 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Relative Policy Optimization for Image Captioning
Mar 03, 2025Image captioning tasks usually use two-stage training to complete model optimization. The first stage uses cross-entropy as the loss function for optimization, and the second stage uses self-critical sequence training (SCST) for reinforcement learning optimization. However, the SCST algorithm has certain defects. SCST relies only on a single greedy decoding result as a baseline. If the model itself is not stable enough, the greedy decoding result may be relatively worst, which will lead to a high variance of advantage estimation, further leading to unstable policy updates. In addition, SCST only compares one sampling result with the greedy decoding result, and the generation diversity is limited, which may fall into a local optimum. In this paper, we propose using the latest Group Relative Policy Optimization (GRPO) reinforcement learning algorithm as an optimization solution for the second stage. GRPO generates multiple candidate captions for the input image and then continuously optimizes the model through intragroup comparison. By constraining the amplitude of policy updates and KL divergence, the stability of the model during training is greatly guaranteed. In addition, compared to SCST, which only samples one answer, GRPO samples and generates multiple answers. Multiple candidate answers in the group cover a wider solution space. Combined with KL divergence constraints, GRPO can improve diversity while ensuring model stability. The code for this article is available at https://github.com/liangxu-one/ms-models/tree/image_caption_grpo/research/arxiv_papers/Image_Caption_GRPO.
A Weight-aware-based Multi-source Unsupervised Domain Adaptation Method for Human Motion Intention Recognition
Apr 19, 2024Accurate recognition of human motion intention (HMI) is beneficial for exoskeleton robots to improve the wearing comfort level and achieve natural human-robot interaction. A classifier trained on labeled source subjects (domains) performs poorly on unlabeled target subject since the difference in individual motor characteristics. The unsupervised domain adaptation (UDA) method has become an effective way to this problem. However, the labeled data are collected from multiple source subjects that might be different not only from the target subject but also from each other. The current UDA methods for HMI recognition ignore the difference between each source subject, which reduces the classification accuracy. Therefore, this paper considers the differences between source subjects and develops a novel theory and algorithm for UDA to recognize HMI, where the margin disparity discrepancy (MDD) is extended to multi-source UDA theory and a novel weight-aware-based multi-source UDA algorithm (WMDD) is proposed. The source domain weight, which can be adjusted adaptively by the MDD between each source subject and target subject, is incorporated into UDA to measure the differences between source subjects. The developed multi-source UDA theory is theoretical and the generalization error on target subject is guaranteed. The theory can be transformed into an optimization problem for UDA, successfully bridging the gap between theory and algorithm. Moreover, a lightweight network is employed to guarantee the real-time of classification and the adversarial learning between feature generator and ensemble classifiers is utilized to further improve the generalization ability. The extensive experiments verify theoretical analysis and show that WMDD outperforms previous UDA methods on HMI recognition tasks.
BPFNet: A Unified Framework for Bimodal Palmprint Alignment and Fusion
Oct 04, 2021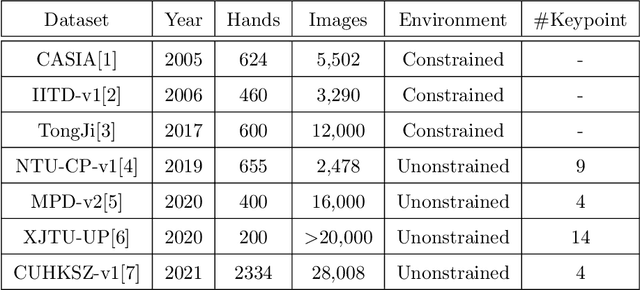
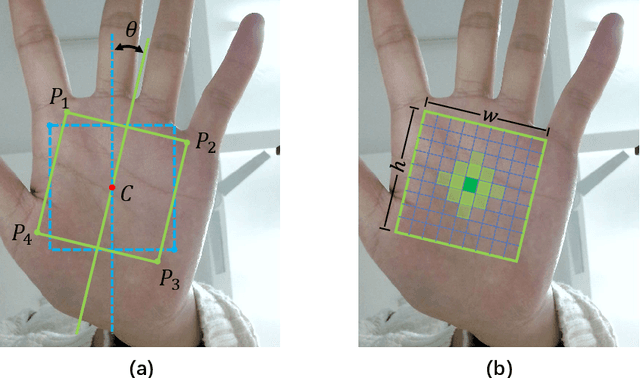
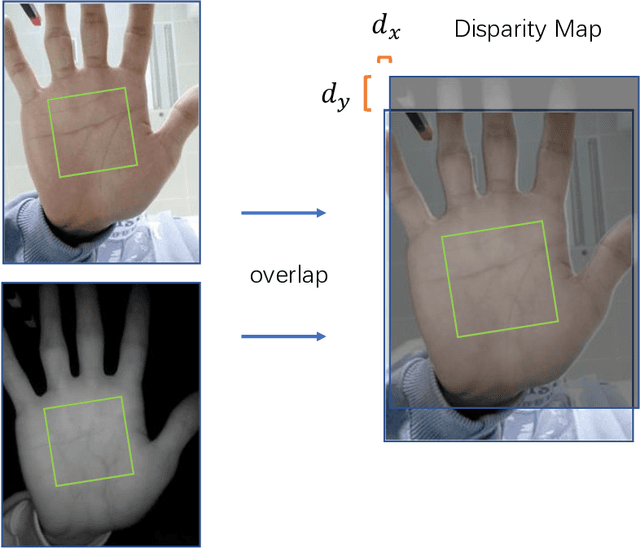
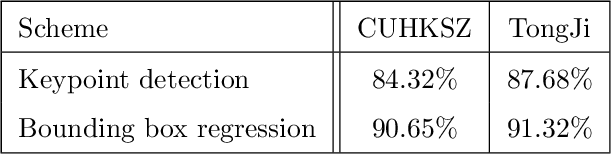
