 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Oriented Learning for Automatic EEG Denoising
Sep 18, 2025Electroencephalography (EEG) denoising methods typically depend on manual intervention or clean reference signals. This work introduces a task-oriented learning framework for automatic EEG denoising that uses only task labels without clean reference signals. EEG recordings are first decomposed into components based on blind source separation (BSS) techniques. Then, a learning-based selector assigns a retention probability to each component, and the denoised signal is reconstructed as a probability-weighted combination. A downstream proxy-task model evaluates the reconstructed signal, with its task loss supervising the selector in a collaborative optimization scheme that relies solely on task labels, eliminating the need for clean EEG references. Experiments on three datasets spanning two paradigms and multiple noise conditions show consistent gains in both task performance (accuracy: $2.56\%\uparrow$) and standard signal-quality metrics (signal-to-noise-ratio: $0.82$\,dB\,$\uparrow$). Further analyses demonstrate that the task-oriented learning framework is algorithm-agnostic, as it accommodates diverse decomposition techniques and network backbones for both the selector and the proxy model. These promising results indicate that the proposed task-oriented learning framework is a practical EEG denoising solution with potential implications for neuroscience research and EEG-based interaction systems.
Parallels Between VLA Model Post-Training and Human Motor Learning: Progress, Challenges, and Trends
Jun 26, 2025Vision-language-action (VLA) models extend vision-language models (VLM) by integrating action generation modules for robotic manipulation. Leveraging strengths of VLM in vision perception and instruction understanding, VLA models exhibit promising generalization across diverse manipulation tasks. However, applications demanding high precision and accuracy reveal performance gaps without further adaptation. Evidence from multiple domains highlights the critical role of post-training to align foundational models with downstream applications, spurring extensive research on post-training VLA models. VLA model post-training aims to address the challenge of improving an embodiment's ability to interact with the environment for the given tasks, analogous to the process of humans motor skills acquisition. Accordingly, this paper reviews post-training strategies for VLA models through the lens of human motor learning, focusing on three dimensions: environments, embodiments, and tasks. A structured taxonomy is introduced aligned with human learning mechanisms: (1) enhancing environmental perception, (2) improving embodiment awareness, (3) deepening task comprehension, and (4) multi-component integration. Finally, key challenges and trends in post-training VLA models are identified, establishing a conceptual framework to guide future research. This work delivers both a comprehensive overview of current VLA model post-training methods from a human motor learning perspective and practical insights for VLA model development. (Project website: https://github.com/AoqunJin/Awesome-VLA-Post-Training)
VLA Model-Expert Collaboration for Bi-directional Manipulation Learning
Mar 06, 2025The emergence of vision-language-action (VLA) models has given rise to foundation models for robot manipulation. Although these models have achieved significant improvements, their generalization in multi-task manipulation remains limited. This study proposes a VLA model-expert collaboration framework that leverages a limited number of expert actions to enhance VLA model performance. This approach reduces expert workload relative to manual operation while simultaneously improving the reliability and generalization of VLA models. Furthermore, manipulation data collected during collaboration can further refine the VLA model, while human participants concurrently enhance their skills. This bi-directional learning loop boosts the overall performance of the collaboration system. Experimental results across various VLA models demonstrate the effectiveness of the proposed system in collaborative manipulation and learning, as evidenced by improved success rates across tasks. Additionally, validation using a brain-computer interface (BCI) indicates that the collaboration system enhances the efficiency of low-speed action systems by involving VLA model during manipulation. These promising results pave the way for advancing human-robot interaction in the era of foundation models for robotics. (Project website: https://aoqunjin.github.io/Expert-VLA/)
Learning Novel Skills from Language-Generated Demonstrations
Dec 12, 2024Current robot learning algorithms for acquiring novel skills often rely on demonstration datasets or environment interactions, resulting in high labor costs and potential safety risks. To address these challenges, this study proposes a skill-learning framework that enables robots to acquire novel skills from natural language instructions. The proposed pipeline leverages vision-language models to generate demonstration videos of novel skills, which are processed by an inverse dynamics model to extract actions from the unlabeled demonstrations. These actions are subsequently mapped to environmental contexts via imitation learning, enabling robots to learn new skills effectively. Experimental evaluations in the MetaWorld simulation environments demonstrate the pipeline's capability to generate high-fidelity and reliable demonstrations. Using the generated demonstrations, various skill learning algorithms achieve an accomplishment rate three times the original on novel tasks. These results highlight a novel approach to robot learning, offering a foundation for the intuitive and intelligent acquisition of novel robotic skills.
