 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiRAS: A Hierarchical Multi-Agent Framework for Paper-to-Code Generation and Execution
Apr 20, 2026Recent advances in large language models have highlighted their potential to automate computational research, particularly reproducing experimental results. However, existing approaches still use fixed sequential agent pipelines with weak global coordination, which limits their robustness and overall performance. In this work, we propose Hierarchical Research Agent System (HiRAS), a hierarchical multi-agent framework for end-to-end experiment reproduction that employs supervisory manager agents to coordinate specialised agents across fine-grained stages. We also identify limitations in the reference-free evaluation of the Paper2Code benchmark and introduce Paper2Code-Extra (P2C-Ex), a refined protocol that incorporates repository-level information and better aligns with the original reference-based metric. We conduct extensive evaluation, validating the effectiveness and robustness of our proposed methods, and observing improvements, including >10\% relative performance gain beyond the previous state-of-the-art using open-source backbone models and significantly reduced hallucination in evaluation. Our work is available on GitHub: https://github.com/KOU-199024/HiRAS.
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Apr 06, 2024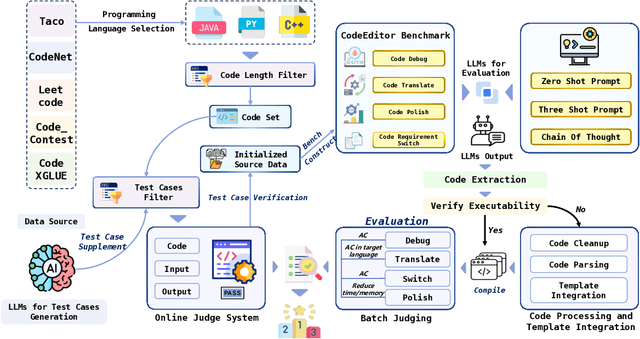
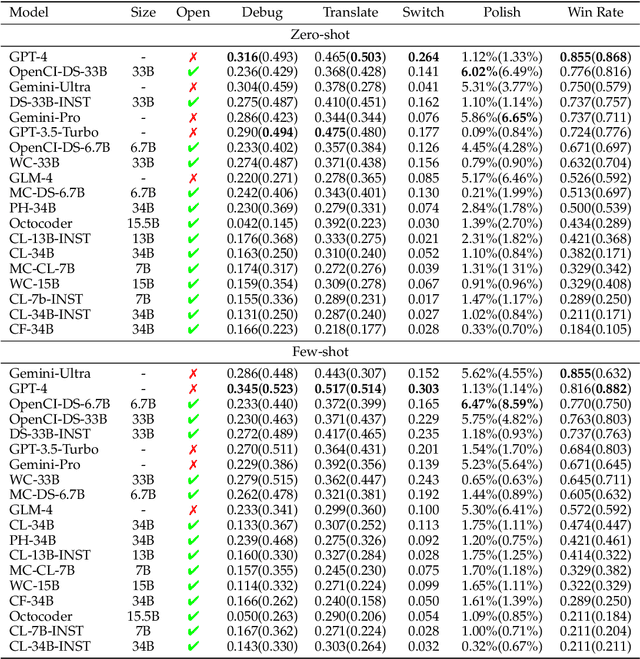
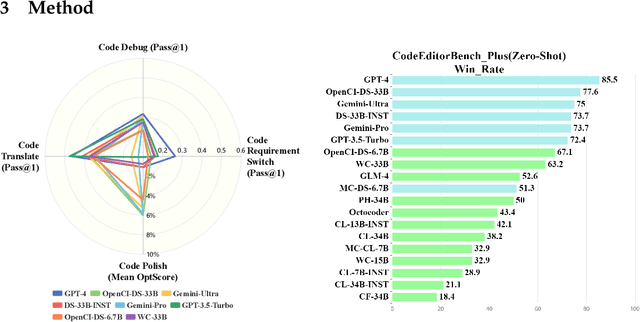

Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
CIF-Bench: A Chinese Instruction-Following Benchmark for Evaluating the Generalizability of Large Language Models
Feb 20, 2024
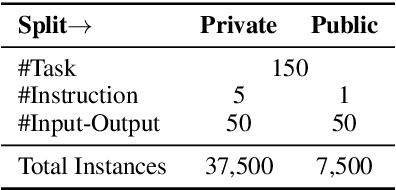
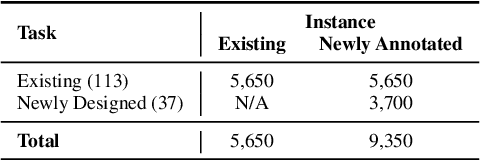

The advancement of large language models (LLMs) has enhanced the ability to generalize across a wide range of unseen natural language processing (NLP) tasks through instruction-following. Yet, their effectiveness often diminishes in low-resource languages like Chinese, exacerbated by biased evaluations from data leakage, casting doubt on their true generalizability to new linguistic territories. In response, we introduce the Chinese Instruction-Following Benchmark (CIF-Bench), designed to evaluate the zero-shot generalizability of LLMs to the Chinese language. CIF-Bench comprises 150 tasks and 15,000 input-output pairs, developed by native speakers to test complex reasoning and Chinese cultural nuances across 20 categories. To mitigate evaluation bias, we release only half of the dataset publicly, with the remainder kept private, and introduce diversified instructions to minimize score variance, totaling 45,000 data instances. Our evaluation of 28 selected LLMs reveals a noticeable performance gap, with the best model scoring only 52.9%, highlighting the limitations of LLMs in less familiar language and task contexts. This work aims to uncover the current limitations of LLMs in handling Chinese tasks, pushing towards the development of more culturally informed and linguistically diverse models with the released data and benchmark (https://yizhilll.github.io/CIF-Bench/).
LyricWhiz: Robust Multilingual Zero-shot Lyrics Transcription by Whispering to ChatGPT
Jul 07, 2023



We introduce LyricWhiz, a robust, multilingual, and zero-shot automatic lyrics transcription method achieving state-of-the-art performance on various lyrics transcription datasets, even in challenging genres such as rock and metal. Our novel, training-free approach utilizes Whisper, a weakly supervised robust speech recognition model, and GPT-4, today's most performant chat-based large language model. In the proposed method, Whisper functions as the "ear" by transcribing the audio, while GPT-4 serves as the "brain," acting as an annotator with a strong performance for contextualized output selection and correction. Our experiments show that LyricWhiz significantly reduces Word Error Rate compared to existing methods in English and can effectively transcribe lyrics across multiple languages. Furthermore, we use LyricWhiz to create the first publicly available, large-scale, multilingual lyrics transcription dataset with a CC-BY-NC-SA copyright license, based on MTG-Jamendo, and offer a human-annotated subset for noise level estimation and evaluation. We anticipate that our proposed method and dataset will advance the development of multilingual lyrics transcription, a challenging and emerging task.