models, which has attracted the attention of researchers and the public with the release of InstructGPT~\citep{ouyang2022training} and ChatGPT\footnote{\url{https://chat.openai.com/}}. Despite impressive progress in English-oriented large-scale language models (LLMs), it is still under-explored whether English-based foundation LLMs can perform similarly on multilingual tasks compared to English tasks with well-designed instruction tuning and how we can construct the corpora needed for the tuning. To remedy this gap, we propose the project as an attempt to create a Chinese instruction dataset by various methods adapted to the intrinsic characteristics of 4 sub-tasks. We collect around 200k Chinese instruction tuning samples, which have been manually checked to guarantee high quality. We also summarize the existing English and Chinese instruction corpora and briefly describe some potential applications of the newly constructed Chinese instruction corpora. The resulting \textbf{C}hinese \textbf{O}pen \textbf{I}nstruction \textbf{G}eneralist (\textbf{COIG}) corpora are available in Huggingface\footnote{\url{https://huggingface.co/datasets/BAAI/COIG}} and Github\footnote{\url{https://github.com/BAAI-Zlab/COIG}}, and will be continuously updated.
BPFNet: A Unified Framework for Bimodal Palmprint Alignment and Fusion
Oct 04, 2021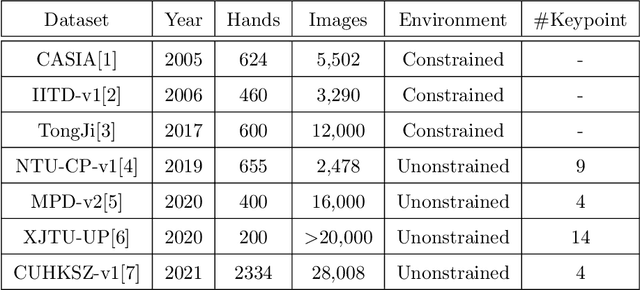
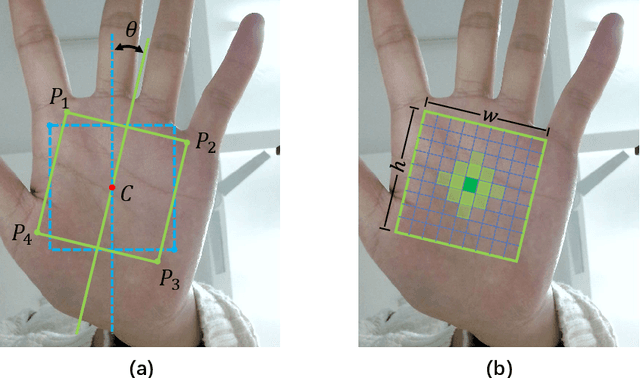
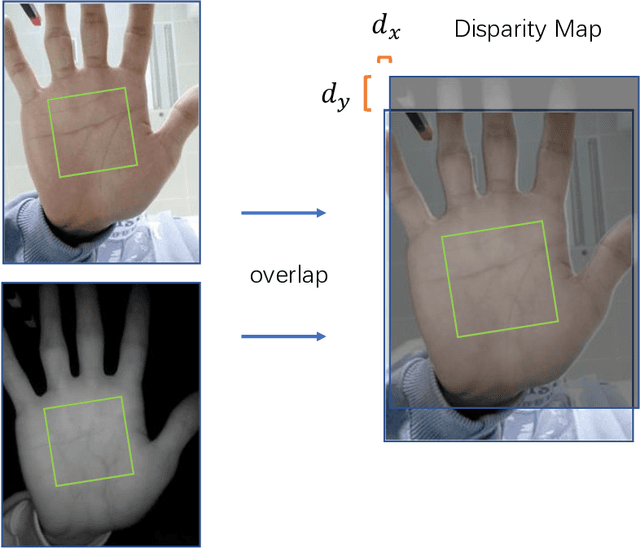
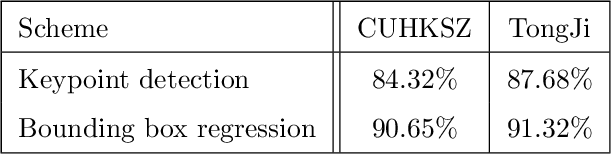
Bimodal palmprint recognition leverages palmprint and palm vein images simultaneously,which achieves high accuracy by multi-model information fusion and has strong anti-falsification property. In the recognition pipeline, the detection of palm and the alignment of region-of-interest (ROI) are two crucial steps for accurate matching. Most existing methods localize palm ROI by keypoint detection algorithms, however the intrinsic difficulties of keypoint detection tasks make the results unsatisfactory. Besides, the ROI alignment and fusion algorithms at image-level are not fully investigaged.To bridge the gap, in this paper, we propose Bimodal Palmprint Fusion Network (BPFNet) which focuses on ROI localization, alignment and bimodal image fusion.BPFNet is an end-to-end framework containing two subnets: The detection network directly regresses the palmprint ROIs based on bounding box prediction and conducts alignment by translation estimation.In the downstream,the bimodal fusion network implements bimodal ROI image fusion leveraging a novel proposed cross-modal selection scheme. To show the effectiveness of BPFNet,we carry out experiments on the large-scale touchless palmprint datasets CUHKSZ-v1 and TongJi and the proposed method achieves state-of-the-art performances.