CAS-GAN for Contrast-free Angiography Synthesis
Oct 11, 2024Iodinated contrast agents are widely utilized in numerous interventional procedures, yet posing substantial health risks to patients. This paper presents CAS-GAN, a novel GAN framework that serves as a ``virtual contrast agent" to synthesize X-ray angiographies via disentanglement representation learning and vessel semantic guidance, thereby reducing the reliance on iodinated agents during interventional procedures. Specifically, our approach disentangles X-ray angiographies into background and vessel components, leveraging medical prior knowledge. A specialized predictor then learns to map the interrelationships between these components. Additionally, a vessel semantic-guided generator and a corresponding loss function are introduced to enhance the visual fidelity of generated images. Experimental results on the XCAD dataset demonstrate the state-of-the-art performance of our CAS-GAN, achieving a FID of 5.94 and a MMD of 0.017. These promising results highlight CAS-GAN's potential for clinical applications.
SPIRONet: Spatial-Frequency Learning and Topological Channel Interaction Network for Vessel Segmentation
Jun 28, 2024
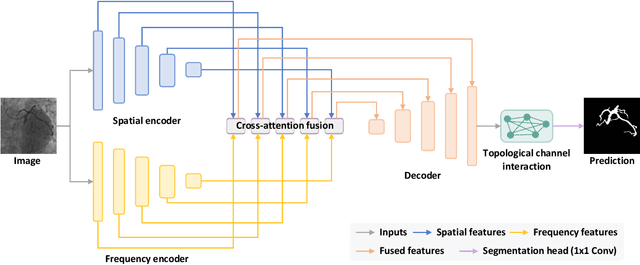

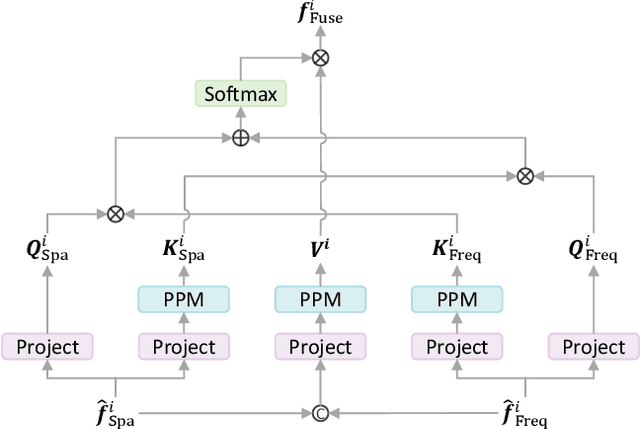
Automatic vessel segmentation is paramount for developing next-generation interventional navigation systems. However, current approaches suffer from suboptimal segmentation performances due to significant challenges in intraoperative images (i.e., low signal-to-noise ratio, small or slender vessels, and strong interference). In this paper, a novel spatial-frequency learning and topological channel interaction network (SPIRONet) is proposed to address the above issues. Specifically, dual encoders are utilized to comprehensively capture local spatial and global frequency vessel features. Then, a cross-attention fusion module is introduced to effectively fuse spatial and frequency features, thereby enhancing feature discriminability. Furthermore, a topological channel interaction module is designed to filter out task-irrelevant responses based on graph neural networks. Extensive experimental results on several challenging datasets (CADSA, CAXF, DCA1, and XCAD) demonstrate state-of-the-art performances of our method. Moreover, the inference speed of SPIRONet is 21 FPS with a 512x512 input size, surpassing clinical real-time requirements (6~12FPS). These promising outcomes indicate SPIRONet's potential for integration into vascular interventional navigation systems. Code is available at https://github.com/Dxhuang-CASIA/SPIRONet.
