 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modality Paired-Images Generation for RGB-Infrared Person Re-Identification
Feb 18, 2020



RGB-Infrared (IR) person re-identification is very challenging due to the large cross-modality variations between RGB and IR images. The key solution is to learn aligned features to the bridge RGB and IR modalities. However, due to the lack of correspondence labels between every pair of RGB and IR images, most methods try to alleviate the variations with set-level alignment by reducing the distance between the entire RGB and IR sets. However, this set-level alignment may lead to misalignment of some instances, which limits the performance for RGB-IR Re-ID. Different from existing methods, in this paper, we propose to generate cross-modality paired-images and perform both global set-level and fine-grained instance-level alignments. Our proposed method enjoys several merits. First, our method can perform set-level alignment by disentangling modality-specific and modality-invariant features. Compared with conventional methods, ours can explicitly remove the modality-specific features and the modality variation can be better reduced. Second, given cross-modality unpaired-images of a person, our method can generate cross-modality paired images from exchanged images. With them, we can directly perform instance-level alignment by minimizing distances of every pair of images. Extensive experimental results on two standard benchmarks demonstrate that the proposed model favourably against state-of-the-art methods. Especially, on SYSU-MM01 dataset, our model can achieve a gain of 9.2% and 7.7% in terms of Rank-1 and mAP. Code is available at https://github.com/wangguanan/JSIA-ReID.
BARNet: Bilinear Attention Network with Adaptive Receptive Field for Surgical Instrument Segmentation
Jan 20, 2020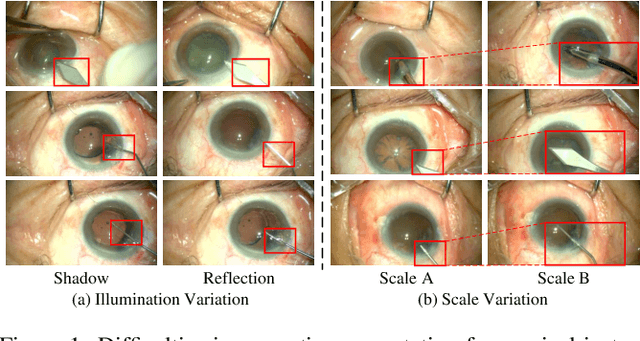
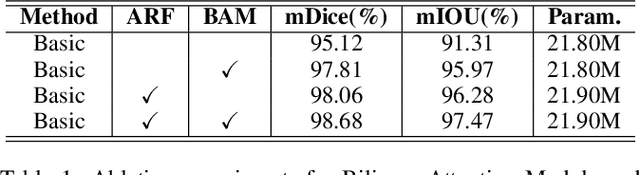
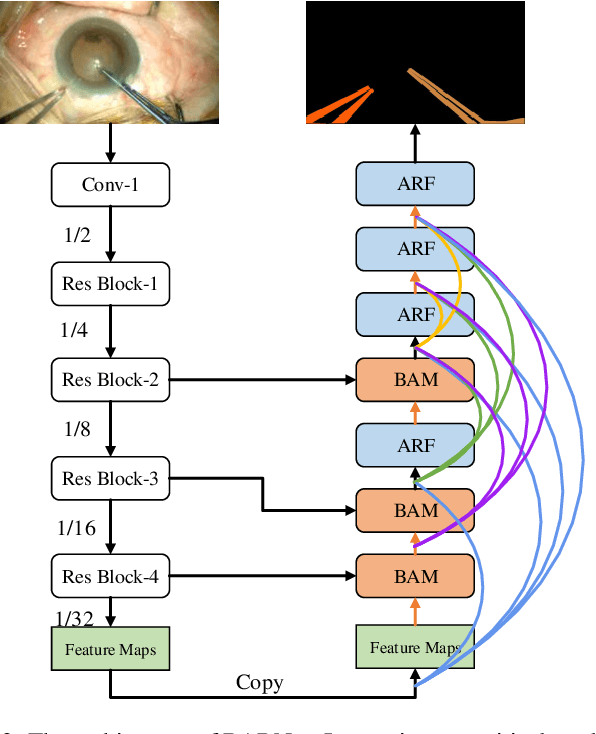
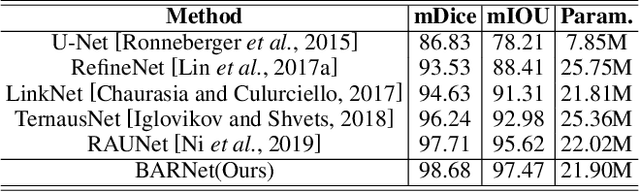
Surgical instrument segmentation is extremely important for computer-assisted surgery. Different from common object segmentation, it is more challenging due to the large illumination and scale variation caused by the special surgical scenes. In this paper, we propose a novel bilinear attention network with adaptive receptive field to solve these two challenges. For the illumination variation, the bilinear attention module can capture second-order statistics to encode global contexts and semantic dependencies between local pixels. With them, semantic features in challenging areas can be inferred from their neighbors and the distinction of various semantics can be boosted. For the scale variation, our adaptive receptive field module aggregates multi-scale features and automatically fuses them with different weights. Specifically, it encodes the semantic relationship between channels to emphasize feature maps with appropriate scales, changing the receptive field of subsequent convolutions. The proposed network achieves the best performance 97.47% mean IOU on Cata7 and comes first place on EndoVis 2017 by 10.10% IOU overtaking second-ranking method.