Touchless Palmprint Recognition based on 3D Gabor Template and Block Feature Refinement
Mar 03, 2021



With the growing demand for hand hygiene and convenience of use, palmprint recognition with touchless manner made a great development recently, providing an effective solution for person identification. Despite many efforts that have been devoted to this area, it is still uncertain about the discriminative ability of the contactless palmprint, especially for large-scale datasets. To tackle the problem, in this paper, we build a large-scale touchless palmprint dataset containing 2334 palms from 1167 individuals. To our best knowledge, it is the largest contactless palmprint image benchmark ever collected with regard to the number of individuals and palms. Besides, we propose a novel deep learning framework for touchless palmprint recognition named 3DCPN (3D Convolution Palmprint recognition Network) which leverages 3D convolution to dynamically integrate multiple Gabor features. In 3DCPN, a novel variant of Gabor filter is embedded into the first layer for enhancement of curve feature extraction. With a well-designed ensemble scheme,low-level 3D features are then convolved to extract high-level features. Finally on the top, we set a region-based loss function to strengthen the discriminative ability of both global and local descriptors. To demonstrate the superiority of our method, extensive experiments are conducted on our dataset and other popular databases TongJi and IITD, where the results show the proposed 3DCPN achieves state-of-the-art or comparable performances.
Auto-MVCNN: Neural Architecture Search for Multi-view 3D Shape Recognition
Dec 10, 2020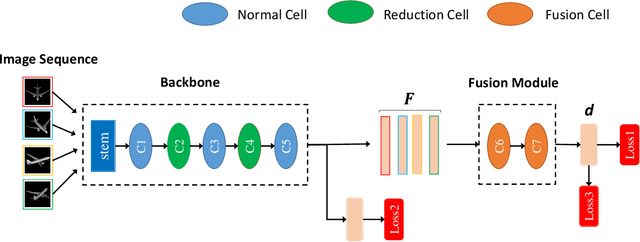
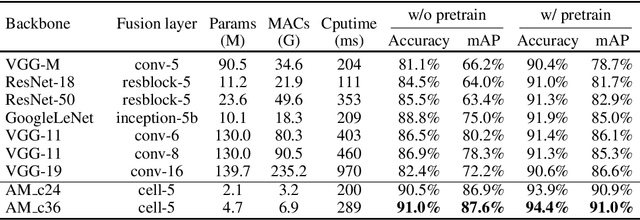
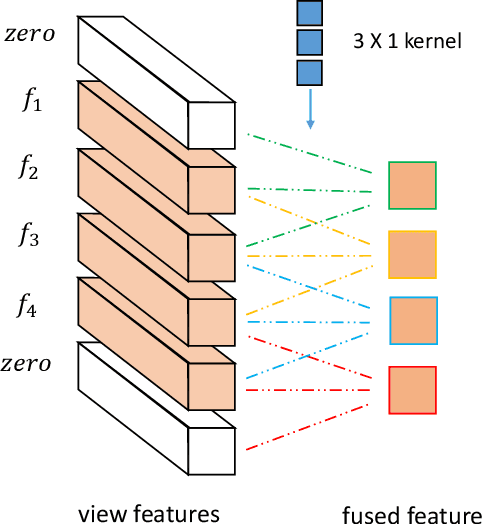
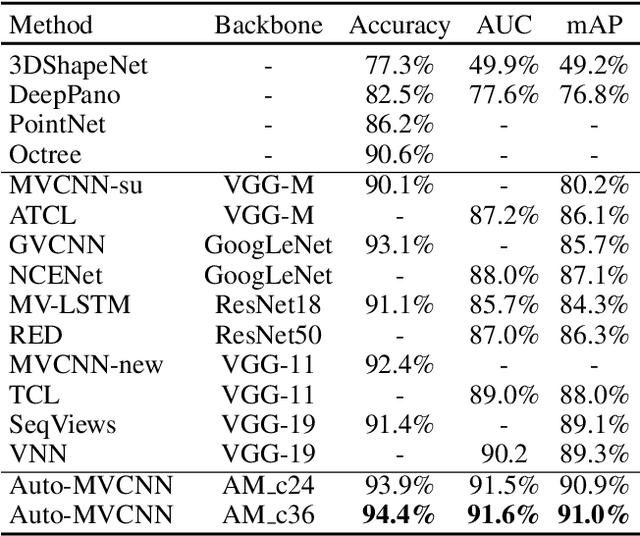
In 3D shape recognition, multi-view based methods leverage human's perspective to analyze 3D shapes and have achieved significant outcomes. Most existing research works in deep learning adopt handcrafted networks as backbones due to their high capacity of feature extraction, and also benefit from ImageNet pretraining. However, whether these network