 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrokking of Diffusion Models: Case Study on Modular Addition
Apr 20, 2026Despite their empirical success, how diffusion models generalize remains poorly understood from a mechanistic perspective. We demonstrate that diffusion models trained with flow-matching objectives exhibit grokking--delayed generalization after overfitting--on modular addition, enabling controlled analysis of their internal computations. We study this phenomenon across two levels of data regime. In a single-image regime, mechanistic dissection reveals that the model implements modular addition by composing periodic representations of individual operands. In a diverse-image regime with high intraclass variability, we find that the model leverages its iterative sampling process to partition the task into an arithmetic computation phase followed by a visual denoising phase, separated by a critical timestep threshold. Our work provides the mechanistic decomposition of algorithmic learning in diffusion models, revealing how these models bridge continuous pixel-space generation and discrete symbolic reasoning.
OmniGuide: Universal Guidance Fields for Enhancing Generalist Robot Policies
Mar 09, 2026Vision-language-action(VLA) models have shown great promise as generalist policies for a large range of relatively simple tasks. However, they demonstrate limited performance on more complex tasks, such as those requiring complex spatial or semantic understanding, manipulation in clutter, or precise manipulation. We propose OMNIGUIDE, a flexible framework that improves VLA performance on such tasks by leveraging arbitrary sources of guidance, such as 3D foundation models, semantic-reasoning VLMs, and human pose models. We show how many kinds of guidance can be naturally expressed as differentiable energy functions with task-specific attractors and repellers located in 3D space, that influence the sampling of VLA actions. In this way, OMNIGUIDE enables guidance sources with complementary task-relevant strengths to improve a VLA model's performance on challenging tasks. Extensive experiments in both simulation and real-world environments, across diverse sources of guidance, demonstrate that OMNIGUIDE enhances the performance of state-of-the-art generalist policies (e.g., $π_{0.5}$, GR00T N1.6) significantly across success and safety rates. Critically, our unified framework matches or surpasses the performance of prior methods designed to incorporate specific sources of guidance into VLA policies. Project Page: $\href{https://omniguide.github.io/}{this \; url}$
DECOR:Decomposition and Projection of Text Embeddings for Text-to-Image Customization
Dec 12, 2024Text-to-image (T2I) models can effectively capture the content or style of reference images to perform high-quality customization. A representative technique for this is fine-tuning using low-rank adaptations (LoRA), which enables efficient model customization with reference images. However, fine-tuning with a limited number of reference images often leads to overfitting, resulting in issues such as prompt misalignment or content leakage. These issues prevent the model from accurately following the input prompt or generating undesired objects during inference. To address this problem, we examine the text embeddings that guide the diffusion model during inference. This study decomposes the text embedding matrix and conducts a component analysis to understand the embedding space geometry and identify the cause of overfitting. Based on this, we propose DECOR, which projects text embeddings onto a vector space orthogonal to undesired token vectors, thereby reducing the influence of unwanted semantics in the text embeddings. Experimental results demonstrate that DECOR outperforms state-of-the-art customization models and achieves Pareto frontier performance across text and visual alignment evaluation metrics. Furthermore, it generates images more faithful to the input prompts, showcasing its effectiveness in addressing overfitting and enhancing text-to-image customization.
$\textit{Jump Your Steps}$: Optimizing Sampling Schedule of Discrete Diffusion Models
Oct 10, 2024



Diffusion models have seen notable success in continuous domains, leading to the development of discrete diffusion models (DDMs) for discrete variables. Despite recent advances, DDMs face the challenge of slow sampling speeds. While parallel sampling methods like $\tau$-leaping accelerate this process, they introduce $\textit{Compounding Decoding Error}$ (CDE), where discrepancies arise between the true distribution and the approximation from parallel token generation, leading to degraded sample quality. In this work, we present $\textit{Jump Your Steps}$ (JYS), a novel approach that optimizes the allocation of discrete sampling timesteps by minimizing CDE without extra computational cost. More precisely, we derive a practical upper bound on CDE and propose an efficient algorithm for searching for the optimal sampling schedule. Extensive experiments across image, music, and text generation show that JYS significantly improves sampling quality, establishing it as a versatile framework for enhancing DDM performance for fast sampling.
Geometric Remove-and-Retrain (GOAR): Coordinate-Invariant eXplainable AI Assessment
Jul 17, 2024Identifying the relevant input features that have a critical influence on the output results is indispensable for the development of explainable artificial intelligence (XAI). Remove-and-Retrain (ROAR) is a widely accepted approach for assessing the importance of individual pixels by measuring changes in accuracy following their removal and subsequent retraining of the modified dataset. However, we uncover notable limitations in pixel-perturbation strategies. When viewed from a geometric perspective, we discover that these metrics fail to discriminate between differences among feature attribution methods, thereby compromising the reliability of the evaluation. To address this challenge, we introduce an alternative feature-perturbation approach named Geometric Remove-and-Retrain (GOAR). Through a series of experiments with both synthetic and real datasets, we substantiate that GOAR transcends the limitations of pixel-centric metrics.
