 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPIRONet: Spatial-Frequency Learning and Topological Channel Interaction Network for Vessel Segmentation
Jun 28, 2024
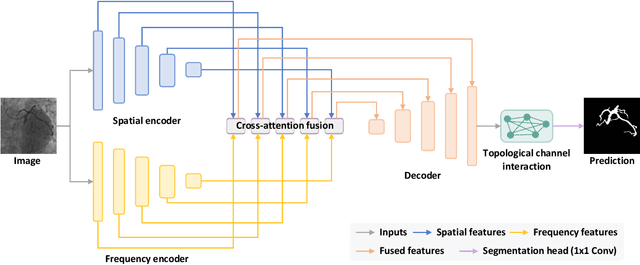

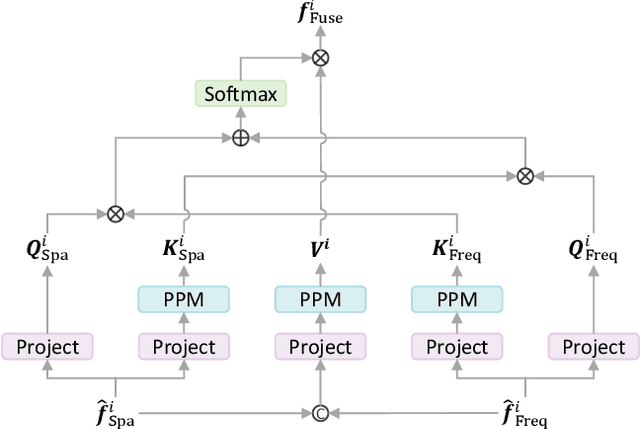
Automatic vessel segmentation is paramount for developing next-generation interventional navigation systems. However, current approaches suffer from suboptimal segmentation performances due to significant challenges in intraoperative images (i.e., low signal-to-noise ratio, small or slender vessels, and strong interference). In this paper, a novel spatial-frequency learning and topological channel interaction network (SPIRONet) is proposed to address the above issues. Specifically, dual encoders are utilized to comprehensively capture local spatial and global frequency vessel features. Then, a cross-attention fusion module is introduced to effectively fuse spatial and frequency features, thereby enhancing feature discriminability. Furthermore, a topological channel interaction module is designed to filter out task-irrelevant responses based on graph neural networks. Extensive experimental results on several challenging datasets (CADSA, CAXF, DCA1, and XCAD) demonstrate state-of-the-art performances of our method. Moreover, the inference speed of SPIRONet is 21 FPS with a 512x512 input size, surpassing clinical real-time requirements (6~12FPS). These promising outcomes indicate SPIRONet's potential for integration into vascular interventional navigation systems. Code is available at https://github.com/Dxhuang-CASIA/SPIRONet.
MOSformer: Momentum encoder-based inter-slice fusion transformer for medical image segmentation
Jan 22, 2024Medical image segmentation takes an important position in various clinical applications. Deep learning has emerged as the predominant solution for automated segmentation of volumetric medical images. 2.5D-based segmentation models bridge computational efficiency of 2D-based models and spatial perception capabilities of 3D-based models. However, prevailing 2.5D-based models often treat each slice equally, failing to effectively learn and exploit inter-slice information, resulting in suboptimal segmentation performances. In this paper, a novel Momentum encoder-based inter-slice fusion transformer (MOSformer) is proposed to overcome this issue by leveraging inter-slice information at multi-scale feature maps extracted by different encoders. Specifically, dual encoders are employed to enhance feature distinguishability among different slices. One of the encoders is moving-averaged to maintain the consistency of slice representations. Moreover, an IF-Swin transformer module is developed to fuse inter-slice multi-scale features. The MOSformer is evaluated on three benchmark datasets (Synapse, ACDC, and AMOS), establishing a new state-of-the-art with 85.63%, 92.19%, and 85.43% of DSC, respectively. These promising results indicate its competitiveness in medical image segmentation. Codes and models of MOSformer will be made publicly available upon acceptance.
CROP: Conservative Reward for Model-based Offline Policy Optimization
Oct 26, 2023Offline reinforcement learning (RL) aims to optimize policy using collected data without online interactions. Model-based approaches are particularly appealing for addressing offline RL challenges due to their capability to mitigate the limitations of offline data through data generation using models. Prior research has demonstrated that introducing conservatism into the model or Q-function during policy optimization can effectively alleviate the prevalent distribution drift problem in offline RL. However, the investigation into the impacts of conservatism in reward estimation is still lacking. This paper proposes a novel model-based offline RL algorithm, Conservative Reward for model-based Offline Policy optimization (CROP), which conservatively estimates the reward in model training. To achieve a conservative reward estimation, CROP simultaneously minimizes the estimation error and the reward of random actions. Theoretical analysis shows that this conservative reward mechanism leads to a conservative policy evaluation and helps mitigate distribution drift. Experiments on D4RL benchmarks showcase that the performance of CROP is comparable to the state-of-the-art baselines. Notably, CROP establishes an innovative connection between offline and online RL, highlighting that offline RL problems can be tackled by adopting online RL techniques to the empirical Markov decision process trained with a conservative reward. The source code is available with https://github.com/G0K0URURI/CROP.git.
DOMAIN: MilDly COnservative Model-BAsed OfflINe Reinforcement Learning
Sep 16, 2023Model-based reinforcement learning (RL), which learns environment model from offline dataset and generates more out-of-distribution model data, has become an effective approach to the problem of distribution shift in offline RL. Due to the gap between the learned and actual environment, conservatism should be incorporated into the algorithm to balance accurate offline data and imprecise model data. The conservatism of current algorithms mostly relies on model uncertainty estimation. However, uncertainty estimation is unreliable and leads to poor performance in certain scenarios, and the previous methods ignore differences between the model data, which brings great conservatism. Therefore, this paper proposes a milDly cOnservative Model-bAsed offlINe RL algorithm (DOMAIN) without estimating model uncertainty to address the above issues. DOMAIN introduces adaptive sampling distribution of model samples, which can adaptively adjust the model data penalty. In this paper, we theoretically demonstrate that the Q value learned by the DOMAIN outside the region is a lower bound of the true Q value, the DOMAIN is less conservative than previous model-based offline RL algorithms and has the guarantee of security policy improvement. The results of extensive experiments show that DOMAIN outperforms prior RL algorithms on the D4RL dataset benchmark, and achieves better performance than other RL algorithms on tasks that require generalization.
CASOG: Conservative Actor-critic with SmOoth Gradient for Skill Learning in Robot-Assisted Intervention
Apr 19, 2023



Robot-assisted intervention has shown reduced radiation exposure to physicians and improved precision in clinical trials. However, existing vascular robotic systems follow master-slave control mode and entirely rely on manual commands. This paper proposes a novel offline reinforcement learning algorithm, Conservative Actor-critic with SmOoth Gradient (CASOG), to learn manipulation skills from human demonstrations on vascular robotic systems. The proposed algorithm conservatively estimates Q-function and smooths gradients of convolution layers to deal with distribution shift and overfitting issues. Furthermore, to focus on complex manipulations, transitions with larger temporal-difference error are sampled with higher probability. Comparative experiments in a pre-clinical environment demonstrate that CASOG can deliver guidewire to the target at a success rate of 94.00\% and mean backward steps of 14.07, performing closer to humans and better than prior offline reinforcement learning methods. These results indicate that the proposed algorithm is promising to improve the autonomy of vascular robotic systems.