architectures are suitable for 3D analysis or not remains unclear. In this paper, we propose a neural architecture search method named Auto-MVCNN which is particularly designed for optimizing architecture in multi-view 3D shape recognition. Auto-MVCNN extends gradient-based frameworks to process multi-view images, by automatically searching the fusion cell to explore intrinsic correlation among view features. Moreover, we develop an end-to-end scheme to enhance retrieval performance through the trade-off parameter search. Extensive experimental results show that the searched architectures significantly outperform manually designed counterparts in various aspects, and our method achieves state-of-the-art performance at the same time.
Gram Regularization for Multi-view 3D Shape Retrieval
Nov 16, 2020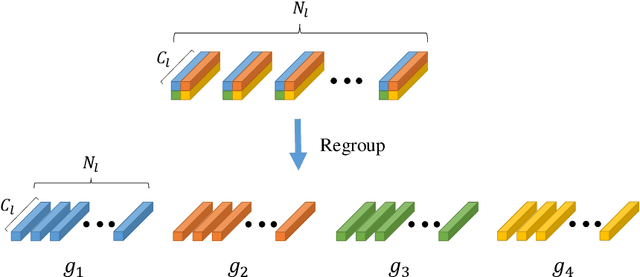

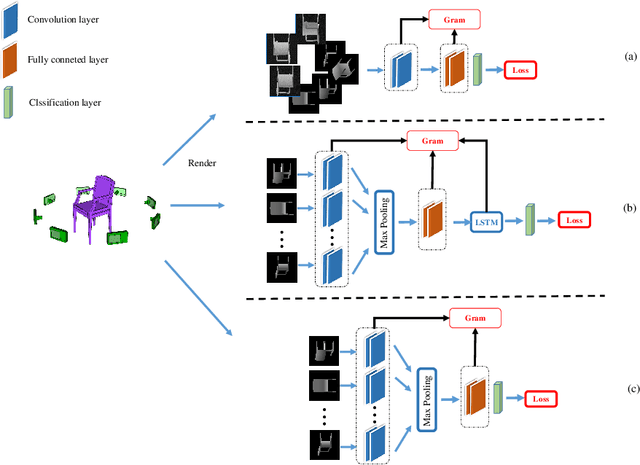

How to obtain the desirable representation of a 3D shape is a key challenge in 3D shape retrieval task. Most existing 3D shape retrieval methods focus on capturing shape representation with different neural network architectures, while the learning ability of each layer in the network is neglected. A common and tough issue that limits the capacity of the network is overfitting. To tackle this, L2 regularization is applied widely in existing deep learning frameworks. However,the effect on the generalization ability with L2 regularization is limited as it only controls large value in parameters. To make up the gap, in this paper, we propose a novel regularization term called Gram regularization which reinforces the learning ability of the network by encouraging the weight kernels to extract different information on the corresponding feature map. By forcing the variance between weight kernels to be large, the regularizer can help to extract discriminative features. The proposed Gram regularization is data independent and can converge stably and quickly without bells and whistles. Moreover, it can be easily plugged into existing off-the-shelf architectures. Extensive experimental results on the popular 3D object retrieval benchmark ModelNet demonstrate the effectiveness of our method.