Bimodal palmprint recognition leverages palmprint and palm vein images simultaneously,which achieves high accuracy by multi-model information fusion and has strong anti-falsification property. In the recognition pipeline, the detection of palm and the alignment of region-of-interest (ROI) are two crucial steps for accurate matching. Most existing methods localize palm ROI by keypoint detection algorithms, however the intrinsic difficulties of keypoint detection tasks make the results unsatisfactory. Besides, the ROI alignment and fusion algorithms at image-level are not fully investigaged.To bridge the gap, in this paper, we propose Bimodal Palmprint Fusion Network (BPFNet) which focuses on ROI localization, alignment and bimodal image fusion.BPFNet is an end-to-end framework containing two subnets: The detection network directly regresses the palmprint ROIs based on bounding box prediction and conducts alignment by translation estimation.In the downstream,the bimodal fusion network implements bimodal ROI image fusion leveraging a novel proposed cross-modal selection scheme. To show the effectiveness of BPFNet,we carry out experiments on the large-scale touchless palmprint datasets CUHKSZ-v1 and TongJi and the proposed method achieves state-of-the-art performances.
Touchless Palmprint Recognition based on 3D Gabor Template and Block Feature Refinement
Mar 03, 2021



With the growing demand for hand hygiene and convenience of use, palmprint recognition with touchless manner made a great development recently, providing an effective solution for person identification. Despite many efforts that have been devoted to this area, it is still uncertain about the discriminative ability of the contactless palmprint, especially for large-scale datasets. To tackle the problem, in this paper, we build a large-scale touchless palmprint dataset containing 2334 palms from 1167 individuals. To our best knowledge, it is the largest contactless palmprint image benchmark ever collected with regard to the number of individuals and palms. Besides, we propose a novel deep learning framework for touchless palmprint recognition named 3DCPN (3D Convolution Palmprint recognition Network) which leverages 3D convolution to dynamically integrate multiple Gabor features. In 3DCPN, a novel variant of Gabor filter is embedded into the first layer for enhancement of curve feature extraction. With a well-designed ensemble scheme,low-level 3D features are then convolved to extract high-level features. Finally on the top, we set a region-based loss function to strengthen the discriminative ability of both global and local descriptors. To demonstrate the superiority of our method, extensive experiments are conducted on our dataset and other popular databases TongJi and IITD, where the results show the proposed 3DCPN achieves state-of-the-art or comparable performances.
Cross-Modality Paired-Images Generation for RGB-Infrared Person Re-Identification
Feb 18, 2020



RGB-Infrared (IR) person re-identification is very challenging due to the large cross-modality variations between RGB and IR images. The key solution is to learn aligned features to the bridge RGB and IR modalities. However, due to the lack of correspondence labels between every pair of RGB and IR images, most methods try to alleviate the variations with set-level alignment by reducing the distance between the entire RGB and IR sets. However, this set-level alignment may lead to misalignment of some instances, which limits the performance for RGB-IR Re-ID. Different from existing methods, in this paper, we propose to generate cross-modality paired-images and perform both global set-level and fine-grained instance-level alignments. Our proposed method enjoys several merits. First, our method can perform set-level alignment by disentangling modality-specific and modality-invariant features. Compared with conventional methods, ours can explicitly remove the modality-specific features and the modality variation can be better reduced. Second, given cross-modality unpaired-images of a person, our method can generate cross-modality paired images from exchanged images. With them, we can directly perform instance-level alignment by minimizing distances of every pair of images. Extensive experimental results on two standard benchmarks demonstrate that the proposed model favourably against state-of-the-art methods. Especially, on SYSU-MM01 dataset, our model can achieve a gain of 9.2% and 7.7% in terms of Rank-1 and mAP. Code is available at https://github.com/wangguanan/JSIA-ReID.