Upsample Guidance: Scale Up Diffusion Models without Training
Apr 02, 2024Diffusion models have demonstrated superior performance across various generative tasks including images, videos, and audio. However, they encounter difficulties in directly generating high-resolution samples. Previously proposed solutions to this issue involve modifying the architecture, further training, or partitioning the sampling process into multiple stages. These methods have the limitation of not being able to directly utilize pre-trained models as-is, requiring additional work. In this paper, we introduce upsample guidance, a technique that adapts pretrained diffusion model (e.g., $512^2$) to generate higher-resolution images (e.g., $1536^2$) by adding only a single term in the sampling process. Remarkably, this technique does not necessitate any additional training or relying on external models. We demonstrate that upsample guidance can be applied to various models, such as pixel-space, latent space, and video diffusion models. We also observed that the proper selection of guidance scale can improve image quality, fidelity, and prompt alignment.
Understanding the Latent Space of Diffusion Models through the Lens of Riemannian Geometry
Jul 24, 2023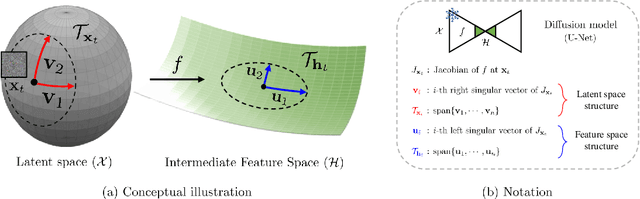
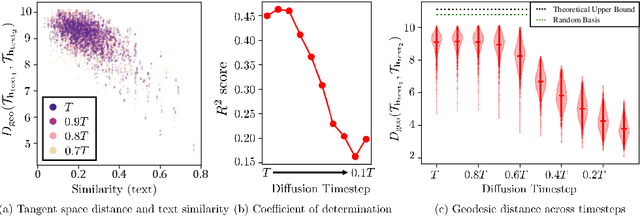

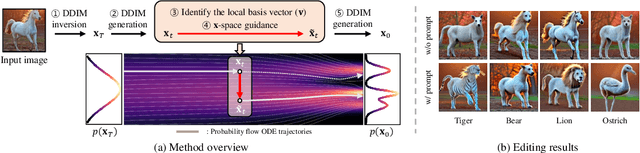
Despite the success of diffusion models (DMs), we still lack a thorough understanding of their latent space. To understand the latent space $\mathbf{x}_t \in \mathcal{X}$, we analyze them from a geometrical perspective. Specifically, we utilize the pullback metric to find the local latent basis in $\mathcal{X}$ and their corresponding local tangent basis in $\mathcal{H}$, the intermediate feature maps of DMs. The discovered latent basis enables unsupervised image editing capability through latent space traversal. We investigate the discovered structure from two perspectives. First, we examine how geometric structure evolves over diffusion timesteps. Through analysis, we show that 1) the model focuses on low-frequency components early in the generative process and attunes to high-frequency details later; 2) At early timesteps, different samples share similar tangent spaces; and 3) The simpler datasets that DMs trained on, the more consistent the tangent space for each timestep. Second, we investigate how the geometric structure changes based on text conditioning in Stable Diffusion. The results show that 1) similar prompts yield comparable tangent spaces; and 2) the model depends less on text conditions in later timesteps. To the best of our knowledge, this paper is the first to present image editing through $\mathbf{x}$-space traversal and provide thorough analyses of the latent structure of DMs.
Unsupervised Discovery of Semantic Latent Directions in Diffusion Models
Feb 24, 2023Despite the success of diffusion models (DMs), we still lack a thorough understanding of their latent space. While image editing with GANs builds upon latent space, DMs rely on editing the conditions such as text prompts. We present an unsupervised method to discover interpretable editing directions for the latent variables $\mathbf{x}_t \in \mathcal{X}$ of DMs. Our method adopts Riemannian geometry between $\mathcal{X}$ and the intermediate feature maps $\mathcal{H}$ of the U-Nets to provide a deep understanding over the geometrical structure of $\mathcal{X}$. The discovered semantic latent directions mostly yield disentangled attribute changes, and they are globally consistent across different samples. Furthermore, editing in earlier timesteps edits coarse attributes, while ones in later timesteps focus on high-frequency details. We define the curvedness of a line segment between samples to show that $\mathcal{X}$ is a curved manifold. Experiments on different baselines and datasets demonstrate the effectiveness of our method even on Stable Diffusion. Our source code will be publicly available for the future researchers.