 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPIRONet: Spatial-Frequency Learning and Topological Channel Interaction Network for Vessel Segmentation
Jun 28, 2024
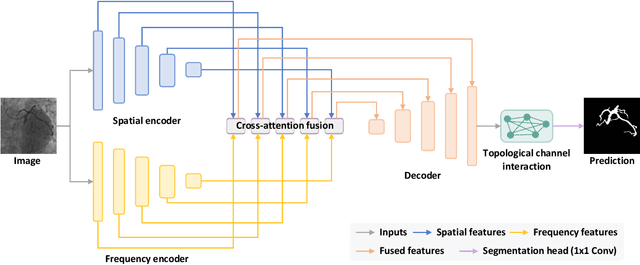

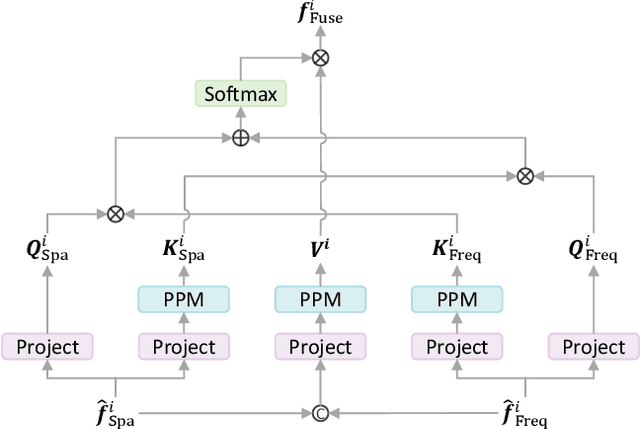
Automatic vessel segmentation is paramount for developing next-generation interventional navigation systems. However, current approaches suffer from suboptimal segmentation performances due to significant challenges in intraoperative images (i.e., low signal-to-noise ratio, small or slender vessels, and strong interference). In this paper, a novel spatial-frequency learning and topological channel interaction network (SPIRONet) is proposed to address the above issues. Specifically, dual encoders are utilized to comprehensively capture local spatial and global frequency vessel features. Then, a cross-attention fusion module is introduced to effectively fuse spatial and frequency features, thereby enhancing feature discriminability. Furthermore, a topological channel interaction module is designed to filter out task-irrelevant responses based on graph neural networks. Extensive experimental results on several challenging datasets (CADSA, CAXF, DCA1, and XCAD) demonstrate state-of-the-art performances of our method. Moreover, the inference speed of SPIRONet is 21 FPS with a 512x512 input size, surpassing clinical real-time requirements (6~12FPS). These promising outcomes indicate SPIRONet's potential for integration into vascular interventional navigation systems. Code is available at https://github.com/Dxhuang-CASIA/SPIRONet.
CROP: Conservative Reward for Model-based Offline Policy Optimization
Oct 26, 2023Offline reinforcement learning (RL) aims to optimize policy using collected data without online interactions. Model-based approaches are particularly appealing for addressing offline RL challenges due to their capability to mitigate the limitations of offline data through data generation using models. Prior research has demonstrated that introducing conservatism into the model or Q-function during policy optimization can effectively alleviate the prevalent distribution drift problem in offline RL. However, the investigation into the impacts of conservatism in reward estimation is still lacking. This paper proposes a novel model-based offline RL algorithm, Conservative Reward for model-based Offline Policy optimization (CROP), which conservatively estimates the reward in model training. To achieve a conservative reward estimation, CROP simultaneously minimizes the estimation error and the reward of random actions. Theoretical analysis shows that this conservative reward mechanism leads to a conservative policy evaluation and helps mitigate distribution drift. Experiments on D4RL benchmarks showcase that the performance of CROP is comparable to the state-of-the-art baselines. Notably, CROP establishes an innovative connection between offline and online RL, highlighting that offline RL problems can be tackled by adopting online RL techniques to the empirical Markov decision process trained with a conservative reward. The source code is available with https://github.com/G0K0URURI/CROP.git.