Design and Implementation of Global Path Planning System for Unmanned Surface Vehicle among Multiple Task Points
Jul 21, 2018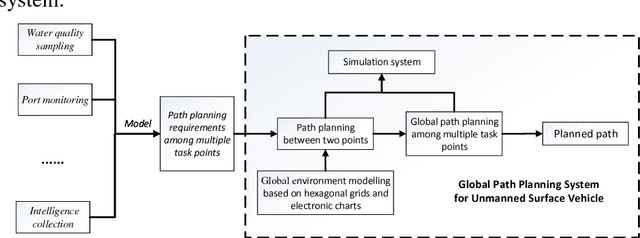
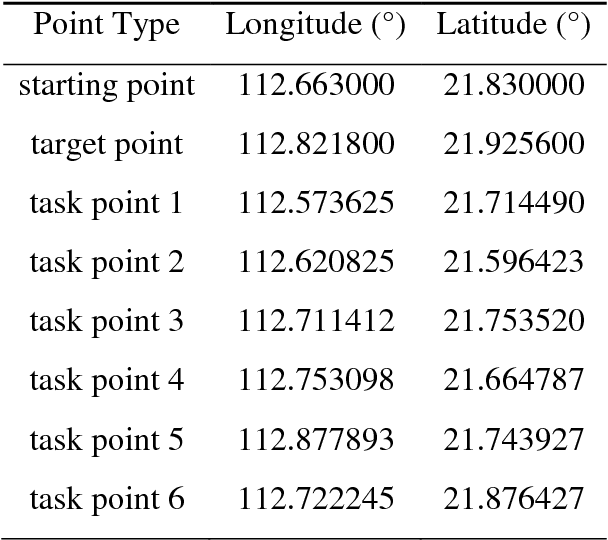
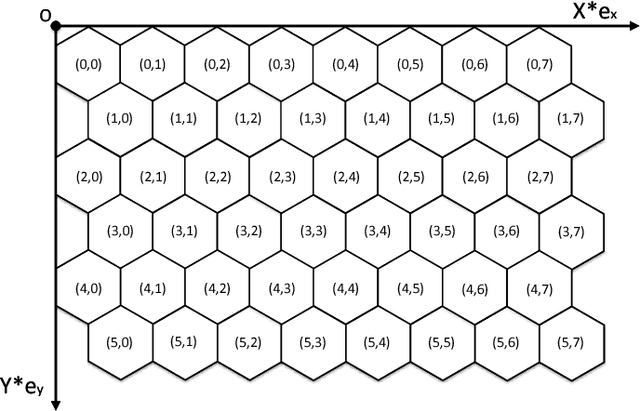

Global path planning is the key technology in the design of unmanned surface vehicles. This paper establishes global environment modelling based on electronic charts and hexagonal grids which are proved to be better than square grids in validity, safety and rapidity. Besides, we introduce Cube coordinate system to simplify hexagonal algorithms. Furthermore, we propose an improved A* algorithm to realize the path planning between two points. Based on that, we build the global path planning modelling for multiple task points and present an improved ant colony optimization to realize it accurately. The simulation results show that the global path planning system can plan an optimal path to tour multiple task points safely and quickly, which is superior to traditional methods in safety, rapidity and path length. Besides, the planned path can directly apply to actual applications of USVs.
* 28 pages, 15 figures
Research and Implementation of Global Path Planning for Unmanned Surface Vehicle Based on Electronic Chart
Feb 09, 2018
Unmanned Surface Vehicle (USV) is a new type of intelligent surface craft, and global path planning is the key technology of USV research, which can reflect the intelligent level of USV. In order to solve the problem of global path planning of USV, this paper proposes an improved A* algorithm for sailing cost optimization based on electronic charts. This paper uses the S-57 electronic chart to realize the establishment of the octree grid environment model, and proposes an improved A* algorithm based on sailing safety weight, pilot quantity and path curve smoothing to ensure the safety of the route, reduce the planning time, and improve path smoothness. The simulation results show that the environmental model construction method and the improved A* algorithm can generate safe and reasonable global path.
* 7 pages, 3 figures, conference