Rethinking Loss Design for Large-scale 3D Shape Retrieval
Jun 03, 2019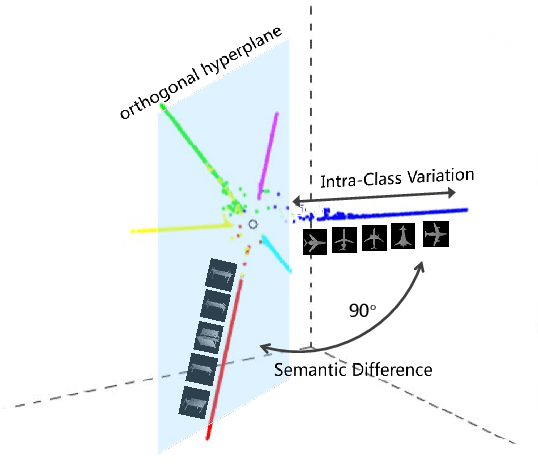
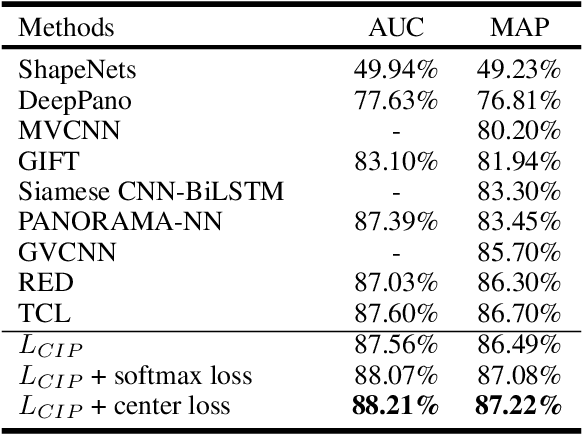
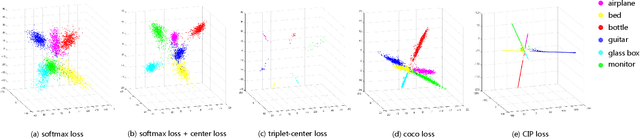
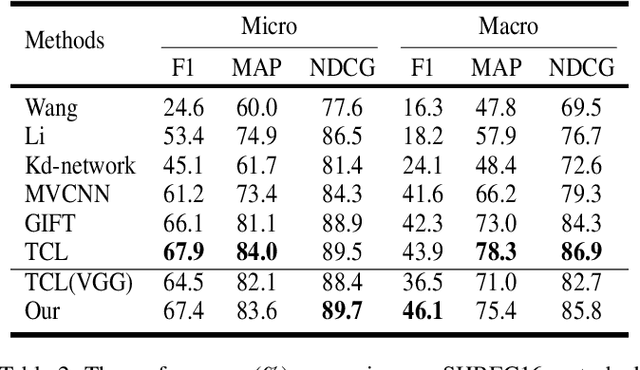
Learning discriminative shape representations is a crucial issue for large-scale 3D shape retrieval. In this paper, we propose the Collaborative Inner Product Loss (CIP Loss) to obtain ideal shape embedding that discriminative among different categories and clustered within the same class. Utilizing simple inner product operation, CIP loss explicitly enforces the features of the same class to be clustered in a linear subspace, while inter-class subspaces are constrained to be at least orthogonal. Compared to previous metric loss functions, CIP loss could provide more clear geometric interpretation for the embedding than Euclidean margin, and is easy to implement without normalization operation referring to cosine margin. Moreover, our proposed loss term can combine with other commonly used loss functions and can be easily plugged into existing off-the-shelf architectures. Extensive experiments conducted on the two public 3D object retrieval datasets, ModelNet and ShapeNetCore 55, demonstrate the effectiveness of our proposal, and our method has achieved state-of-the-art results on both datasets.