MOSformer: Momentum encoder-based inter-slice fusion transformer for medical image segmentation
Jan 22, 2024Medical image segmentation takes an important position in various clinical applications. Deep learning has emerged as the predominant solution for automated segmentation of volumetric medical images. 2.5D-based segmentation models bridge computational efficiency of 2D-based models and spatial perception capabilities of 3D-based models. However, prevailing 2.5D-based models often treat each slice equally, failing to effectively learn and exploit inter-slice information, resulting in suboptimal segmentation performances. In this paper, a novel Momentum encoder-based inter-slice fusion transformer (MOSformer) is proposed to overcome this issue by leveraging inter-slice information at multi-scale feature maps extracted by different encoders. Specifically, dual encoders are employed to enhance feature distinguishability among different slices. One of the encoders is moving-averaged to maintain the consistency of slice representations. Moreover, an IF-Swin transformer module is developed to fuse inter-slice multi-scale features. The MOSformer is evaluated on three benchmark datasets (Synapse, ACDC, and AMOS), establishing a new state-of-the-art with 85.63%, 92.19%, and 85.43% of DSC, respectively. These promising results indicate its competitiveness in medical image segmentation. Codes and models of MOSformer will be made publicly available upon acceptance.
CROP: Conservative Reward for Model-based Offline Policy Optimization
Oct 26, 2023Offline reinforcement learning (RL) aims to optimize policy using collected data without online interactions. Model-based approaches are particularly appealing for addressing offline RL challenges due to their capability to mitigate the limitations of offline data through data generation using models. Prior research has demonstrated that introducing conservatism into the model or Q-function during policy optimization can effectively alleviate the prevalent distribution drift problem in offline RL. However, the investigation into the impacts of conservatism in reward estimation is still lacking. This paper proposes a novel model-based offline RL algorithm, Conservative Reward for model-based Offline Policy optimization (CROP), which conservatively estimates the reward in model training. To achieve a conservative reward estimation, CROP simultaneously minimizes the estimation error and the reward of random actions. Theoretical analysis shows that this conservative reward mechanism leads to a conservative policy evaluation and helps mitigate distribution drift. Experiments on D4RL benchmarks showcase that the performance of CROP is comparable to the state-of-the-art baselines. Notably, CROP establishes an innovative connection between offline and online RL, highlighting that offline RL problems can be tackled by adopting online RL techniques to the empirical Markov decision process trained with a conservative reward. The source code is available with https://github.com/G0K0URURI/CROP.git.
DOMAIN: MilDly COnservative Model-BAsed OfflINe Reinforcement Learning
Sep 16, 2023Model-based reinforcement learning (RL), which learns environment model from offline dataset and generates more out-of-distribution model data, has become an effective approach to the problem of distribution shift in offline RL. Due to the gap between the learned and actual environment, conservatism should be incorporated into the algorithm to balance accurate offline data and imprecise model data. The conservatism of current algorithms mostly relies on model uncertainty estimation. However, uncertainty estimation is unreliable and leads to poor performance in certain scenarios, and the previous methods ignore differences between the model data, which brings great conservatism. Therefore, this paper proposes a milDly cOnservative Model-bAsed offlINe RL algorithm (DOMAIN) without estimating model uncertainty to address the above issues. DOMAIN introduces adaptive sampling distribution of model samples, which can adaptively adjust the model data penalty. In this paper, we theoretically demonstrate that the Q value learned by the DOMAIN outside the region is a lower bound of the true Q value, the DOMAIN is less conservative than previous model-based offline RL algorithms and has the guarantee of security policy improvement. The results of extensive experiments show that DOMAIN outperforms prior RL algorithms on the D4RL dataset benchmark, and achieves better performance than other RL algorithms on tasks that require generalization.
CASOG: Conservative Actor-critic with SmOoth Gradient for Skill Learning in Robot-Assisted Intervention
Apr 19, 2023



Robot-assisted intervention has shown reduced radiation exposure to physicians and improved precision in clinical trials. However, existing vascular robotic systems follow master-slave control mode and entirely rely on manual commands. This paper proposes a novel offline reinforcement learning algorithm, Conservative Actor-critic with SmOoth Gradient (CASOG), to learn manipulation skills from human demonstrations on vascular robotic systems. The proposed algorithm conservatively estimates Q-function and smooths gradients of convolution layers to deal with distribution shift and overfitting issues. Furthermore, to focus on complex manipulations, transitions with larger temporal-difference error are sampled with higher probability. Comparative experiments in a pre-clinical environment demonstrate that CASOG can deliver guidewire to the target at a success rate of 94.00\% and mean backward steps of 14.07, performing closer to humans and better than prior offline reinforcement learning methods. These results indicate that the proposed algorithm is promising to improve the autonomy of vascular robotic systems.